MySQL是基于磁盘进行数据存储的关系型数据库, 所有的数据、索引等数据均以磁盘文件的方式存储, 在有需要时载入内存读取。 为了加快数据查询的效率, 通常会在一些字段上添加索引, 但是许多文档都会告诉我们, 不要添加太多的索引, 索引不要太长, 使用数字或者空字符串来代替NULL值, 为什么会有这些建议? 这些建议又是否正确? 答案都能够从MySQL数据的物理存储方式中找到。
1. InnoDB文件格式
由于InnoDB是MySQL使用最为广泛的存储引擎, 所以本篇博文基于InnoDB存储引擎来讨论其数据存储方式。
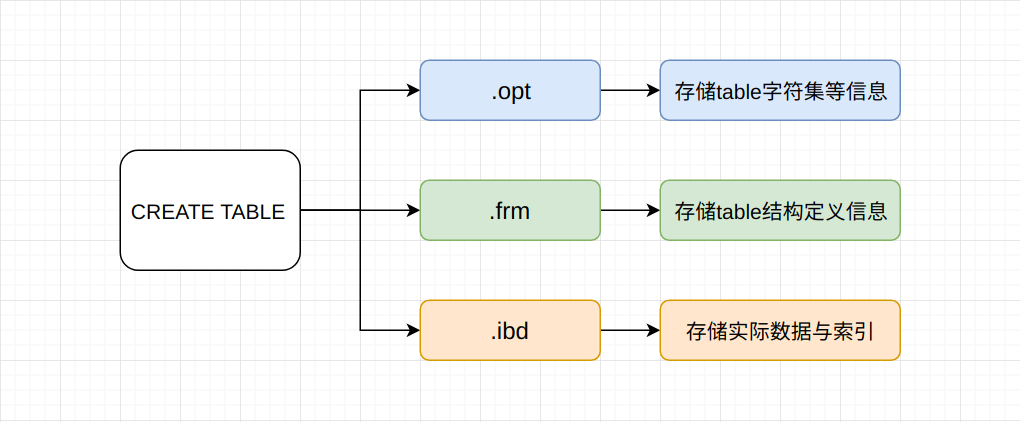
当我们创建一个table时, InnoDB会创建三个文件。 一个是表结构定义文件, 另一个为数据实际存储文件, 并且所有的索引也将存放在这个文件中。 最后一个文件保存该table所制定的字符集。
2. InnoDB行记录格式
当我们使用SQL查询一条或者是多条数据时, 数据将会以一行一行的方式返回, 而实际上数据在文件中也的确是使用行记录的方式进行存储的。
不同的InnoDB引擎版本可能有着不同的行记录格式来存放数据, 可以说, 行记录格式的变更将会直接影响到InnoDB的查询以及DML效率。 在MySQL 5.7版本中, 如果对某个table执行:
SHOW TABLE STATUS LIKE "table_name" G;
将会得到该table的一系列信息, 在这里, 我们只需要知道Row_format的值即可, 5.7将会返回Dynamic。
在官网上给出了不同格式的行记录格式之间的差别, 详细内容见官方文档:
https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html
在这里我们只需要知道Dynamic行记录格式在存储可变字符(Varchar)时, 与Compact行记录格式有着同样的表现即可。
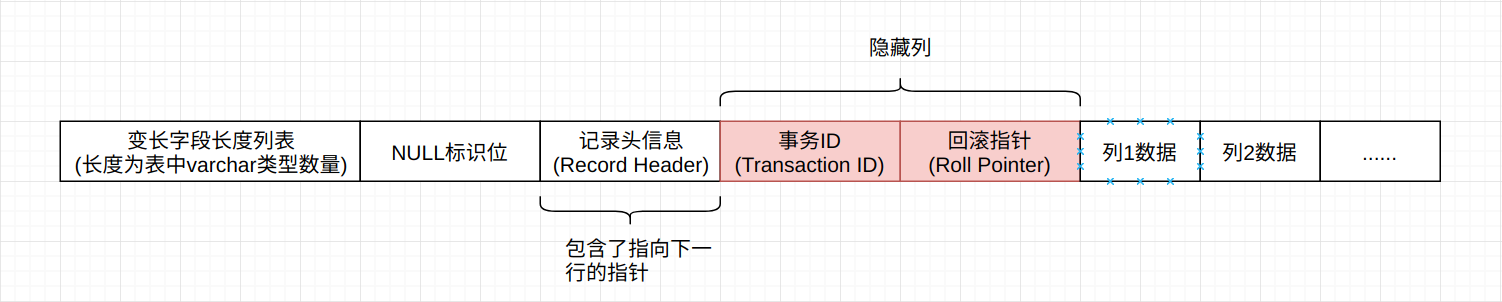
Compact行记录格式将以上图的方式保存在文件中, 需要注意的是, 如果一个table中没有任何的varchar类型, 那么变长字段长度列表将为空。
Compact行记录格式的首部是一个非NULL变长字段长度列表, 并且是按照列的顺序逆序放置的, 其长度表现为:
- 若列的长度小于255字节, 用1字节表示
- 若列的长度大于255字节, 用2字节表示
变长字段的长度最大不会超过2字节, 这是因为MySQL中VARCAHR类型的最大长度限制为65535。 变长字段之后的第二个部分为NULL标识位, 该位指示了该行数据中是否存在NULL值, 有则用1表示, 本质上是一个bitmap。
下面用一个实际的例子来具体分析Compact行记录格式的实际存储。
-- 创建database
CREATE SCHEMA `coco` DEFAULT CHARACTER SET latin1 ;
-- 创建table
CREATE TABLE one (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
nickname VARCHAR(10),
PRIMARY KEY (id),
KEY (nickname)
) ENGINE=InnoDB CHARSET=LATIN1;
-- 插入代表性数据
INSERT INTO one (name, nickname) VALUES ("a", "AAA");
INSERT INTO one (name, nickname) VALUES ("b", "BBB");
INSERT INTO one (name, nickname) VALUES ("c", NULL);
INSERT INTO one (name, nickname) VALUES ("d", "DDD");
INSERT INTO one (name, nickname) VALUES ("e", "");
INSERT INTO one (name, nickname) VALUES ("f", "FFF");
而后在/var/lib/mysql/coco中即可找到该表的.ibd文件了, 使用hexdump -C one.ibd对其进行16进制的数据解析并查看。 由于数据太长, 所以仅截取部分数据:
0000c070 73 75 70 72 65 6d 75 6d 03 01 00 00 00 10 00 1d |supremum........|
0000c080 80 00 00 01 00 00 00 08 d1 29 bd 00 00 01 35 01 |.........)....5.|
0000c090 10 61 41 41 41 03 01 00 00 00 18 00 1c 80 00 00 |.aAAA...........|
0000c0a0 02 00 00 00 08 d1 29 bd 00 00 01 35 01 1d 62 42 |......)....5..bB|
0000c0b0 42 42 01 02 00 00 20 00 1a 80 00 00 03 00 00 00 |BB.... .........|
0000c0c0 08 d1 29 bd 00 00 01 35 01 2a 63 03 01 00 00 00 |..)....5.*c.....|
0000c0d0 28 00 1d 80 00 00 04 00 00 00 08 d1 29 bd 00 00 |(...........)...|
0000c0e0 01 35 01 37 64 44 44 44 00 01 00 00 00 30 00 1a |.5.7dDDD.....0..|
0000c0f0 80 00 00 05 00 00 00 08 d1 29 bd 00 00 01 35 01 |.........)....5.|
0000c100 44 65 03 01 00 00 00 38 ff 66 80 00 00 06 00 00 |De.....8.f......|
0000c110 00 08 d1 29 bd 00 00 01 35 01 51 66 46 46 46 00 |...)....5.QfFFF.|
实际存储数据从0000c078开始, 使用Compact行记录格式对其进行整理:
03 01 /* 变长字段长度列表, 逆序, 第一行varchar数据为('a', 'AAA') */
00 /* NULL标识位, 该值表示该行未有NULL值的列 */
00 00 10 00 1d /* 记录头(Record Header)信息, 固定长度为5字节 */
80 00 00 01 /* Row ID, 这里即为该行数据的主键值(paimary key),长度为4 */
00 00 00 08 d1 29 /* Transaction ID, 即事务ID, 默认为6字节 */
bd 00 00 01 35 01 10 /* 回滚指针, 默认为7字节 */
61 /* 列1数据'a' */
41 41 41 /* 列2数据'AAA' */
第2行数据与第1行数据大同小异, 值得关注的是包含有NULL值以及空值的行, 即第3行和第5行, 首先来看第3行数据:
01 /* 由于该行中只有一列数据类型为varchar,并且非NULL, 所以列表长度为1 */
02 /* 02转换为2进制结果为10, 表示第二列数据为NULL(注意是逆序) */
00 00 20 00 1a /* 记录头(Record Header)信息, 固定长度为5字节 */
80 00 00 03 /* 第3行数据的主键id */
00 00 00 08 d1 29 /* Transaction ID, 即事务ID, 默认为6字节 */
bd 00 00 01 35 01 2a /* 回滚指针, 默认为7字节 */
63 /* 列1数据'c' */
可以非常明显的看到, NULL值并没有在文件中进行存储, 而是仅使用NULL标识位来标记某一列是否为NULL。 所以说, NULL值不会占据任何的物理存储空间, 相反, varchar类型的NULL值还会少占用变长字段长度列表空间。
再来看空字符串所在的第5行数据:
00 01 /* 表示第2列的varchar长度为0 */
00 /* 该行没有NULL值的列 */
00 00 30 00 1a /* 记录头(Record Header)信息, 固定长度为5字节 */
80 00 00 05 /* 第5行数据的主键id */
00 00 00 08 d1 29 /* Transaction ID, 即事务ID, 默认为6字节 */
bd 00 00 01 35 01 44 /* 回滚指针, 默认为7字节 */
65 /* 列1数据'e' */
可以看到, 空字符串和NULL值一样, 也不占用任何的磁盘存储空间。 只不过与NULL值不同的是, 在首部的变长字符长度列表中仍然占据存储空间, 但是值为0。
3. 数据的聚集索引组织方式
有些人将聚集索引(Cluster Index)理解成为主键, 或者是主键索引, 这是不准确的。 聚集索引并不是一种索引结构, 而是一种数据的组织方式, 用唯一且不为空的主键来对所有的数据进行组织。 主键, 是最为常见的聚集索引对外表现的形式。
聚集索引最大的特点就在于数据在逻辑上是一定是连续的, 但是在物理是并不一定连续。 比如我们常见的自增主键, 当我们对查询语句不做任何处理时, 默认就是按照主键的递增顺序返回的。
而辅助索引, 或者是二级索引, 是由程序员人为的在某些列上所添加的索引。 辅助索引所代表的数据在逻辑上不一定连续, 物理存储上也不一定连续。
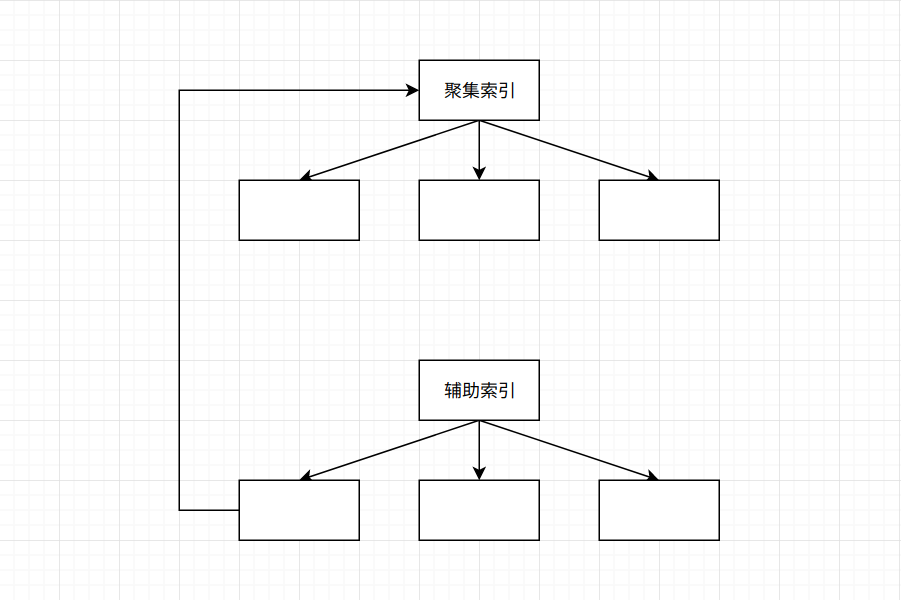
MySQL使用B+Tree来组织数据和索引(关于B+Tree的详细内容, 可见下方传送门), 在非叶子节点中保存着索引和指针, 在叶子节点保存着数据。 情况又分两种:
- 聚集索引的叶子节点保存着实际的数据,即一行完整的数据
- 辅助索引的叶子节点保存着该行数据的主键ID
那些有趣的数据结构与算法(04)–B-Tree与B+Tree
也就是说, 假设聚集索引和辅助索引的B+Tree树高均为3的话, 使用主键查询需要3次逻辑I/O。 而使用辅助索引则需要6次逻辑I/O才能找到该行数据。
还记得在上面的Compact行记录格式中的行记录头, 也就是Record Header信息吗? Record Header的最后两个字节表示下一行数据的偏移量, 其实这个就是B+Tree中的指针。 例如第一行的起始位置为c078, Record Header最后两个字节为001d, 加起来等于c095, 刚好是第二行的起始位置。
在上面的例子中, 我们创建了这样的一张表:
CREATE TABLE one (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
nickname VARCHAR(10),
PRIMARY KEY (id),
KEY (nickname)
) ENGINE=InnoDB CHARSET=LATIN1;
其中nickname字段被我们添加了辅助索引, 同样地, 可以使用.ibd文件来具体对其结构进行分析。 使用hexdump -C one.ibd解析文件并找到辅助索引开始的地方:
00010060 02 00 37 69 6e 66 69 6d 75 6d 00 07 00 0b 00 00 |..7infimum......|
00010070 73 75 70 72 65 6d 75 6d 03 00 00 00 10 00 0e 41 |supremum.......A|
00010080 41 41 80 00 00 01 03 00 00 00 18 00 18 42 42 42 |AA...........BBB|
00010090 80 00 00 02 01 00 00 20 00 19 80 00 00 03 03 00 |....... ........|
000100a0 00 00 28 00 19 44 44 44 80 00 00 04 00 00 00 00 |..(..DDD........|
000100b0 30 ff cc 80 00 00 05 03 00 00 00 38 ff b2 46 46 |0..........8..FF|
000100c0 46 80 00 00 06 00 00 00 00 00 00 00 00 00 00 00 |F...............|
000100d0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
索引数据从00010078的位置开始, 逐行进行分析即可:
03 /* 当前索引字段的长度 */
00 00 00 10 00 0e /* 不知道是啥 */
41 41 41 /* 索引值 */
80 00 00 01 /* 指向的主键id */
第2行与第1行基本类似, 现在来看看比较特殊的第3行与第5行。 第3行索引数据内容:
01
00 00 20 00 19
80 00 00 03 /* 指向的主键id */
当索引的内容为NULL值时, 辅助索引的文件格式也变得奇怪了起来, 和第一行完全不一样, 再来看看第5行:
00 /* 当前索引字段的长度 */
00 00 00 30 ff cc
80 00 00 05 /* 指向的主键id */
和正常索引内容基本类似, 空字符串仍然没有表示, 仅使用了00表示该字段长度为0。
4. 辅助索引叶子节点存储方式
在MySQL中, 数据管理的最小单元为页(page), 而并非一行一行的数据。 数据保存在页中, 当我们使用主键查找一行数据时, 其实MySQL并不能直接返回这一行数据, 而是将该行所在的页载入内存, 然后在内存页中进行查找。
通常情况下页大小为16K, 在某些情况下可能会对页进行压缩, 使得页大小为8K或者是4K。 由于B+Tree的特点, 使得每一页内最少为2行数据, 再少就将退化成链表, 显然出于效率的考量不会让此种情况出现。 故而一行数据大小至多为16K, 通过该特性, 就可以研究二级索引的叶子节点是什么样子的了。
CREATE TABLE two (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
nickname VARCHAR(8000),
PRIMARY KEY (id),
KEY (nickname(2000))
) ENGINE=InnoDB CHARSET=LATIN1;
INSERT INTO two SELECT 1, 'a', REPEAT('A', 8000);
INSERT INTO two SELECT 2, 'b', NULL;
INSERT INTO two SELECT 3, 'c', REPEAT('C', 8000);
INSERT INTO two SELECT 4, 'd', NULL;
INSERT INTO two SELECT 5, 'e', REPEAT('E', 8000);
INSERT INTO two SELECT 6, 'f', REPEAT('F', 8000);
INSERT INTO two SELECT 7, 'g', NULL;
INSERT INTO two SELECT 8, 'h', REPEAT('H', 8000);
INSERT INTO two SELECT 9, 'i', REPEAT('G', 8000);
INSERT INTO two SELECT 10, 'i', "";
由于索引长度的限制, 这里仅取nickname的前2000个字符进行索引, 并插入一些具有代表性的数据。 同样使用hexdump -C two.ibd对索引结构进行分析:
00010070 73 75 70 72 65 6d 75 6d d0 87 00 05 00 10 07 e6 |supremum........|
00010080 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 |AAAAAAAAAAAAAAAA|
*
00010850 80 00 00 01 01 00 00 18 07 e6 80 00 00 02 d0 87 |................|
00010860 00 00 00 20 07 e6 43 43 43 43 43 43 43 43 43 43 |... ..CCCCCCCCCC|
00010870 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 |CCCCCCCCCCCCCCCC|
*
00011030 43 43 43 43 43 43 80 00 00 03 01 00 00 28 0f c2 |CCCCCC.......(..|
00011040 80 00 00 04 d0 87 00 00 00 30 07 dc 45 45 45 45 |.........0..EEEE|
00011050 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 |EEEEEEEEEEEEEEEE|
*
00011810 45 45 45 45 45 45 45 45 45 45 45 45 80 00 00 05 |EEEEEEEEEEEE....|
00011820 d0 87 00 00 00 38 0f c2 46 46 46 46 46 46 46 46 |.....8..FFFFFFFF|
00011830 46 46 46 46 46 46 46 46 46 46 46 46 46 46 46 46 |FFFFFFFFFFFFFFFF|
*
00011ff0 46 46 46 46 46 46 46 46 80 00 00 06 01 00 00 40 |FFFFFFFF.......@|
00012000 0f c3 80 00 00 07 d0 87 00 00 00 48 e0 62 48 48 |...........H.bHH|
00012010 48 48 48