hadoop所有的配置文件都是在 etc/hadoop下
步骤一启动HDFS并运行MapReduce
(1)配置集群
第一步:在hadoop下修改core-site.xml文件
vim etc/hadoop/core-site.xml
<configuration>
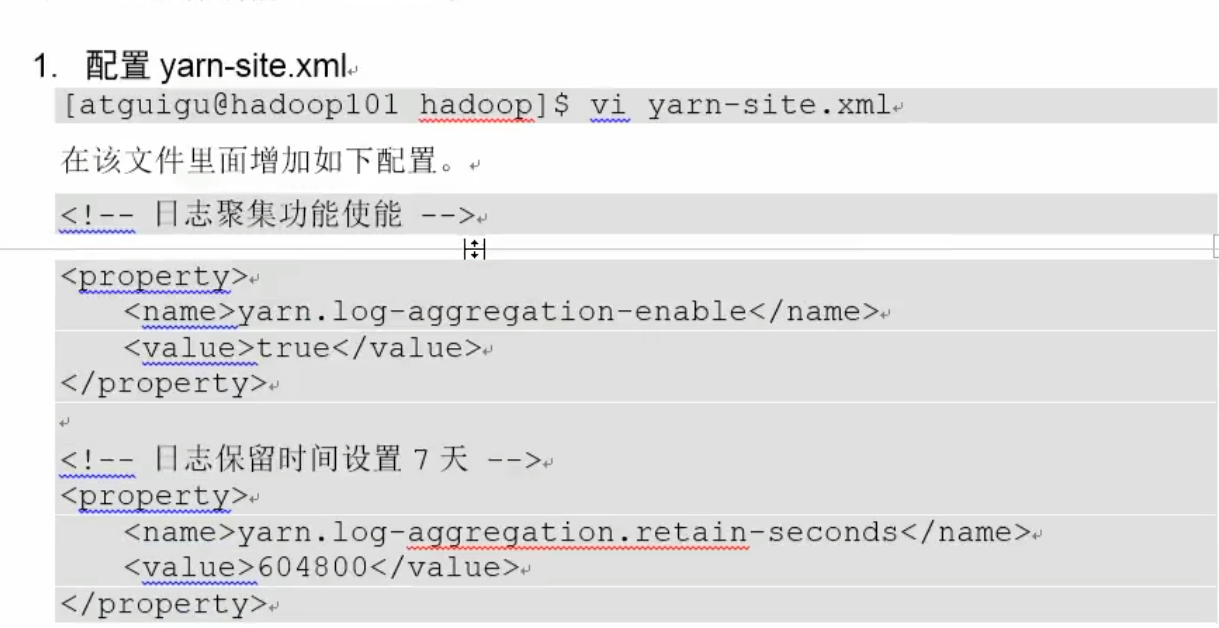
<!-- 指定HDFS中Name Node的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的储存目录-->
<property>
<name>dfs.replication</name>
<value>/opt/module/hadoop-2.7.2/data/tem</value>
</property>
</configuration>
第二步:修改hadoop-evn.sh的java_home路径
echo $JAVA_HOME
输出结果为 /opt/software/javajdk
复制
vim hadoop-evn.sh
修改 export JAVA_HOME=/opt/software/javajdk
保存退出
第三步:在hadoop下配置副本集(配置后本地运行环境就不行了)
vim hdfs-site.xml
<configuration>
<name>dfs.replication</name>
<value>1</value>
</configuration>
保存退出
(2)启动集群
第一步:格式化Name Node(第一次启动时格式化,以后就不要总格式化解决方法如下图)

bin/hdfs namenode -format 进入bin目录下hdfs文件下的namenode -format命令
第二步:启动Name Node
sbin/hadoop-daemon.sh start namenode
(启动后使用 jps 命令查看进程 必须安装jdk才能使用)
第三步:启动DATa Node
sbin/hadoop-daemon.sh start datanode
(启动后使用 jps 命令查看进程 必须安装jdk才能使用)
启动后可通过http://192.168.1.101:50070/ 查看ip地址为你的ip地址(外界主机访问需要关闭防火墙)
(3)查看集群
jps
步骤二,启动YARN并运行MapReduce
(1)配置集权
第一步:配置yarn-env.sh
cd etc/hadoop/
vim yarn-env.sh
把JAVA_HOME注释打开并修改为JAVA_HOME路径(不知道的可以使用 echo JAVA_HOME查询)
export JAVA_HOME=/opt/software/javajdk
第二步:配置yarn-site.xml
vim yarn-site.xml
<configuration>
<!--Reducer 获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--指定yarn的ResourceManager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
</configuration>
第三步:配置mapred-env.sh
vim mapred-env.sh
把JAVA_HOME注释打开并修改为JAVA_HOME路径(不知道的可以使用 echo JAVA_HOME查询)
export JAVA_HOME=/opt/software/javajdk
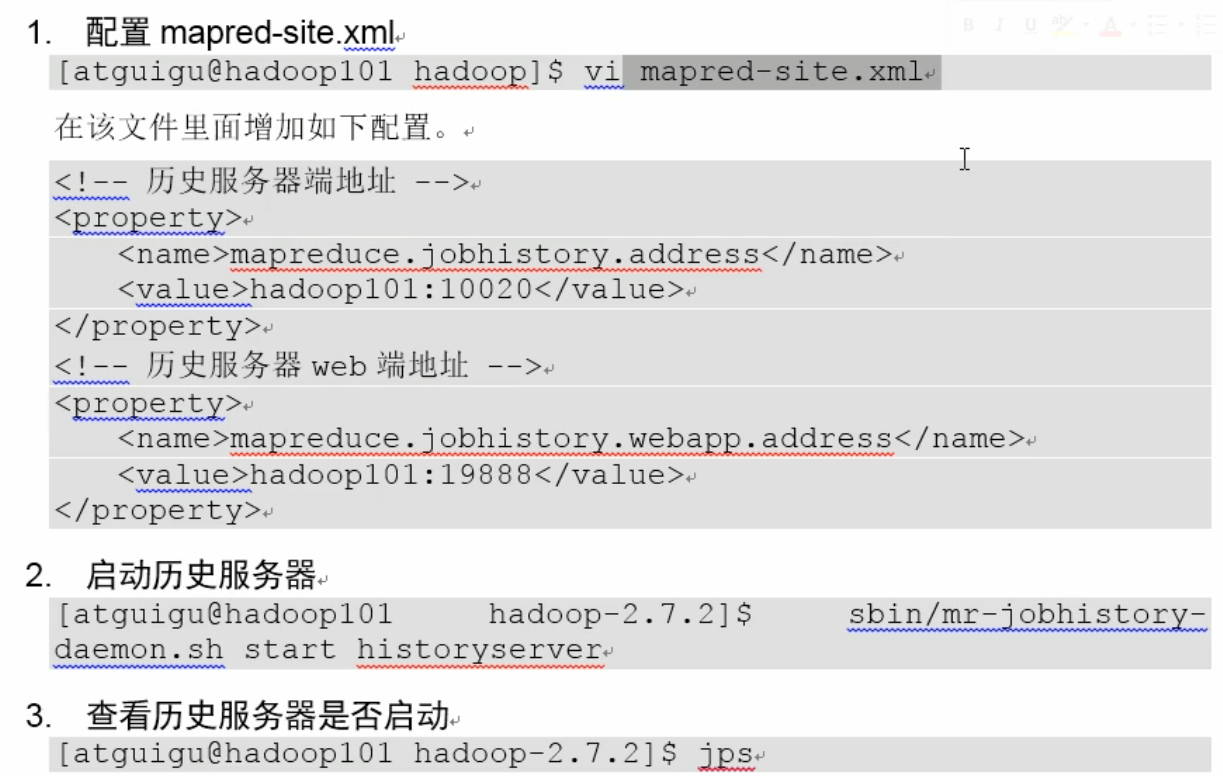
第四步:配置(对mapred-site.xml.template重命令为)mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<!--指定MR运行在YARN上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
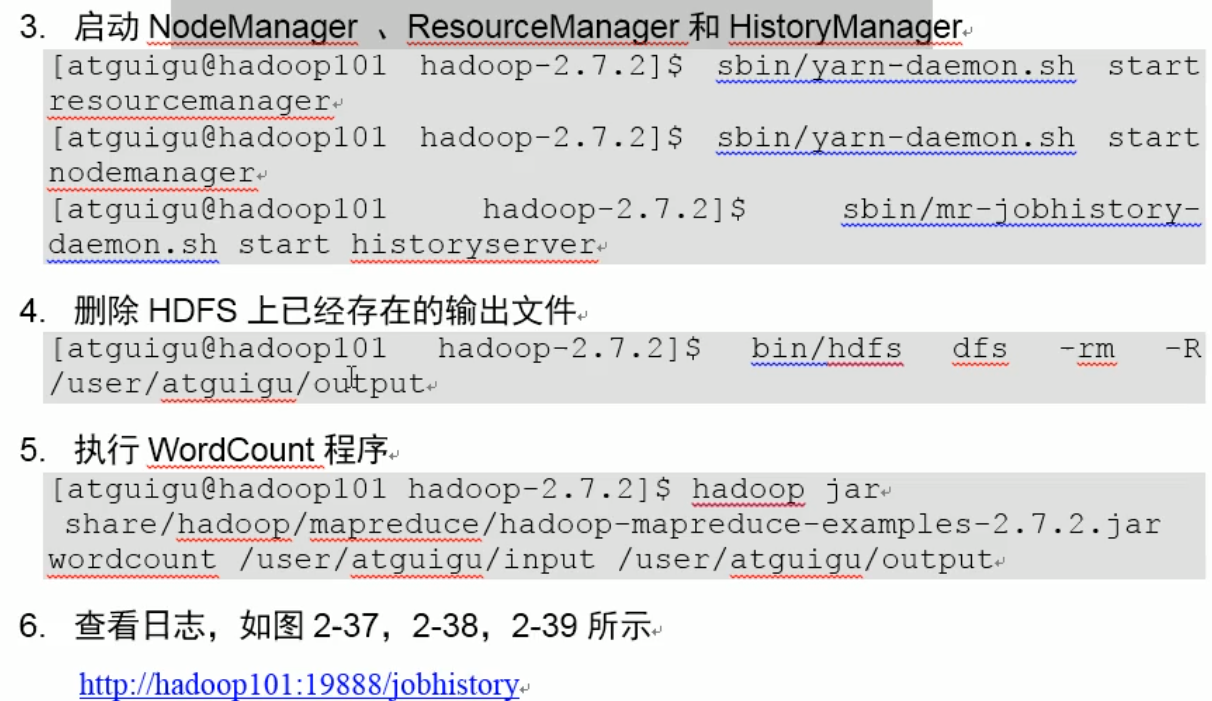
(2)启动集群
第一步:启动前必须保证NameNode和DataNode已经启动
第二步:启动ResourceManager
在Hadoop根目录下 sbin/yarn-daemon.sh start resourcemanager
第三步:启动NodeManager sbin/yarn-daemon.sh start nodemanager
(3)集群操作
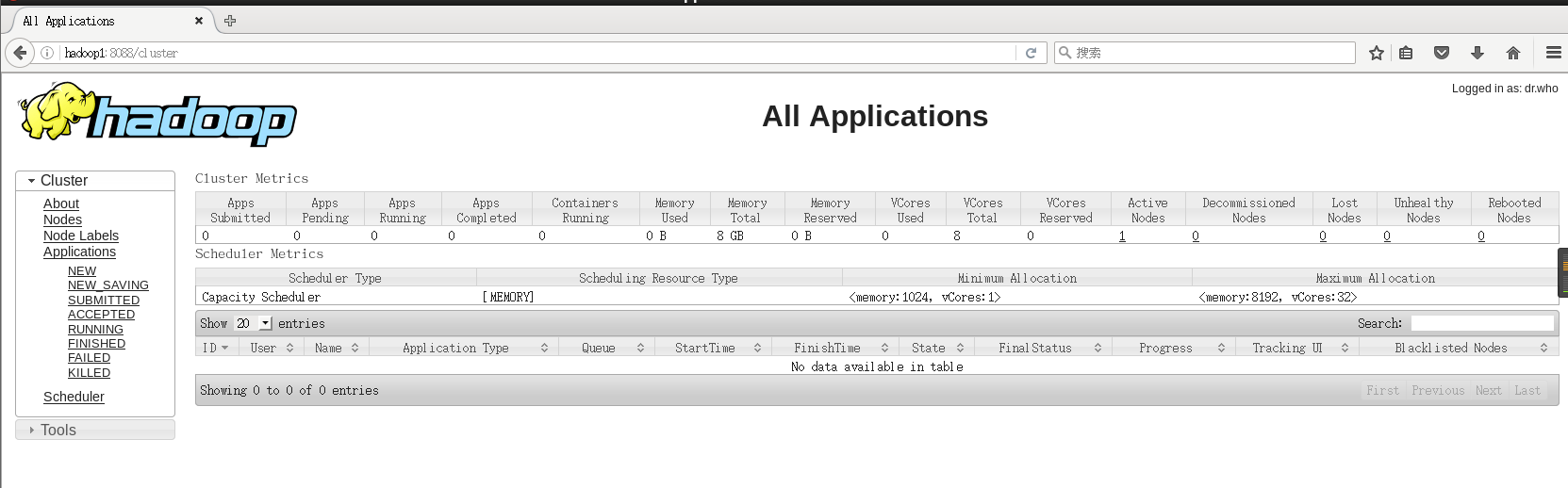
第一步:yarn的浏览器页面查看显示页面如下
http://hadoop1:8088/cluster
步骤三:配置历史服务器
步骤四:配置日志的聚集