之前已经说过skynet的是做什么的,现在开始从模块上研究skynet的源码。
skynet各层表现
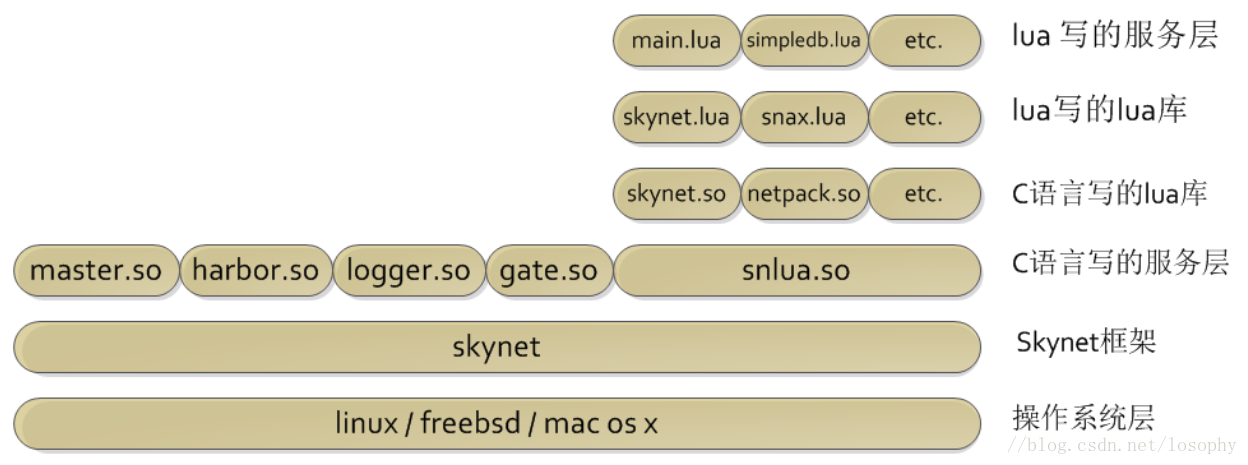
从上大概就清楚skynet的“内部”
而skynet源码目录结构如下:
3rd:第三方代码,有lua和jemalloc等。
lualib:使用lua写的库
lualib-src:使用C写并封装给lua使用的库
service:使用lua写的skynet的服务模块
service-src:使用C写的skynet的服务模块
skynet-src:skynet核心代码
skynet重要模块
gate.so:为整个skynet提供socket功能(解决外部连接数据读取的问题)
snlua.so:启动多个lua服务,skynet自带的模块中有一个重要的模块是snlua.so模块,通过snlua.so和指定lua脚本文件可以启动多个lua编写的服务,不用每个服务都是用c来编写,而且大部分逻辑都是在 lua 脚本下开发,只有需要考虑性能的模块才用 C 语言开发成库,直接提供给 lua 调用。
logger.so:日志模块,一个简单的日志系统,可以用来记录服务的相关信息。
harbar.so:(集群模块)节点服务,每个Skynet运行都是一个节点
skynet重要服务
launcher.lua:在lua中启动服务
skynet.lua:lua常用功能封装
skynet.so:lua调用skynet功能
skynet重要文件
skynet_handle.c:管理服务唯一的handle
skynet_module.c:启动c编写的so模块
skynet_monitor.c:监视服务死循环
skynet_mq.c:消息队列
skynet_timer.c:定时器
skynet_socket.c:Socket
skynet_master.c:不同skynet节点服务名字中心服务
skynet_harbor.c:不同skynet节点通讯
每个模块需要实现四个最基本的函数,create/init/release/signal。create做内存分配。init做初始化,它可能会做一些其它的事情,比如打开网络,打开文件,函数回调挂载等等。relase做资源回收,包括内存资源,文件资源,网络资源等等,signal是发信号,比如kill信号,告诉模块该停了。
网络
网络部分是一个服务器最基础最核心的部分,这个技术也已经是非常成熟了,现在已经很少有人自己实现一个网络相关的库了。skynet的网络库是自己实现的。
实际上云风只实现了epoll和kqueue,windows上的变种请自行搜索吧。
epoll和kqueue的实现分别在skynet_epoll.h和epoll_kqueue.h当中。epoll的函数其实就是epoll_create/epoll_ctl/epoll_del/epoll_wait这几个,要注意的是skynet中的epoll_create的参数是1024。所以连接数上不去的话很可能就是这里限制了。
skynet在skynet_poll.h中根据平台的不同包含了不同的头文件,屏蔽了平台相关性。然后在socket_server.c中实现了网络服务的逻辑。
然后skynet在skynet_socket.c中对socket_server.c中的逻辑再次做了一个封装,还添加了socket客户端相关的函数,就是connect/send/close之类的函数。
为了方便lua层使用socket,在lua-socket.c中再将对skynet_socket.c进行了一次封装。这个封装就是c语言层和lua语言层的相互转换。目前只支持tcp和udp,基于tcp上的http/websocket之类统统是不支持的。
skynet的配置加载
skynet的配置文件是以lua格式来写的。使用过skynet的都清楚skynet的启动命令是skynet config_file_name。配置文件名是作为命令行参数传给skynet进程的。
skynet进程启动以后,会读取config文件,然后解析这个lua文件。然后把相关的配置信息设置到lua的环境变量里。
C层读取配置的话是要从lua环境变量里去取的。
skynet一共有4种线程,monitor线程用于检测节点内的消息是否堵住,timer线程运行定时器,socket线程进行网络数据的收发,worker线程则负责对消息队列进行调度(worker线程的数量,可以通过配置表指定)。消息调度规则是,每条worker线程,每次从全局消息队列中pop出一个次级消息队列,并从次级消息队列中pop出一条消息,并找到该次级消息队列的所属服务,将消息传给该服务的callback函数,执行指定业务,当逻辑执行完毕时,再将次级消息队列push回全局消息队列中。因为每个服务只有一个次级消息队列,每当一条worker线程,从全局消息队列中pop出一个次级消息队列时,其他线程是拿不到同一个服务,并调用callback函数,因此不用担心一个服务同时在多条线程内消费不同的消息,一个服务执行,不存在并发,线程是安全的
socket线程、timer线程甚至是worker线程,都有可能会往指定服务的次级消息队列中push消息,push函数内有加一个自旋锁,避免同时多条线程同时向一个次级消息队列push消息的惨局。
参考:
《skynet_summary》
《Skynet框架之菜鸟手册》