1. 百度智能云
网址:https://login.bce.baidu.com/
登录,认证:输入名字身份证即可。
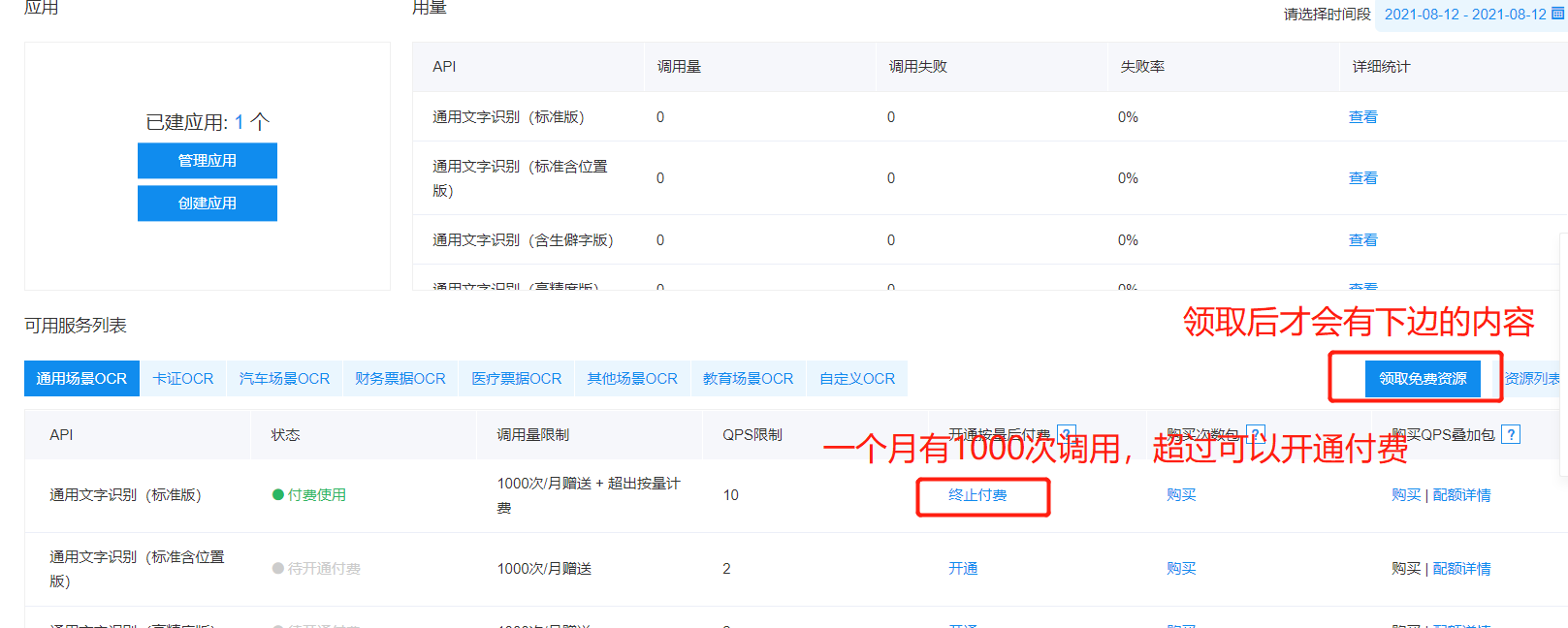
点击产品服务,找人工智能-文字识别,进去后 右边 领取免费资源(一般一个小时到账),然后创建应用即可使用。
使用方法:
from aip import AipOcr class baiduApi: def __init__(self,APP_ID,API_KEY,SECRET_KEY): self.client = AipOcr(APP_ID, API_KEY, SECRET_KEY) """ 读取图片 """ def get_file_content(self,imageFile): with open(imageFile, 'rb') as fp: return fp.read() def getWordFromImage(self,imageFile): image = self.get_file_content(imageFile) result = self.client.basicGeneral(image) words_result = result['words_result'] for words_dict in words_result: words = words_dict['words'] print(words) if __name__=="__main__": # 百度智能云 接口识别 ''' """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' ''' APP_ID='**' API_KEY='***' SECRET_KEY='**** ' obj = baiduApi(APP_ID,API_KEY,SECRET_KEY) imageFile='D:/font/png_test/3602313.png' obj.getWordFromImage(imageFile)
2. 讯飞
网址:https://passport.xfyun.cn/login
注册登录,实名认证(需要身份证正反面)可以领10万次调用。
点击控制台-右边文字识别-你想识别的类型-创建应用。
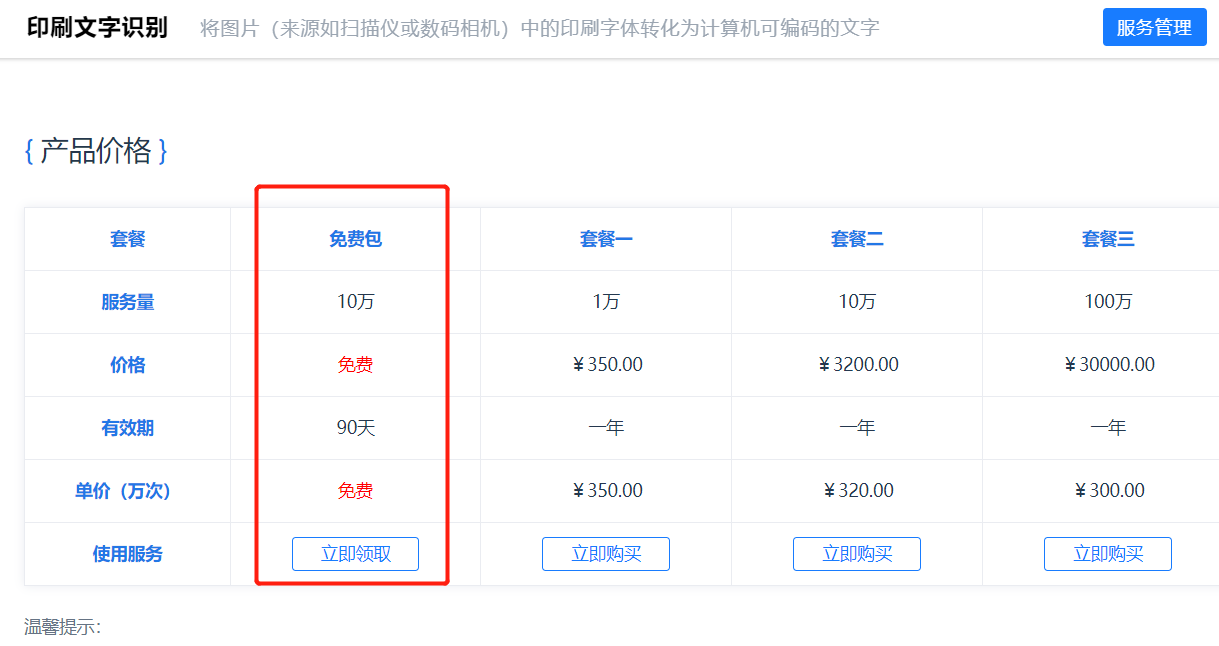
首页-产品服务-文字识别-你想识别的类型-往下拉可以领取10万次免费调用。
使用方法:
注意:印刷文字识别,图片的大小对识别结果影响很大,实测,图片超过700X1200的结果就不是很好了。
import requests import time import hashlib import base64 import json def get_header(): curTime = str(int(time.time())) param = {"language": "cn|en", "location": "false"} param = json.dumps(param) paramBase64 = base64.b64encode(param.encode('utf-8')) m2 = hashlib.md5() str1 = API_KEY + curTime + str(paramBase64, 'utf-8') m2.update(str1.encode('utf-8')) checkSum = m2.hexdigest() header = { 'X-CurTime': curTime, 'X-Param': paramBase64, 'X-Appid': APPID, 'X-CheckSum': checkSum, 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8', } return header def ocr_png(): content_txt = '' headers = get_header() with open(png_path, 'rb') as f: f1 = f.read() f1_base64 = str(base64.b64encode(f1), 'utf-8') data = { 'image': f1_base64 } URL = "http://webapi.xfyun.cn/v1/service/v1/ocr/general" resp_dict = requests.post(URL, data=data, headers=headers).json() block_list = resp_dict['data']['block'] for block in block_list: line_list = block['line'] for line in line_list: word_list = line['word'] for word in word_list: content_1 = word['content'] content_txt += content_1 + ' ' return content_txt if __name__ == '__main__': APPID = "***" API_KEY = "****" png_path = 'D:/font/png_test/3646782.png' content = ocr_png() print(content)