多进程和多线程的守护区别
首先明确一点,无论是多进程还是多线程,主进程或主线程都会等待子进程或子线程退出才会退出。
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁. 需要强调的是:运行完毕并非终止运行
- 对主进程来说,运行完毕指的是主进程代码运行完毕
- 对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
也就是说:
- 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束,
- 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
import os
import time
from multiprocessing import Process
def task1():
while True:
print('task1', os.getpid())
time.sleep(1)
def task2():
while True:
print('task2')
time.sleep(1.5)
if __name__ == '__main__':
p1 = Process(target=task1)
p1.daemon = True
p1.start()
p2 = Process(target=task2)
p2.start()
# task1 不会被执行,因为进程的开启是比线程慢的,所以一般情况下是主进程代码执行完毕再执行子进程
print('main over')
GIL 锁
GIL锁是一把cpython解释器帮我们加的互斥锁,加这把锁是基于内存管理机制考虑的。如果没有这把锁,再考虑多个线程同时只能被一个CPU处理的情况,因为没有锁的多线程的并发肯定会设计到资源抢占。垃圾回收机制的活还没干完就被另外一个线程抢走了CPU的执行权限,恰好这个线程又要对垃圾回收要处理的一个变量做相关操作(比如加1),那这种情况垃圾回收就没有意义了。所以,在进程空间的外面加了一把锁,如果垃圾回收机制抢到这把锁,把垃圾回收的活干完释放锁,这样垃圾回收机制才能实现。
GIL锁和我们自己在程序申明的锁有什么区别?GIL锁可以看做是整个进程空间出口上的锁,而我们自己申明的锁是用来锁住进程里面的的数据的。
多进程的锁
多进程是数据隔离的,为啥还需要锁呢?因为多进程虽然是数据隔离,但是却共享文件系统和打印终端。如果是开启多个进程队文件进程读写操作,那么就需要用到锁
from multiprocessing import Process,Lock
import time,json
def search():
dic=json.load(open('ticket.txt'))
print('�33[43m剩余票数%s�33[0m' %dic['count'])
def get():
dic=json.load(open('ticket.txt'))
time.sleep(0.1) # 模拟读数据的网络延迟,这里是为了等待其他进程开启并完成load操作
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(0.2) # 模拟写数据的网络延迟,以防dump的w模式清空文件但是另一个进程在search的时候load空文件会报错
json.dump(dic,open('ticket.txt','w'))
print('�33[43m购票成功�33[0m')
def task(lock):
search()
get()
if __name__ == '__main__':
lock=Lock()
for i in range(100): #模拟并发100个客户端抢票
p=Process(target=task,args=(lock,))
p.start()
加锁
from multiprocessing import Process,Lock
import time,json
from multiprocessing import Lock
def search():
dic=json.load(open('ticket.txt'))
print('�33[43m剩余票数%s�33[0m' %dic['count'])
def get():
dic=json.load(open('ticket.txt'))
time.sleep(0.1) # 模拟读数据的网络延迟,这里是为了等待其他进程开启并完成load操作
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(0.2) # 模拟写数据的网络延迟,以防dump的w模式清空文件但是另一个进程在search的时候load空文件会报错
json.dump(dic,open('ticket.txt','w'))
print('�33[43m购票成功�33[0m')
def task(lock):
search()
lock.acquire()
get()
lock.release()
if __name__ == '__main__':
lock=Lock()
for i in range(100): #模拟并发100个客户端抢票
p=Process(target=task,args=(lock,))
p.start()
这里不是在get函数里面加锁,而是另外封装了一个task函数,在task函数里面给get() 加锁
队列
无论是进程还是线程的队列,都已经帮我们做过加锁处理了,而且队列里可以丢进去自定义的对象,还可以丢None对象。线程可以共享全局变量,进程虽然不能共享全局变量,可以有可以共享数据的方式。同线程共享
数据就会有抢占资源的情况,进程如果使用共享数据的方式,也会出现资源竞争的情况。multiprocessing的Manager其实就是另外开一个进程,在这个进程里面开辟一块共享内存。
池
multiprocessing的Pool
同步使用方式(不常用)
from multiprocessing import Pool
import os,time
def work(n):
print('%s run' %os.getpid())
time.sleep(3)
return n**2
if __name__ == '__main__':
p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
res_l=[]
for i in range(10):
res=p.apply(work,args=(i,)) #同步调用,直到本次任务执行完毕拿到res,等待任务work执行的过程中可能有阻塞也可能没有阻塞,但不管该任务是否存在阻塞,同步调用都会在原地等着,只是等的过程中若是任务发生了阻塞就会被夺走cpu的执行权限
res_l.append(res)
print(res_l)
异步
from multiprocessing import Pool
import os,time
def work(n):
time.sleep(1)
return n**2
if __name__ == '__main__':
p=Pool(os.cpu_count()) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
res_l=[]
for i in range(10):
res=p.apply_async(work,args=(i,)) #同步运行,阻塞、直到本次任务执行完毕拿到res
res_l.append(res)
#异步apply_async用法:如果使用异步提交的任务,主进程需要使用jion,等待进程池内任务都处理完,然后可以用get收集结果,否则,主进程结束,进程池可能还没来得及执行,也就跟着一起结束了
p.close()
p.join()
# join之后get() 就能立即拿到值,如果注释掉上面两句代码,那么是每3个打印一次,没有结果的get会出现阻塞
for res in res_l:
print(res.get()) #使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get
回调
from multiprocessing import Pool
import os,time
def work(n):
time.sleep(1)
return n**2
def get_data(data):
# 会把work return的结果传给get_data 做参数
print('得到的数据是:', data)
if __name__ == '__main__':
p=Pool(os.cpu_count()) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
res_l=[]
# 回调函数是主进程执行的,如果主进程调用time.sleep(10000),当work执行完毕之后
# 操作系统就会跟主进程说,别睡了,快去处理任务,处理完再睡
for i in range(10):
p.apply_async(work,args=(i,), callback=get_data) #同步运行,阻塞、直到本次任务执行完毕拿到res
# 因为是异步的,如果不加下面两句,那么主进程退出,池子里的任务还没执行
p.close()
p.join()
对结果的处理方式一般就两种: 一种是拿到结果立即调用,另外一个是把结果拿到做统一处理,推荐使用第一种方式
concurrent
import time
from concurrent.futures import ProcessPoolExecutor
def work(n):
time.sleep(1)
return n**2
def get_data(res):
# 传的参数res是一个对象
print('得到的数据是:', res.result())
if __name__ == '__main__':
executor = ProcessPoolExecutor(max_workers=5)
# futures = []
# for i in range(10):
# future = executor.submit(work, i).add_done_callback(get_data)
# futures.append(future)
# executor.shutdown()
# for future in futures:
# print(future.result())
for i in range(10):
executor.submit(work, i).add_done_callback(get_data)
# 下面不加shutdown也能执行池里的任务,只不过为了代码可读性,一般还是建议加上
map使用方式
from concurrent.futures import ProcessPoolExecutor
import os,time,random
def task(n):
print('%s is runing' %os.getpid())
time.sleep(random.randint(1,3))
return n**2
if __name__ == '__main__':
executor = ProcessPoolExecutor(max_workers=3)
# for i in range(11):
# # concurrent 模块不加shutdown 主进程执行完毕会等池里的任务执行完毕程序才会结束,不同于Pool
# # 而且 concurrent 是用异步,没有Pool的同步方式
# executor.submit(task,i)
# map 得到的是一个存储结果(不需要.result()) 的可迭代对象
data_obj = executor.map(task,range(1,12)) # map取代了for+submit
for data in data_obj:
print(data)
greenlet 和 gevent
python中的协程就是greenlet,就是切换+保存状态。线程是操作系统调度的,但是协程的切换是程序员进行调度的,操作系统对此“不可见”。既然要保存状态,那么肯定就会涉及到栈,协程也有自己的栈,只不过这个开销比线程小。单纯的协程并不能帮我们提高效率,只能帮我们保存上次运行的状态并做来回切换,所以大家又基于协程的切换+保存状态做了进一步的封装,让程序能遇到IO阻塞自动切换,如gevent模块等。gevent模块就是利用事件驱动库 libev 加 greenlet实现的。我们知道,事件循环是异步编程的底层基石。如果用户关注的层次很低,直接操作epoll去构造维护事件的循环,从底层到高层的业务逻辑需要层层回调,造成callback hell,并且可读性较差。所以,这个繁琐的注册回调与回调的过程得以封装,并抽象成EventLoop。EventLoop屏蔽了进行epoll系统调用的具体操作。对于用户来说,将不同的I/O状态考量为事件的触发,只需关注更高层次下不同事件的回调行为。诸如libev, libevent之类的使用C编写的高性能异步事件库已经取代这部分琐碎的工作。综上所述,当事件发生的时候通知用户程序进行协程的切换。准确来说,gevent是一个第三方异步模块,这个模块能让我像使用线程的方式去使用协程,而且这个模块需要socket是非阻塞socket的,所以一般在程序最开头加上monkey.patch_all().
import greenlet
def task1():
print('task1 start')
g2.switch()
print('task1 end')
g2.switch()
def task2():
print('task2 start')
g1.switch()
print('task2 end')
g1 = greenlet.greenlet(task1)
g2 = greenlet.greenlet(task2)
g1.switch()
gevent模块的基本使用
from gevent import spawn, joinall, monkey
import time
monkey.patch_all()
def task(i):
time.sleep(1)
print('----', i)
return i * 2
if __name__ == '__main__':
# spawn 的时候会创建一个协程并立即执行
res = [spawn(task, i) for i in range(10)]
joinall(res)
for g in res:
print(g.value)
IO 模型
用户空间和内核空间,用户态和内核态
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
用户态和内核态讲述的是CPU的状态,用户态是CPU可以执行的指令比较少,内核态是CPU可以处理的指令比较多,可以先这么简单地理解。
同步,异步,阻塞和非阻塞
同步和异步,阻塞和非阻塞这两组的关注点是不同的。
同步是程序员的程序"亲自"主动去等结果,当然在这个等结果的过程中程序可以干别的事情(进程或线程的状态是非阻塞),但是程序还得过一段时间来查看是否已经有结果了,程序需要干两件事,只有一个角色
异步是程序员的程序发了个口号去要结果,然后就等另外一个"东西"通知我结果已经好了,这时候角色就有两个了。当然,你可以在这个过程去干别的事,也可以不干(除非你傻)。在这里的消息通知也可以看作是回调,
还记得上面主进程在sleep的时候当work的任务完成之后操作系统会把主进程叫醒执行回调函数吗?
阻塞和非阻塞描述的是进程或者线程所处的状态。
几种不同的IO模型
- 阻塞IO
- 非阻塞IO
- IO多路复用(又名事件驱动)
- 异步IO
上面的四种不同的IO模型是针对两个阶段的不同状态而言的:1. 等待数据到内核空间 2. 把数据从内核空间拷贝到用户程序的进程空间
1、输入操作:read、readv、recv、recvfrom、recvmsg共5个函数,如果会阻塞状态,则会经理wait data和copy data两个阶段,如果设置为非阻塞则在wait 不到data时抛出异常
2、输出操作:write、writev、send、sendto、sendmsg共5个函数,在发送缓冲区满了会阻塞在原地,如果设置为非阻塞,则会抛出异常
3、接收外来链接:accept,与输入操作类似
4、发起外出链接:connect,与输出操作类似
对IO多路复用的补充:
- 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
- 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking(由我们自己的程序不停地while循环去询问socket数据是否准备好改成由操作系统帮我们做这事,所以一般socket设置成non-blocking),但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
select、poll和epool
这三种技术都是"古人"开发的,是操作系统级别的程序开发。
- select: 效率最低,但有最大描述符限制,在linux为1024,多种平台都支持。操作系统是通过循环一遍监听的文件对象列表看是否有对象的状态发生改变,如果是列表第一个和最后一个状态发生改变,需要从前到后循环才能得知这两个发生改变。
- poll: 和select一样,但没有最大描述符限制。
- epoll: 效率最高,没有最大描述符限制,支持水平触发与边缘触发。windows系统不支持。epoll监听的socket发生变化会通过回调来通知操作系统。
IO多路复用中的两种触发方式:
- 水平触发:如果文件描述符已经就绪可以非阻塞的执行IO操作了,此时会触发通知.允许在任意时刻重复检测IO的状态, 没有必要每次描述符就绪后尽可能多的执行IO.select,poll就属于水平触发。
- 边缘触发:如果文件描述符自上次状态改变后有新的IO活动到来,此时会触发通知.在收到一个IO事件通知后要尽可能 多的执行IO操作,因为如果在一次通知中没有执行完IO那么就需要等到下一次新的IO活动到来才能获取到就绪的描述 符.信号驱动式IO就属于边缘触发。
selectors 模块
from socket import *
import selectors
sel=selectors.DefaultSelector()
def accept(server_fileobj,mask):
conn,addr=server_fileobj.accept()
sel.register(conn,selectors.EVENT_READ,read)
def read(conn,mask):
try:
data=conn.recv(1024)
if not data:
print('closing',conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper()+b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn)
conn.close()
server_fileobj=socket(AF_INET,SOCK_STREAM)
server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server_fileobj.bind(('127.0.0.1',8088))
server_fileobj.listen(5)
server_fileobj.setblocking(False) #设置socket的接口为非阻塞
sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept
while True:
events=sel.select() #检测所有的fileobj,是否有完成wait data的
for sel_obj,mask in events:
callback=sel_obj.data #callback=accpet
callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1)
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8088))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
线程死锁的问题解决方案
把原来多把互斥锁改成一把可重复锁
互斥锁只能acquire一次,可重复锁可以acquire多次,这里的acquire多次是针对单个线程而言的,如果A线程acquire了,在A线程内还能再次acquire(内部维护了一个计数器),但是其他线程就不能acquire
多把互斥锁按照顺序去获取
每个线程按照固定的顺序去获取锁就不会出问题,比如要想获取锁,必须遵循先A锁后B锁的顺序,那么一个线程获取A锁,那么另外的线程要想获取锁的时候也必须先拿A锁,以此来解决死锁问题。
import threading
import time
from contextlib import contextmanager
_local = threading.local()
# 统一接口,以后想要获取锁就用这个函数去获取,这个函数把锁做了排序
@contextmanager
def acquire(*locks):
locks = sorted(locks, key=lambda x: id(x))
# 这里用threading.local() 保存线程局部变量,主要用于嵌套去获取锁的情况
# 记录线程已经获取的锁,然后和要获取的锁的id做比较,顺序不符合就抛出异常
acquired_locks = getattr(_local, 'acquired', [])
if acquired_locks and max(id(lock) for lock in acquired_locks) >= id(locks[0]):
raise RuntimeError('出现死锁了,程序报错退出')
acquired_locks.extend(locks)
_local.acquired = acquired_locks
try:
for lock in locks:
lock.acquire()
yield
finally:
for lock in reversed(locks):
lock.release()
del acquired_locks[-len(locks):]
if __name__ == '__main__':
x_lock = threading.Lock()
y_lock = threading.Lock()
# def thread_1():
# with acquire(x_lock, y_lock):
# print('Thread-1')
#
# def thread_2():
# with acquire(y_lock, x_lock):
# print('Thread-2')
# t1 = threading.Thread(target=thread_1)
# t1.start()
# t2 = threading.Thread(target=thread_2)
# t2.start()
def thread_1():
with acquire(x_lock):
with acquire(y_lock):
print('Thread-1')
def thread_2():
with acquire(y_lock):
with acquire(x_lock):
print('Thread-2')
t1 = threading.Thread(target=thread_1)
t1.start()
t2 = threading.Thread(target=thread_2)
t2.start()
python 中的异步究竟是怎么实现的
第一步
掌握python异步的起点是:epoll + callback + 事件循环
import socket
from selectors import DefaultSelector, EVENT_WRITE, EVENT_READ
selector = DefaultSelector()
stopped = False
urls_todo = {'/', '/1', '/2', '/3', '/4', '/5', '/6', '/7', '/8', '/9'}
class Crawler:
def __init__(self, url):
self.url = url
self.sock = None
self.response = b''
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.sock.connect(('example.com', 80))
except BlockingIOError:
pass
selector.register(self.sock.fileno(), EVENT_WRITE, self.connected)
def connected(self, key, mask):
selector.unregister(key.fd)
get = 'GET {0} HTTP/1.0
Host: example.com
'.format(self.url)
self.sock.send(get.encode('ascii'))
selector.register(key.fd, EVENT_READ, self.read_response)
def read_response(self, key, mask):
global stopped
# 如果响应大于4KB,下一次循环会继续读
chunk = self.sock.recv(4096)
if chunk:
self.response += chunk
else:
selector.unregister(key.fd)
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
def loop():
while not stopped:
# 阻塞, 直到一个事件发生
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback(event_key, event_mask)
if __name__ == '__main__':
import time
start = time.time()
for url in urls_todo:
crawler = Crawler(url)
crawler.fetch()
loop()
print(time.time() - start)
epoll
判断非阻塞调用是否就绪如果 OS 能做,是不是应用程序就可以不用自己去等待和判断了,就可以利用这个空闲去做其他事情以提高效率。
所以OS将I/O状态的变化都封装成了事件,如可读事件、可写事件。并且提供了专门的系统模块让应用程序可以接收事件通知。这个模块就是select。让应用程序可以通过select注册文件描述符和回调函数。当文件描述符的状态发生变化时,select 就调用事先注册的回调函数。
select因其算法效率比较低,后来改进成了poll,再后来又有进一步改进,BSD内核改进成了kqueue模块,而Linux内核改进成了epoll模块。这四个模块的作用都相同,暴露给程序员使用的API也几乎一致,区别在于kqueue 和 epoll 在处理大量文件描述符时效率更高。
Python标准库提供的selectors模块是对底层select/poll/epoll/kqueue的封装。DefaultSelector类会根据 OS 环境自动选择最佳的模块,那在 Linux 2.5.44 及更新的版本上都是epoll了
回调(Callback)
把I/O事件的等待和监听任务交给了 OS,那 OS 在知道I/O状态发生改变后(例如socket连接已建立成功可发送数据),它又怎么知道接下来该干嘛呢?只能回调。
需要我们将发送数据与读取数据封装成独立的函数,让epoll代替应用程序监听socket状态时,得告诉epoll:“如果socket状态变为可以往里写数据(连接建立成功了),请调用HTTP请求发送函数。如果socket 变为可以读数据了(客户端已收到响应),请调用响应处理函数。这里的回调是通知用户进程去做,而不是操作系统去执行回调函数。
事件循环
这个循环是我们程序员在程序里写的循环,不是操作系统的epoll的循环,我们通过这个循环,去访问selector模块,等待它告诉我们当前是哪个事件发生了,应该对应哪个回调。这个等待事件通知的循环,称之为事件循环。
selector.select() 是一个阻塞调用,因为如果事件不发生,那应用程序就没事件可处理,所以就干脆阻塞在这里等待事件发生。那可以推断,如果只下载一篇网页,一定要connect()之后才能send()继而recv(),那它的效率和阻塞的方式是一样的。因为不在connect()/recv()上阻塞,也得在select()上阻塞。所以,selector机制是设计用来解决大量并发连接的。当系统中有大量非阻塞调用,能随时产生事件的时候,selector机制才能发挥最大的威力。
部分编程语言中,对异步编程的支持就止步于此(不含语言官方之外的扩展)。需要程序猿直接使用epoll去注册事件和回调、维护一个事件循环,然后大多数时间都花在设计回调函数上。
不论什么编程语言,但凡要做异步编程,上述的“事件循环+回调”这种模式是逃不掉的,尽管它可能用的不是epoll,也可能不是while循环。但是使用的异步方式基本都是 “等会儿告诉你” 模型的异步方式。
但是在asyncio异步编程中为什么没有看到 CallBack 模式呢?因为 Python 异步编程是用了协程帮我们取代了回调。
回调之痛
基于"epoll+事件循环+回调”的基本运行原理,可以基于这种方式在单线程内实现异步编程。也确实能够大大提高程序运行效率。然而在生产项目中,要应对的复杂度会大大增加。考虑如下问题:
- 如果回调函数执行不正常该如何?
- 如果回调里面还要嵌套回调怎么办?要嵌套很多层怎么办?
- 如果嵌套了多层,其中某个环节出错了会造成什么后果?
- 如果有个数据需要被每个回调都处理怎么办?
首先回调嵌套回调的这种代码结构不清晰,其次一个回调想拿另一个回调的返回值就必须是do_a(do_b()),如果整个流程中全部改为异步处理,而流程比较长的话,代码逻辑就会成为这样:do_a(do_b(do_c(do_d(do_e(do_f(......))))))。
原本同步时候的从上而下的代码结构,要改成从内到外的。先f,再e,再d,…,直到最外层 a 执行完成。在同步版本中,执行完a后执行b,这是线程的指令指针控制着的流程,而在回调版本中,流程就是程序猿需要注意和安排的。我草,同步虽然效率低,
但是写起来简单呀,一根筋地从上到下,把业务逻辑写在回调函数里面的话,我还要精心设计整个回调链,NND!。再者,回调的函数要想同时访问一个变量或者说共享状态应该怎么办?没错,用面向对象的封装是可以解决。同步阻塞版的sock对象从头使用到尾,而在回调的版本中,我们必须在类实例化后的对象self里保存它自己的sock对象。如果不是采用OOP的编程风格,那需要把要共享的状态接力似的传递给每一个回调。多个异步调用之间,到底要共享哪些状态,事先就得考虑清楚,精心设计。MD, 为了共享状态又得精心设计。最后,一连串的回调构成一个完整的调用链。例如上述的 a 到 f。假如 d 抛了异常怎么办?整个调用链断掉,接力传递的状态也会丢失,这种现象称为调用栈撕裂。 c 不知道该干嘛,继续异常,然后是 b 异常,接着 a 异常。好嘛,报错日志就告诉你,a 调用出错了,但实际是 d 出错。所以,为了防止栈撕裂,异常必须以数据的形式返回,而不是直接抛出异常,然后每个回调中需要通过 if 判断检查上次调用的返回值,以防错误吞没。
为了迎合python简便的特点,python开发者在事件循环+回调的基础上衍生出了基于协程的解决方案。
现在考虑一下,异步编程的难点是什么?无非就是程序不知道自己已经干了什么?正在干什么?将来要干什么?换言之,程序得知道当前所处的状态,而且要将这个状态在不同的回调之间延续下去。比如说socket的connect已经尝过了,可以发送http请求消息了,那对应这个状态的发消息的回调函数要被执行,recv对应的回调函数需要知道是否已经处于可以接数据的状态。每个回调函数都有自己的状态,而且有时候这个状态还需要在不同函数进行传递,不同回调函数之间存在耦合性。
针对上面所述,要想知道程序在什么状态?每个任务(用于回调的函数)都有对应自己的状态?每个任务能用非OOP的方式共享状态?不同任务之间有耦合性?这些特点不正是python协程所具备的吗?至此,我们由回调 延伸到 协程。
而python实现协程的最基本方式是用yield。通过yield我们可以自上而下,一根筋地写同步代码,但是写的同步代码不会一下子执行完毕,会根据不同状态从不同入口切进来执行。也就是用yield编写的代码具有自上而下的代码结构,还能对应不同状态进行切换。
what?你还不知道协程是什么?协程是非抢占式的多任务子例程的概括,可以允许有多个入口点在例程中确定的位置来控制程序的暂停与恢复执行。例程是什么?编程语言定义的可被调用的代码段,为了完成某个特定功能而封装在一起的一系列指令。一般的编程语言都用称为函数或方法的代码结构来体现。用了yield来实现协程,可以满足自上而下的代码结构的要求,同时把代码分成几个片段,由不同状态去执行不同片段,又因为代码是自上而下的,所以共享状态就是理所当然的了。
import socket
from selectors import DefaultSelector, EVENT_WRITE, EVENT_READ
selector = DefaultSelector()
stopped = False
urls_todo = {'/', '/1', '/2', '/3', '/4', '/5', '/6', '/7', '/8', '/9'}
class Future:
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
class Crawler:
def __init__(self, url):
self.url = url
self.response = b''
def fetch(self):
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('example.com', 80))
except BlockingIOError:
pass
f = Future()
def on_connected():
f.set_result(None)
selector.register(sock.fileno(), EVENT_WRITE, on_connected)
# 在连接是否建立的分界线通过yield暂停
yield f
selector.unregister(sock.fileno())
get = 'GET {0} HTTP/1.0
Host: example.com
'.format(self.url)
sock.send(get.encode('ascii'))
global stopped
while True:
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
# 注册事件
selector.register(sock.fileno(), EVENT_READ, on_readable)
# 在可以读取内容的时候使用yield把程序进行分割
chunk = yield f
selector.unregister(sock.fileno())
if chunk:
self.response += chunk
else:
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
break
class Task:
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
# send会进入到coro执行, 即fetch, 直到下次yield
# next_future 为yield返回的对象
next_future = self.coro.send(future.result)
except StopIteration:
return
# 增加的回调函数是用来驱动coro往下执行寻找yield的
next_future.add_done_callback(self.step)
def loop():
while not stopped:
# 阻塞, 直到一个事件发生
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
if __name__ == '__main__':
import time
start = time.time()
for url in urls_todo:
crawler = Crawler(url)
# 创建了10个Task
Task(crawler.fetch())
loop()
print(time.time() - start)
未来对象有一个result属性,用于存放未来的执行结果。还有个set_result()方法,是用于设置result的,并且会在给result绑定值以后运行事先给future添加的回调。回调是通过未来对象的add_done_callback()方法添加的。
不要疑惑此处的callback,说好了不回调的嘛?难道忘了我们曾经说的要异步,必回调。只不过这里的回调函数不再是像以前一样用来写业务逻辑。
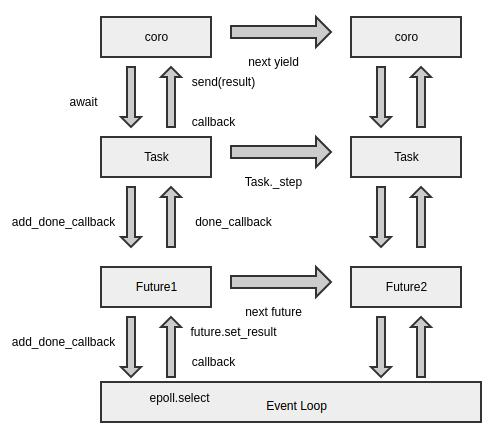
asyncio的loop:
事件循环的工作方式与用户设想存在一些偏差,理所当然的认知应是每个线程都可以有一个独立的 loop。但是在运行中,在主线程中才能通过 asyncio.get_event_loop() 创建一个新的 loop,而在其他线程时,使用 get_event_loop() 却会抛错,正确的做法应该是 asyncio.set_event_loop() 进行当前线程与 loop 的显式绑定。由于 loop 的运作行为并不受 Python 代码的控制,所以无法稳定的将协程拓展到多线程中运行。协程在工作时,并不了解是哪个 loop 在对其调度,即使调用 asyncio.get_event_loop() 也不一定能获取到真正运行的那个 loop。因此在各种库代码中,实例化对象时都必须显式的传递当前的 loop 以进行绑定。
yield from
yield from 是Python 3.3 新引入的语法(PEP 380)。它主要解决的就是在生成器里玩生成器不方便的问题。它有两大主要功能。
第一个功能是:让嵌套生成器不必通过循环迭代yield,而是直接yield from。以下两种在生成器里玩子生成器的方式是等价的。
yield from [1,2,3]
等价于
for i in [1,2,3]:
yield i
第二个功能就是在子生成器和原生成器的调用者之间打开双向通道,两者可以直接通信。
def gen():
yield from subgen()
def subgen():
while True:
x = yield
yield x+1
def main():
g = gen()
next(g) # 驱动生成器g开始执行到第一个 yield
retval = g.send(1) # 看似向生成器 gen() 发送数据,实际上发给了subgen
print(retval) # 返回2
g.throw(StopIteration) # 看似向gen()抛入异常
所以,以后一般遇到yield from,第一反应应该是后面接的是一个生成器(可能也是在函数里使用了yield)。基于yield from的封装:使用yield from的地方看作是一个代理,可以方便地用这个代理去操作生成器。
生成器里再对生成器做操作比较麻烦:
def generator_function2():
# 正常情况应用loop.create_future()
result = yield asyncio.Future()
print('future结果:', result)
return 2
def generator_function():
generator2 = generator_function2()
try:
future = generator2.send(None)
result = yield future
future = generator2.send(result)
except StopIteration as e:
print('generator_function2结果:', e.value)
return 3
def main():
generator = generator_function()
try:
future = generator.send(None)
# 假设某个回调调用了future.set_result
future.set_result(1)
future = generator.send(future.result())
except StopIteration as e:
print('generator_function结果:', e.value)
有了 yield from 的语法糖,可以把流程控制交给子生成器,即子生成器 yield 直接切换上下文到调用者,调用者 send() 直接给子生成器发送数据。
def generator_function2():
# 正常情况应用loop.create_future()
result = yield asyncio.Future()
print('future结果:', result)
return 2
def generator_function():
result = yield from generator_function2()
print('generator_function2结果:', result)
return 3
def main():
generator = generator_function()
try:
future = generator.send(None)
# 假设某个回调调用了future.set_result
future.set_result(1)
future = generator.send(future.result())
except StopIteration as e:
print('generator_function结果:', e.value)
使用yield from的封装
import socket
from selectors import DefaultSelector, EVENT_WRITE, EVENT_READ
selector = DefaultSelector()
stopped = False
urls_todo = {'/', '/1', '/2', '/3', '/4', '/5', '/6', '/7', '/8', '/9'}
def connect(sock, address):
f = Future()
sock.setblocking(False)
try:
sock.connect(address)
except BlockingIOError:
pass
def on_connected():
f.set_result(None)
selector.register(sock.fileno(), EVENT_WRITE, on_connected)
yield from f
selector.unregister(sock.fileno())
def read(sock):
f = Future()
def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield from f
selector.unregister(sock.fileno())
return chunk
def read_all(sock):
response = []
chunk = yield from read(sock)
while chunk:
response.append(chunk)
chunk = yield from read(sock)
return b''.join(response)
class Future:
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for fn in self._callbacks:
fn(self)
def __iter__(self):
yield self
return self.result
class Crawler:
def __init__(self, url):
self.url = url
self.response = b''
def fetch(self):
global stopped
sock = socket.socket()
yield from connect(sock, ('example.com', 80))
get = 'GET {0} HTTP/1.0
Host: example.com
'.format(self.url)
sock.send(get.encode('ascii'))
self.response = yield from read_all(sock)
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
class Task:
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
# send会进入到coro执行, 即fetch, 直到下次yield
# next_future 为yield返回的对象
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
def loop():
while not stopped:
# 阻塞, 直到一个事件发生
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
if __name__ == '__main__':
import time
start = time.time()
for url in urls_todo:
crawler = Crawler(url)
Task(crawler.fetch())
loop()
print(time.time() - start)
asyncio的yield from
使用协程时,你需要使用 yield from 关键字将一个 asyncio.Future 对象向下传递给事件循环,当这个 Future 对象还未就绪时,该协程就暂时挂起以处理其他任务。一旦 Future 对象完成,事件循环将会侦测到状态变化,会将 Future 对象的结果通过 send 方法方法返回给生成器协程,然后生成器恢复工作。Python3.5 中引入了这两个关键字用以取代 asyncio.coroutine 与 yield from,从语义上定义了原生协程关键字,避免了使用者对生成器协程与生成器的混淆。await 的行为类似 yield from,但是它们异步等待的对象并不一致,yield from 等待的是一个生成器对象,而await接收的是定义了__await__方法的 awaitable 对象。
在 Python 中,协程也是 awaitable 对象,collections.abc.Coroutine 对象继承自 collections.abc.Awaitable。
import asyncio
import aiohttp
@asyncio.coroutine
def fetch_page(session, url):
response = yield from session.get(url)
if response.status == 200:
text = yield from response.text()
print(text)
loop = asyncio.get_event_loop()
session = aiohttp.ClientSession(loop=loop)
tasks = [
asyncio.ensure_future(
fetch_page(session, "http://bigsec.com/products/redq/")),
asyncio.ensure_future(
fetch_page(session, "http://bigsec.com/products/warden/"))
]
loop.run_until_complete(asyncio.wait(tasks))
session.close()
loop.close()
在以上的示例代码中,首先实例化一个 eventloop,并将其传递给 aiohttp.ClientSession 使用,这样 session 就不用创建自己的事件循环。
此处显式的创建了两个任务,只有当 fetch_page 取得 api.bigsec.com 两个 url 的数据并打印完成后,所有任务才能结束,然后关闭 session 与 loop,释放连接资源。
当代码运行到 response = yield from session.get(url)处,fetch_page 协程被挂起,隐式的将一个 Future 对象传递给事件循环,只有当 session.get() 完成后,该任务才算完成。
session.get() 内部也是协程,其数据传输位于在存储器山最慢的网络层。当 session.get 完成时,取得了一个 response 对象,再传递给原来的 fetch_page 生成器协程,恢复其工作状态。
为了提高速度,此处 get 方法将取得 http header 与 body 分解成两次任务,减少一次性传输的数据量。response.text() 即是异步请求 http body。
condition
#通过condition完成协同读诗
class XiaoAi(threading.Thread):
def __init__(self, cond):
super().__init__(name="小爱")
self.cond = cond
def run(self):
with self.cond:
self.cond.wait()
print("{} : 在 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 好啊 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 君住长江尾 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 共饮长江水 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 此恨何时已 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 定不负相思意 ".format(self.name))
self.cond.notify()
class TianMao(threading.Thread):
def __init__(self, cond):
super().__init__(name="天猫精灵")
self.cond = cond
def run(self):
with self.cond:
print("{} : 小爱同学 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 我们来对古诗吧 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 我住长江头 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 日日思君不见君 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 此水几时休 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 只愿君心似我心 ".format(self.name))
self.cond.notify()
self.cond.wait()
if __name__ == "__main__":
from concurrent import futures
cond = threading.Condition()
xiaoai = XiaoAi(cond)
tianmao = TianMao(cond)
#启动顺序很重要
#在调用with cond之后才能调用wait或者notify方法
#condition有两层锁, 一把底层锁会在线程调用了wait方法的时候释放, 上面的锁会在每次调用wait的时候分配一把并放入到cond的等待队列中,等到notify方法的唤醒
xiaoai.start()
tianmao.start()
源码解读
import threading, time
class Seeker(threading.Thread):
def __init__(self, cond, name):
super(Seeker, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
print self.name + ': 我已经把眼睛蒙上了'
"""
notify源码解析:
__waiters = self.__waiters
waiters = __waiters[:n] # 获取等待队列中的n个等待锁
for waiter in waiters:
waiter.release() # 释放Hider的等待锁
try:
__waiters.remove(waiter)
except ValueError:
pass
"""
# 释放n个waiter锁,waiter线程准备执行
self.cond.notify()
print('notifyed...')
# 释放condition条件锁,waiter线程Hider真正开始执行
self.cond.wait()
print('waited...')
print self.name + ': 我找到你了 ~_~'
self.cond.notify()
self.cond.release()
print self.name + ': 我赢了'
class Hider(threading.Thread):
def __init__(self, cond, name):
super(Hider, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
"""
wait()源码解析:
waiter = _allocate_lock() # 创建一把等待锁,加入waiters队列,等待notify唤醒
waiter.acquire() # 获取锁
self.__waiters.append(waiter)
saved_state = self._release_save() # 释放condition.lock全局条件锁,以便其他等待线程执行
if timeout is None:
waiter.acquire() # 再次获取锁,因为已经锁定无法继续,等待notify执行release
"""
# wait()释放对琐的占用,同时线程挂起在这里,直到被notify并重新占有琐。
self.cond.wait()
print self.name + ': 我已经藏好了,你快来找我吧'
self.cond.notify()
self.cond.wait()
self.cond.release()
print self.name + ': 被你找到了,哎~~~'
cond = threading.Condition()
hider = Hider(cond, 'hider')
seeker = Seeker(cond, 'seeker')
hider.start()
seeker.start()
hider.join()
seeker.join()
print('end...')