漫画学习hbase----最易懂的Hbase架构原理解析 http://developer.51cto.com/art/201904/595698.htm
1.1 hbase的概念
-
hbase基于Google的BigTable论文,是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统。在需要实时读写随机访问超大规模数据集时,可以使用hbase。
1.2 hbase的特点
-
海量存储
-
可以存储大批量的数据
-
-
列式存储
-
hbase表的数据是基于列族进行存储的,列族是在列的方向上的划分。
-
-
极易扩展
-
底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点服务(机器)就可以了
-
可以通过增加服务器来提高集群的存储能力
-
-
高并发
-
支持高并发的读写请求
-
-
稀疏
-
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
-
-
数据的多版本
-
hbase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
-
-
数据类型单一
-
所有的数据在hbase中是以字节数组进行存储
-
2、hbase整体架构
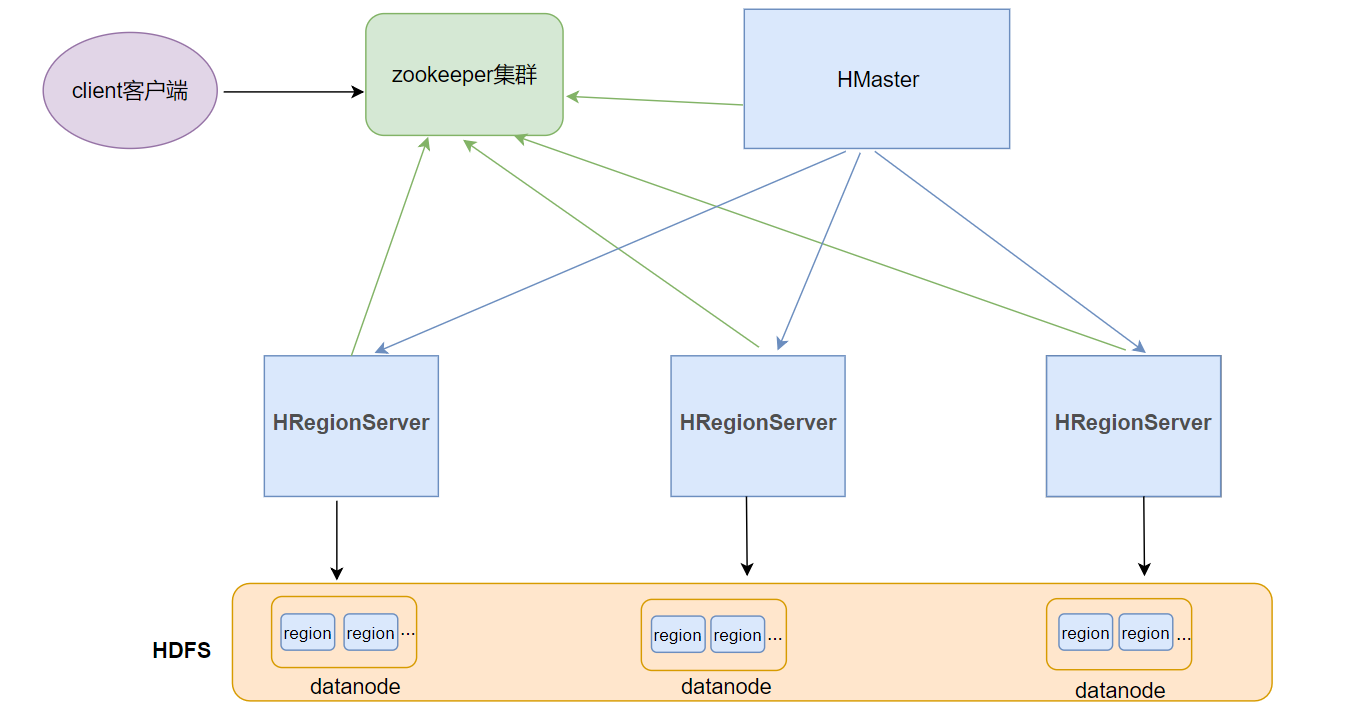

-
1、Client
-
客户端
-
Client包含了访问Hbase的接口
-
另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息
-
-
-
2、Zookeeper
-
zookeeper集群
-
作用
-
实现了HMaster的高可用
-
保存了hbase的元数据信息,是所有hbase表的寻址入口
-
对HMaster和HRegionServer实现了监控
-
-
-
-
3、HMaster
-
hbase集群的老大
-
作用
-
为HRegionServer分配Region
-
维护整个集群的负载均衡
-
维护集群的元数据信息
-
发现失效的Region,并将失效的Region分配到正常的HRegionServer上
-
-
-
-
4、HRegionServer
-
hbase集群中的小弟
-
负责管理Region
-
接受客户端的读写数据请求
-
切分在运行过程中变大的region
-
-
-
5、Region
-
hbase集群中分布式存储的最小单元
3、hbase表的数据模型


-
rowkey
-
行键
-
table的主键,table中的记录按照rowkey 的字典序进行排序
-
-
-
Column Family
-
列族
-
hbase表中的每个列,都归属与某个列族。列族是表的schema的一部分(而列不是),必须在使用表之前定义。
-
-
-
Timestamp
-
时间戳
-
每次数据操作对应的时间戳,可以看作是数据的version number版本号
-
-
-
Column
-
列
-
列族下面的具体列
-
属于某一个ColumnFamily,类似于我们mysql当中创建的具体的列
-
-
-
cell
-
单元格
-
由{row key, column( =<family> + <label>), version} 唯一确定的单元
-
cell中的数据是没有类型的,全部是以字节数组进行存储
-
-