作业①
1)、Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据实验
主函数:
import scrapy
from ..items import BookItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = 'python'
source_url = 'http://search.dangdang.com/'
def start_requests(self):
url = MySpider.source_url + "?key=" + MySpider.key
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
pipelines:
from itemadapter import ItemAdapter
import pymysql
class BookPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123456",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"本书籍")
def process_item(self, item, spider):
try:
if self.opened:
self.count += 1
id = str(self.count)
self.cursor.execute("insert into books (id,bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values( % s, % s, % s, % s, % s, % s, % s)",(id,item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
except Exception as err:
print(err)
return itemitems:
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()settings:
ITEM_PIPELINES = {
'demo.pipelines.BookPipeline': 300,
}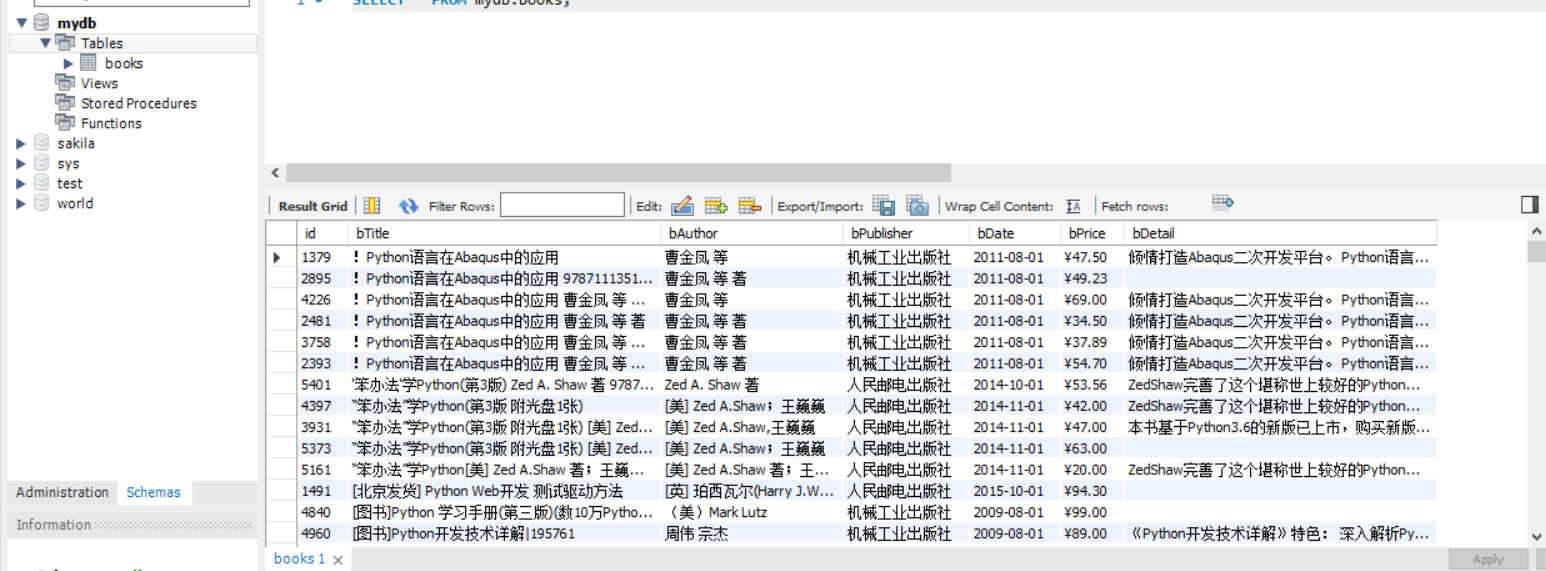
2)、心得体会:
这次实验除了安装和配置mysql遇到点问题,花了很多时间,其他都挺顺利。代码照着书本上打的,主要是用来理解Scrapy+Xpath+MySQL数据库存储的方法。
作业②
1)、Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息实验
主函数:
import scrapy
from selenium import webdriver
from ..items import StockItem
class MySpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
driver = webdriver.Chrome()
try:
driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")
list=driver.find_elements_by_xpath("//table[@class='table_wrapper-table']/tbody/tr")
for li in list:
id=li.find_elements_by_xpath("./td[position()=1]")[0].text
Ticker_symbol=li.find_elements_by_xpath("./td[position()=2]/a")[0].text
stock_name=li.find_elements_by_xpath("./td[position()=3]/a")[0].text
Latest_offer=li.find_elements_by_xpath("./td[position()=5]/span")[0].text
ChangeRate=li.find_elements_by_xpath("./td[position()=6]/span")[0].text
ChangePrice =li.find_elements_by_xpath("./td[position()=7]/span")[0].text
Volume =li.find_elements_by_xpath("./td[position()=8]")[0].text
Turnover =li.find_elements_by_xpath("./td[position()=9]")[0].text
Amplitude =li.find_elements_by_xpath("./td[position()=10]")[0].text
Highest =li.find_elements_by_xpath("./td[position()=11]/span")[0].text
Lowest =li.find_elements_by_xpath("./td[position()=12]/span")[0].text
Open_today =li.find_elements_by_xpath("./td[position()=13]/span")[0].text
Yesterday =li.find_elements_by_xpath("./td[position()=14]")[0].text
item=StockItem()
item["id"]=id
item["Ticker_symbol"]=Ticker_symbol
item["stock_name"]=stock_name
item["Latest_offer"]=Latest_offer
item["ChangeRate"]=ChangeRate
item["ChangePrice"]=ChangePrice
item["Volume"]=Volume
item["Turnover"]=Turnover
item["Amplitude"]=Amplitude
item["Highest"]=Highest
item["Lowest"]=Lowest
item["Open_today"]=Open_today
item["Yesterday"]=Yesterday
yield item
except Exception as err:
print(err)pipelines:
import pymysql
class StockPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS stock")
self.cursor.execute("CREATE TABLE IF NOT EXISTS stock("
"Sid int PRIMARY KEY,"
"Ssymbol VARCHAR(32),"
"Sname VARCHAR(32),"
"Soffer VARCHAR(32),"
"SchangeRate VARCHAR(32),"
"SchangePrice VARCHAR(32),"
"Svolume VARCHAR(32),"
"Sturnover VARCHAR(32),"
"Samplitude VARCHAR(32),"
"Shighest VARCHAR(32),"
"Slowest VARCHAR(32),"
"Stoday VARCHAR(32),"
"Syesterday VARCHAR(32))")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute(
"insert into stock(Sid,Ssymbol,Sname,Soffer,SchangeRate,SchangePrice,Svolume,Sturnover,Samplitude,Shighest,Slowest,Stoday,Syesterday) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(item["id"],item["Ticker_symbol"],item["stock_name"],item["Latest_offer"],item["ChangeRate"],item["ChangePrice"],
item["Volume"],item["Turnover"],item["Amplitude"],item["Highest"],item["Lowest"],item["Open_today"],item["Yesterday"]))
except Exception as err:
print(err)
return itemitems:
import scrapy
class StockItem(scrapy.Item):
id=scrapy.Field()
Ticker_symbol=scrapy.Field()
stock_name=scrapy.Field()
Latest_offer=scrapy.Field()
ChangeRate=scrapy.Field()
ChangePrice=scrapy.Field()
Volume=scrapy.Field()
Turnover=scrapy.Field()
Amplitude=scrapy.Field()
Highest=scrapy.Field()
Lowest=scrapy.Field()
Open_today=scrapy.Field()
Yesterday=scrapy.Field()
passsettings:
ITEM_PIPELINES = {
'stock.pipelines.StockPipeline': 300,
}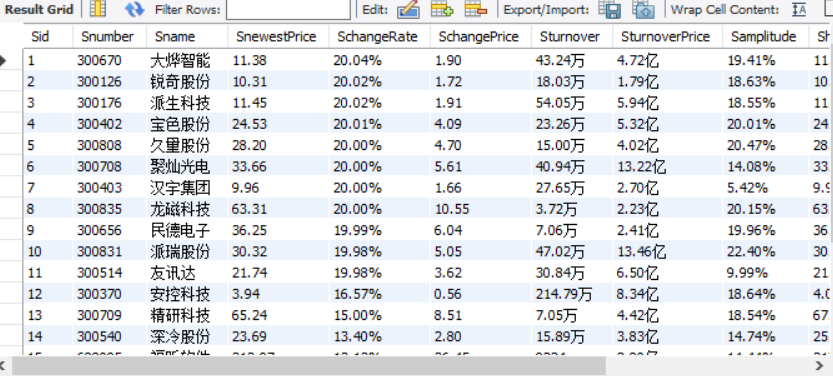
2)、心得体会:
本来以为安装chrome驱动程序会比较繁琐,没想到根据ppt和网上的教程,弄了几分钟就一次性成功了。这次实验还是爬取股票,已经算是挺熟悉的了,不过上次实验因为时间紧,没有用xpath,所以这次多花了些时间换成使用xpath进行爬取。刚开始觉得scrapy框架很麻烦,但随着使用次数的增加,我觉得自己差不多习惯使用它,也越发熟练了。
作业③
1)、使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据实验
主函数:
import scrapy
from bs4 import UnicodeDammit
from ..items import BankItem
class mySider(scrapy.spiders.Spider):
name = "bank"
source_url = 'http://fx.cmbchina.com/hq/'
def start_requests(self):
url = mySider.source_url
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
table = selector.xpath("//div[@class='box hq']/div[@id='realRateInfo']/table[@class='data']")
trs=table.xpath("./tr")
for tr in trs[1:]:
Currency= tr.xpath("./td[position()=1]/text()").extract_first()
TSP= tr.xpath("./td[position()=4]/text()").extract_first()
CSP= tr.xpath("./td[position()=5]/text()").extract_first()
TBP= tr.xpath("./td[position()=6]/text()").extract_first()
CBP= tr.xpath("./td[position()=7]/text()").extract_first()
Time= tr.xpath("./td[position()=8]/text()").extract_first()
item=BankItem()
item["Currency"]=Currency.strip() if Currency else ""
item["TSP"]=TSP.strip() if TSP else ""
item["CSP"]=CSP.strip() if CSP else ""
item["TBP"]=TBP.strip() if TBP else ""
item["CBP"]=CBP.strip() if CBP else ""
item["Time"]=Time.strip() if Time else ""
yield item
except Exception as err:
print(err)pipelines:
import pymysql
from itemadapter import ItemAdapter
class BankPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS bank")
self.cursor.execute("CREATE TABLE IF NOT EXISTS bank("
"id int PRIMARY KEY,"
"Currency VARCHAR(32),"
"TSP VARCHAR(32),"
"CSP VARCHAR(32),"
"TBP VARCHAR(32),"
"CBP VARCHAR(32),"
"TIME VARCHAR(32))")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条信息")
def process_item(self, item, spider):
try:
print(item)
if self.opened:
self.count += 1
self.cursor.execute(
"insert into bank(id,Currency,TSP,CSP,TBP,CBP,Time) values(%s,%s,%s,%s,%s,%s,%s)",
(self.count, item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
except Exception as err:
print(err)
return itemitems:
import scrapy
class BankItem(scrapy.Item):
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()settings:
ITEM_PIPELINES = {
'bank.pipelines.BankPipeline': 300,
}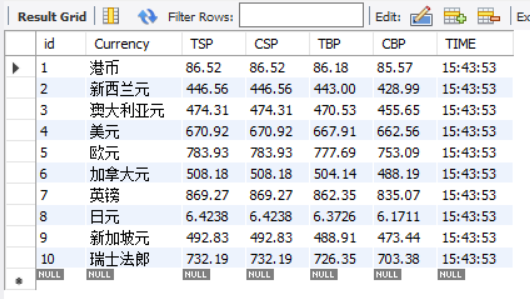
2)、心得体会:
这次实验挺容易的,在相应网站上的资源管理器里找到所要爬取的信息,套入上面两题的模板就成功了。