基于flink1.14的源码做解析
公司内有很多业务方都在使用我们Flink sql平台做TopN的计算,今天同事突然问到我,Flink sql 是怎么实现topN的 ?
蒙圈了,这块源码没看过啊 ,业务要问起来怎么办,赶快打开源码补一下
拿到这个问题先冷静分析一下范围
首先肯定属于Flink sql模块,源码里面肯定是在flink-table-planner包里面,接着topN那不就是ROW_NUMBER嘛,是个函数呀
既然如此那就从flink源码的系统函数作为线索开始找起来,来到 org.apache.calcite.sql.fun.SqlStdOperatorTable类
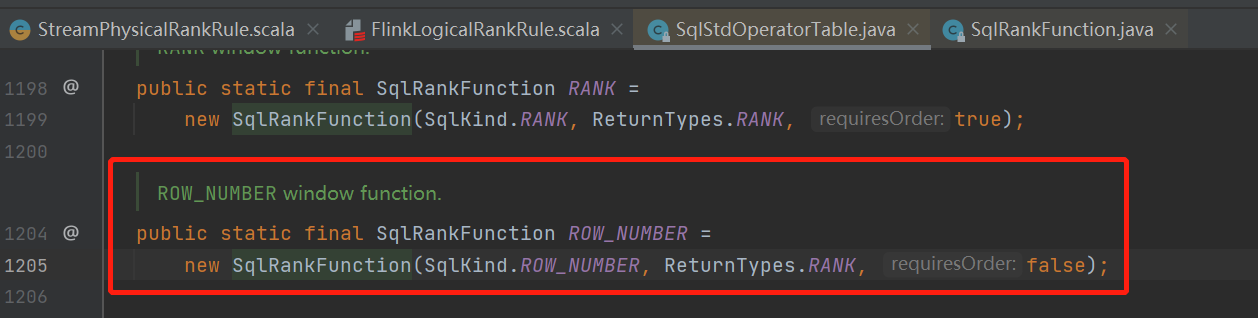
果然找到了,那calcite的某个rule肯定有个地方判断了它,继续查调用链
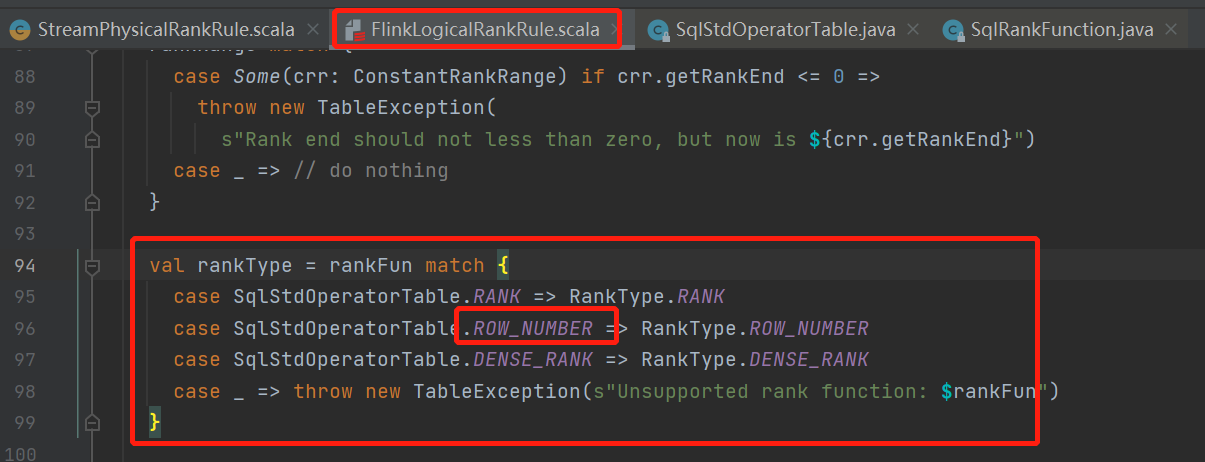
不出所料,FlinkLogicalRankRuleBase这个calcite的rule里面果然根据这个function的类型来确定rank的类型了
看下这个rule的匹配条件

这里也好理解,overAgg的时候会判断这个rank以及对应的类型
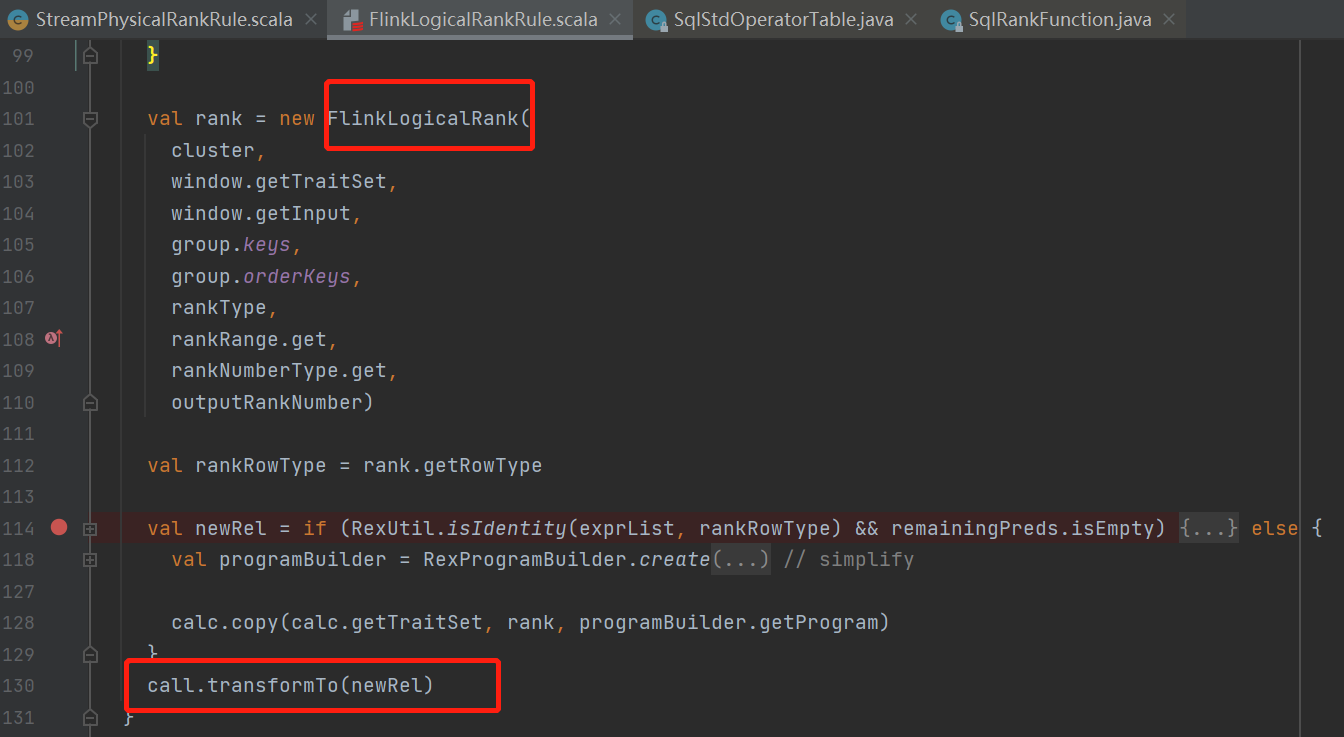
这是只是做了一下简单的提取了rank的字段啊,提取谓语啊,提取表达式啊这一些拿信息的操作
然后直接生成新的relNode叫FlinkLogicalRank通过transformTo直接返回了这个等价节点
既然是relNode那肯定又会有calcite的rule去处理它,来找一找
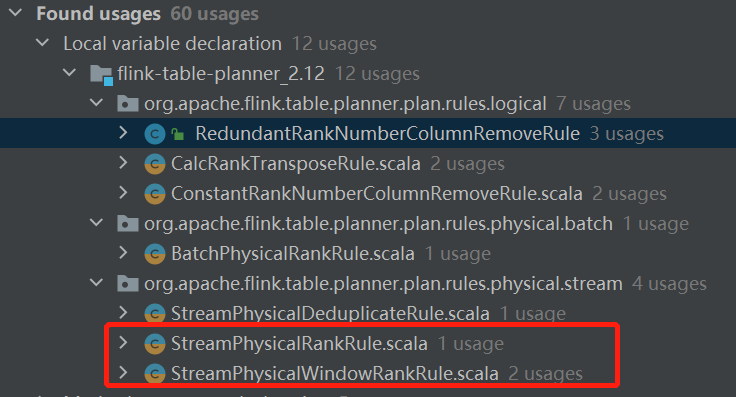
批处理的就不管了,从名字就可以看出来我们要找的类了
看个不带window的吧
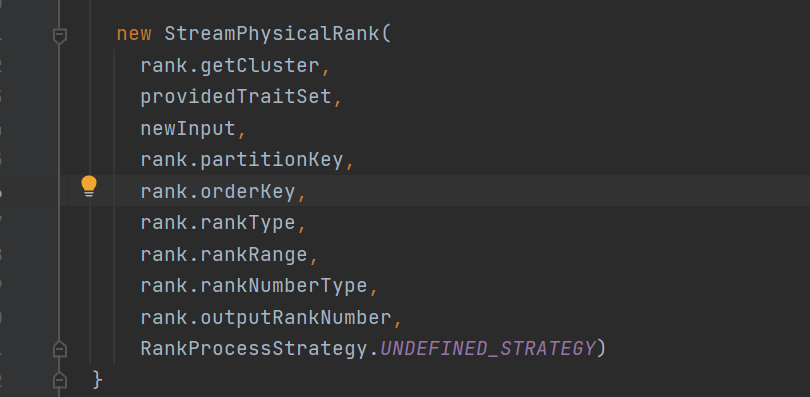
返回StreamPhysicalRank
这个类是一个FlinkPhysicalRel是可以转换成execNode的
这里在多说一句,
这里将partitionKey传入了,就是sql里面的partition by后面的,后面会用这个来创建transformation的keySelecter用来分流数据
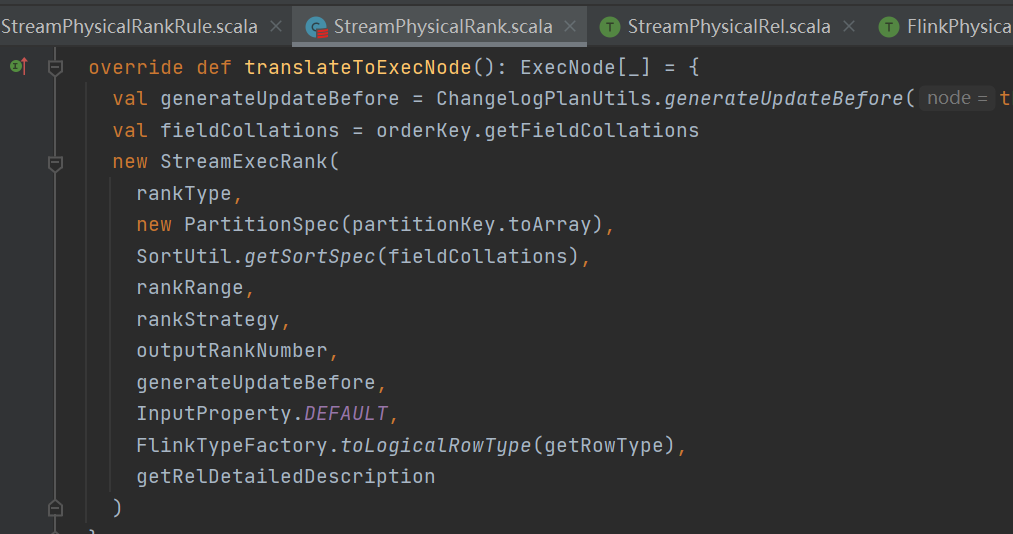
返回的这个StreamExecRank就是可以转换成具体的Flink的算子了,具体逻辑就在里面了
接下来看下row_number的具体逻辑,找到方法translateToPlanInternal
根据策略主要分为三种类型
AppendFastStrategy (输入仅包含插入时)
RetractStrategy (输入包含update和delete)
UpdateFastStrategy (输入不应包含删除且输入有给定的primaryKeys且按字段排序时)
来看个retractStrategy的吧
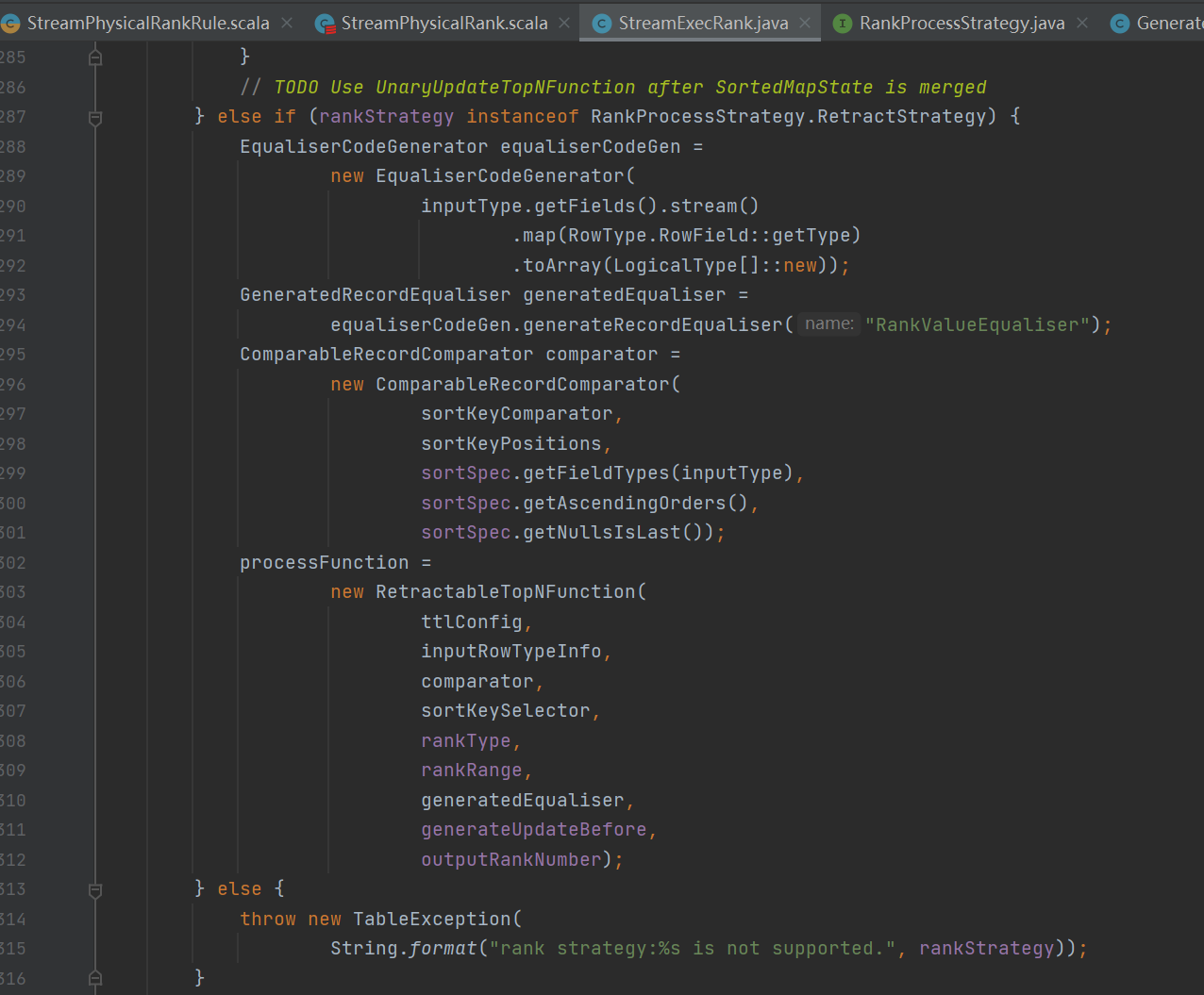
先通过sort的字段获取一个用于排序RowData的比较器 ComparableRecordComparator
根据比较器创建 RetractableTopNFunction
这个类还有两个主要的状态数据结构
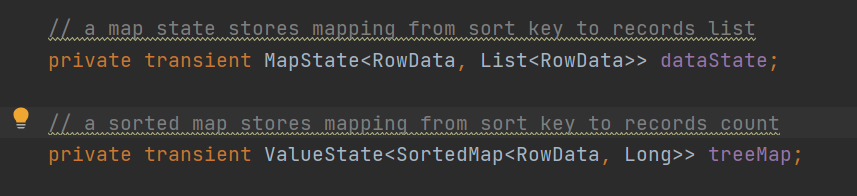
dataState这个map用来存放当key相同的所有数据会放在同一个list里面
treeMap这个可排序的map就是通过上面我们sql里面定义的sort by 来排序数据的,Long是指这个相同的key有多少个record
!!!!!!!!!!! 那就是用java的treeMap排序呗
继续往下看
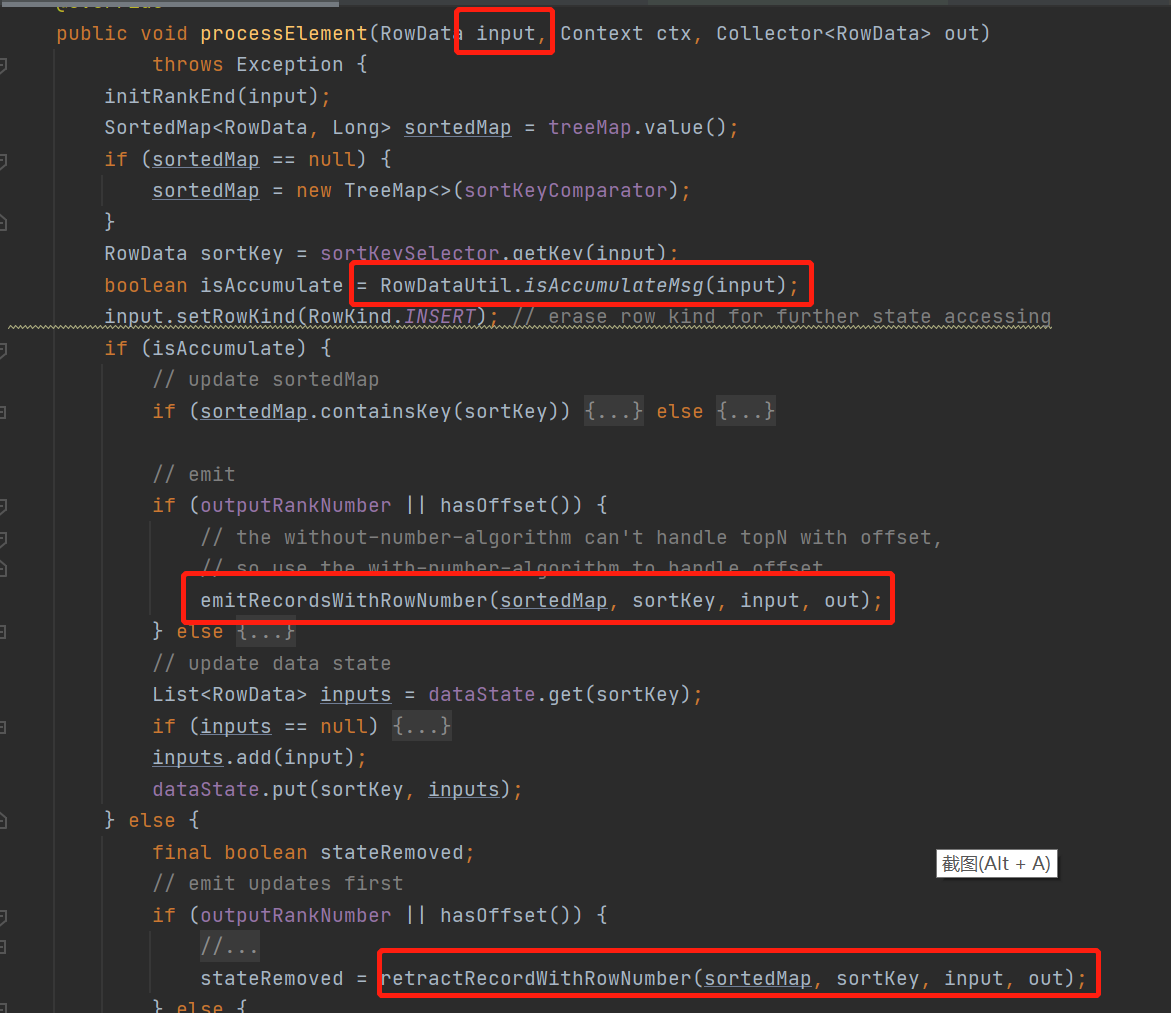
主逻辑就是这个了
每进入一条数据,会根据这条数据的类型划分
当数据是Insert , UPDATE_AFTER类型是会走 emitRecordsWithRowNumber()方法
当数据是UPDATE_BEFORE,DELETE类型会走 retractRecordWithRowNumber ()方法
来看下具体逻辑先看INSERT的
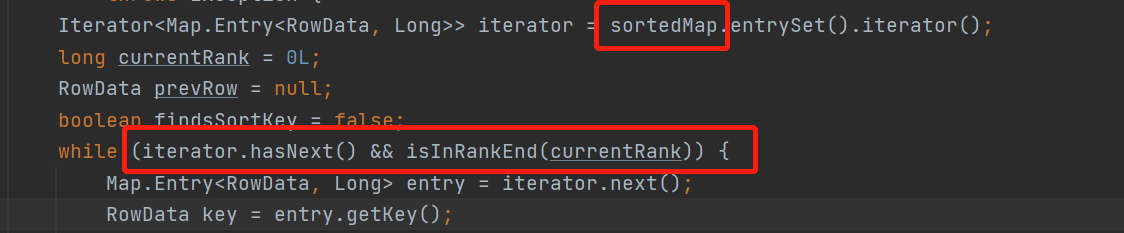
遍历treeMap
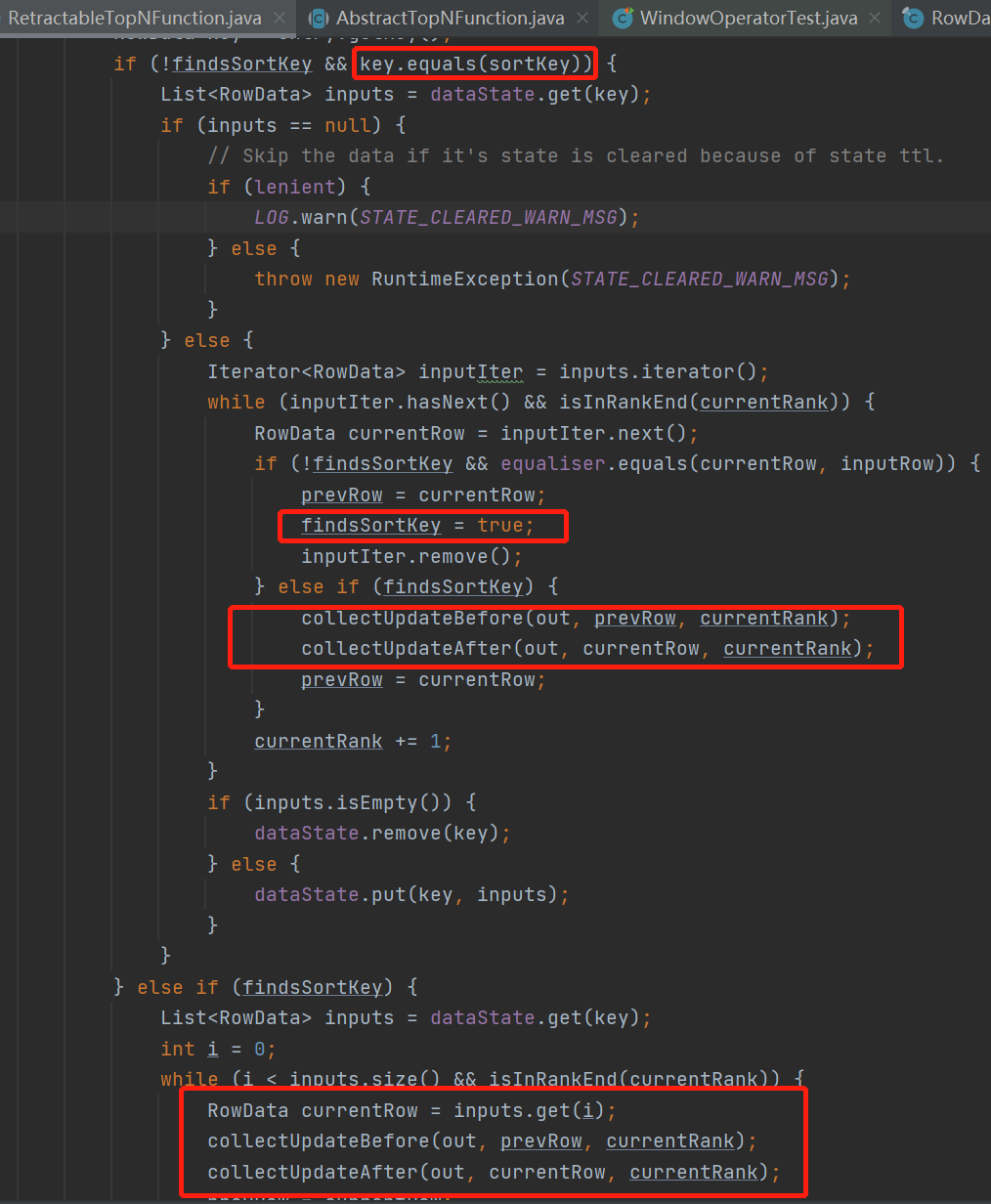
解读一下,当数据是insert数据的时候
INSERT数据会先放到treeMap里面去,delete则不会
按顺序遍历treeMap
当遍历过程中发现遍历的key与当前数据的key相同时,和当前数据key相同的所有数据数据(dataState中的LIST),全部撤回并且更新他们的rowNumber+1
继续遍历treeMap
之后的数据全部撤回UpdateBefore,并且向下游发送UpdateAfter使rowNumber+1,遍历直到已经到第TopN个数据循环结束
当数据是DELETE类型的时候,会和Insert反过来,当前key之后的数据全部撤回,然后rowNumber-1
整个处理流程差不多就结束了,可以看到rowNumber当N较大且排序变化频繁的时候,性能消耗还是非常大的,极端情况下游的数据会翻很多倍
这个还需要注意在其他两个策略中还有一个参数,table.exec.topn.cache-size

影响下面这个本地lruCache的大小

调大可以减少状态的访问,可以按需要添加