视频版地址B站:从零开始写代码 Python ID3决策树算法分析与实现_哔哩哔哩_bilibili




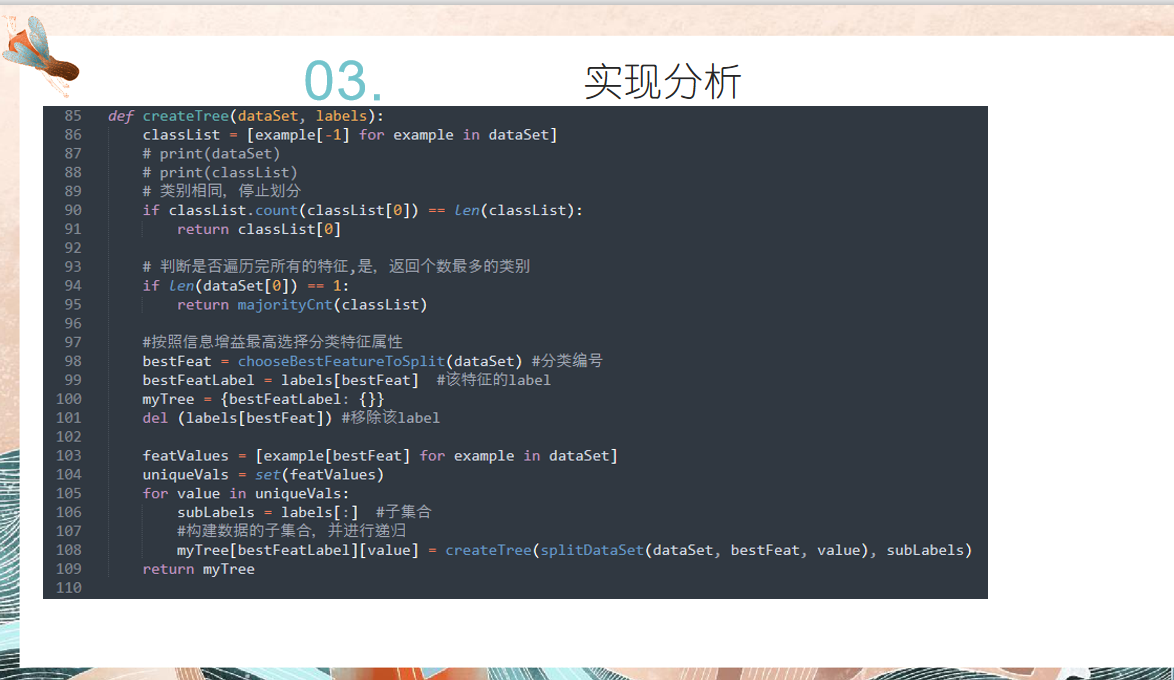

代码如下:
# author:会武术之白猫 # date:2021-11-6 import math def createDataSet(): # dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] # labels = ['no sufacing', 'flippers'] dataSet = [ [1,1,2,0,1,1,0,'感冒'], [2,0,3,2,0,2,2,'流感'], [3,0,0,1,1,1,1,'流感'], [0,0,1,1,1,0,1,'感冒'], [3,1,2,2,0,2,2,'流感'], [0,1,2,0,1,0,0,'感冒'], [2,0,2,2,0,2,2,'流感'], [0,1,3,0,0,1,1,'感冒']] labels = ['发冷','喉咙痛','咳嗽','头痛','鼻塞','疲劳','发烧'] return dataSet, labels def calcShannonEnt(dataSet): numEntries = len(dataSet) # 为分类创建字典 labelCounts = {} for featVec in dataSet: currentLabel = featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts.setdefault(currentLabel, 0) labelCounts[currentLabel] += 1 # 计算香农墒 shannonEnt = 0.0 for key in labelCounts: prob = float(labelCounts[key]) / numEntries shannonEnt += prob * math.log2(1 / prob) return shannonEnt # 定义按照某个特征进行划分的函数 splitDataSet # 输入三个变量(带划分数据集, 特征,分类值) def splitDataSet(dataSet, axis, value): retDataSet = [] for featVec in dataSet: if featVec[axis] == value: reduceFeatVec = featVec[:axis] reduceFeatVec.extend(featVec[axis + 1:]) retDataSet.append(reduceFeatVec) return retDataSet #返回不含划分特征的子集 # 定义按照最大信息增益划分数据的函数 def chooseBestFeatureToSplit(dataSet): numFeature = len(dataSet[0]) - 1 baseEntropy = calcShannonEnt(dataSet) bestInforGain = 0 bestFeature = -1 for i in range(numFeature): featList = [number[i] for number in dataSet] #得到某个特征下所有值 uniqualVals = set(featList) #set无重复的属性特征值 newEntrogy = 0 #求和 for value in uniqualVals: subDataSet = splitDataSet(dataSet, i, value) prob = len(subDataSet) / float(len(dataSet)) #即p(t) newEntrogy += prob * calcShannonEnt(subDataSet) #对各子集求香农墒 infoGain = baseEntropy - newEntrogy #计算信息增益 #print(infoGain) # 最大信息增益 if infoGain > bestInforGain: bestInforGain = infoGain bestFeature = i return bestFeature # 投票表决代码 def majorityCnt(classList): classCount = {} for vote in classList: if vote not in classCount.keys(): classCount.setdefault(vote, 0) classCount[vote] += 1 sortedClassCount = sorted(classCount.items(), key=lambda i:i[1], reverse=True) return sortedClassCount[0][0] def createTree(dataSet, labels): classList = [example[-1] for example in dataSet] # print(dataSet) # print(classList) # 类别相同,停止划分 if classList.count(classList[0]) == len(classList): return classList[0] # 判断是否遍历完所有的特征,是,返回个数最多的类别 if len(dataSet[0]) == 1: return majorityCnt(classList) #按照信息增益最高选择分类特征属性 bestFeat = chooseBestFeatureToSplit(dataSet) #分类编号 bestFeatLabel = labels[bestFeat] #该特征的label myTree = {bestFeatLabel: {}} del (labels[bestFeat]) #移除该label featValues = [example[bestFeat] for example in dataSet] uniqueVals = set(featValues) for value in uniqueVals: subLabels = labels[:] #子集合 #构建数据的子集合,并进行递归 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels) return myTree def classify(inputTree, featLabels, testVec): """ :param inputTree: 决策树 :param featLabels: 属性特征标签 :param testVec: 测试数据 :return: 所属分类 """ firstStr = list(inputTree.keys())[0] #树的第一个属性 sendDict = inputTree[firstStr] featIndex = featLabels.index(firstStr) classLabel = None for key in sendDict.keys(): if testVec[featIndex] == key: if type(sendDict[key]).__name__ == 'dict': classLabel = classify(sendDict[key], featLabels, testVec) else: classLabel = sendDict[key] return classLabel if __name__ == '__main__': dataSet, labels = createDataSet() r = chooseBestFeatureToSplit(dataSet) #print(r) myTree = createTree(dataSet, labels) print(myTree) # --> {'no sufacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}} res = classify(myTree, ['发冷','喉咙痛','咳嗽','头痛','鼻塞','疲劳','发烧'], [1,1,2,0,1,1,0]) print(res)