一、redis的准备。
下载redis:路径:Linux:http://www.redis.io.com
window:http://www.newasp.net/soft/67186.html
解压后,有5个应用程序:
redis-server.exe:服务程序
redis-cli.exe:简单测试
redis-check-dump.exe:本地数据库检查
redis-check-aof.exe:更新日志检查
redis-benchmark.exe:性能测试,用以模拟同时由N个客户端发送M个 SETs/GETs 查询 (类似于 Apache 的ab 工具).
在当前文件夹下创建文件redis.conf,文件内容:
# Redis configuration file example
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
daemonize no
# When run as a daemon, Redis write a pid file in /var/run/redis.pid by default.
# You can specify a custom pid file location here.
pidfile /var/run/redis.pid
# Accept connections on the specified port, default is 6379
port 6379
# If you want you can bind a single interface, if the bind option is not
# specified all the interfaces will listen for connections.
#
# bind 127.0.0.1
# Close the connection after a client is idle for N seconds (0 to disable)
timeout 300
# Set server verbosity to 'debug'
# it can be one of:
# debug (a lot of information, useful for development/testing)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel debug
# Specify the log file name. Also 'stdout' can be used to force
# the demon to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile stdout
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
databases 16
################################ SNAPSHOTTING #################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
save 900 1
save 300 10
save 60 10000
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
# The filename where to dump the DB
dbfilename dump.rdb
# For default save/load DB in/from the working directory
# Note that you must specify a directory not a file name.
dir ./
################################# REPLICATION #################################
# Master-Slave replication. Use slaveof to make a Redis instance a copy of
# another Redis server. Note that the configuration is local to the slave
# so for example it is possible to configure the slave to save the DB with a
# different interval, or to listen to another port, and so on.
#
# slaveof <masterip> <masterport>
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the slave to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the slave request.
#
# masterauth <master-password>
################################## SECURITY ###################################
# Require clients to issue AUTH <PASSWORD> before processing any other
# commands. This might be useful in environments in which you do not trust
# others with access to the host running redis-server.
#
# This should stay commented out for backward compatibility and because most
# people do not need auth (e.g. they run their own servers).
#
# requirepass foobared
################################### LIMITS ####################################
# Set the max number of connected clients at the same time. By default there
# is no limit, and it's up to the number of file descriptors the Redis process
# is able to open. The special value '0' means no limts.
# Once the limit is reached Redis will close all the new connections sending
# an error 'max number of clients reached'.
#
# maxclients 128
# Don't use more memory than the specified amount of bytes.
# When the memory limit is reached Redis will try to remove keys with an
# EXPIRE set. It will try to start freeing keys that are going to expire
# in little time and preserve keys with a longer time to live.
# Redis will also try to remove objects from free lists if possible.
#
# If all this fails, Redis will start to reply with errors to commands
# that will use more memory, like SET, LPUSH, and so on, and will continue
# to reply to most read-only commands like GET.
#
# WARNING: maxmemory can be a good idea mainly if you want to use Redis as a
# 'state' server or cache, not as a real DB. When Redis is used as a real
# database the memory usage will grow over the weeks, it will be obvious if
# it is going to use too much memory in the long run, and you'll have the time
# to upgrade. With maxmemory after the limit is reached you'll start to get
# errors for write operations, and this may even lead to DB inconsistency.
#
# maxmemory <bytes>
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. If you can live
# with the idea that the latest records will be lost if something like a crash
# happens this is the preferred way to run Redis. If instead you care a lot
# about your data and don't want to that a single record can get lost you should
# enable the append only mode: when this mode is enabled Redis will append
# every write operation received in the file appendonly.log. This file will
# be read on startup in order to rebuild the full dataset in memory.
#
# Note that you can have both the async dumps and the append only file if you
# like (you have to comment the "save" statements above to disable the dumps).
# Still if append only mode is enabled Redis will load the data from the
# log file at startup ignoring the dump.rdb file.
#
# The name of the append only file is "appendonly.log"
#
# IMPORTANT: Check the BGREWRITEAOF to check how to rewrite the append
# log file in background when it gets too big.
appendonly no
# The fsync() call tells the Operating System to actually write data on disk
# instead to wait for more data in the output buffer. Some OS will really flush
# data on disk, some other OS will just try to do it ASAP.
#
# Redis supports three different modes:
#
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log . Slow, Safest.
# everysec: fsync only if one second passed since the last fsync. Compromise.
#
# The default is "always" that's the safer of the options. It's up to you to
# understand if you can relax this to "everysec" that will fsync every second
# or to "no" that will let the operating system flush the output buffer when
# it want, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting).
appendfsync always
# appendfsync everysec
# appendfsync no
############################### ADVANCED CONFIG ###############################
# Glue small output buffers together in order to send small replies in a
# single TCP packet. Uses a bit more CPU but most of the times it is a win
# in terms of number of queries per second. Use 'yes' if unsure.
glueoutputbuf yes
# Use object sharing. Can save a lot of memory if you have many common
# string in your dataset, but performs lookups against the shared objects
# pool so it uses more CPU and can be a bit slower. Usually it's a good
# idea.
#
# When object sharing is enabled (shareobjects yes) you can use
# shareobjectspoolsize to control the size of the pool used in order to try
# object sharing. A bigger pool size will lead to better sharing capabilities.
# In general you want this value to be at least the double of the number of
# very common strings you have in your dataset.
#
# WARNING: object sharing is experimental, don't enable this feature
# in production before of Redis 1.0-stable. Still please try this feature in
# your development environment so that we can test it better.
# shareobjects no
# shareobjectspoolsize 1024
二、redis的安装。
1、打开cmd窗口,切换到redis目录,执行redis-service.exe应用程序。

出现如上图表示已经启动
2、再次打开新的cmd窗口,切换到redis目录。
输入redis-cli.exe -h 192.168.0.222 -p 6379命令,192.168.0.222为本机地址,6379为redis端口。
输入set ket value格式数据、get key用来取出保存的数据,如图: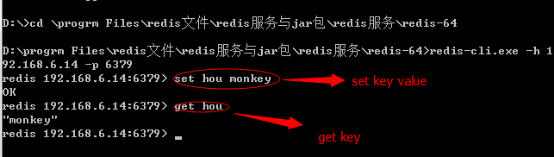
到此为止安装、测试成功。
注:不要关闭执行redis-service.exe应用程序的窗口,否则redis服务停止。
三、与程序结合。
需导入的jar包。
commons-pool-1.6.jar和jedis-2.4.2.jar
注:jedis 2.4版本前后有改动,表象上看就是没有maxActive和maxWait,换成了maxTotal和maxWaitMillis。
http://www.zyiqibook.com/article225.html
然后写了测试的小例子:
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.set("key01", "value01");
String value = jedis.get("key01");
System.out.println(value);
}
四、spring集成redis
1、需要导入jar包。
commons-pool2-2.2.jar和spring-data-redis-1.6.2.RELEASE.jar
2、然后在spring-mvc.xml下配置,
<context:property-placeholder location="classpath:redis.properties"/>
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="maxIdle" value="${redis.maxIdle}" />
<!-- 如果jar包 jedic的版本在2.4以下 -->
<property name="maxActive" value="${redis.maxActive}" />
<property name="maxWait" value="${redis.maxWait}" />
<!-- 如果jar包 jedic的版本在2.4及以上 -->
<property name="maxTotal" value="${redis.maxActive}" />
<property name="maxWaitMillis" value="${redis.maxWait}" />
<property name="testOnBorrow" value="${redis.testOnBorrow}" />
</bean>
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<property name="hostName" value="${redis.host}" />
<property name="port" value="${redis.port}" />
<property name="password" value="${redis.pass}" />
<property name="poolConfig" ref="poolConfig" />
</bean>
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="connectionFactory" />
</bean>
redis.properties文件内容如下:
redis.host=127.0.0.1
redis.port=6379
redis.pass=
redis.maxIdle=300
redis.maxActive=600
redis.maxWait=1000
redis.testOnBorrow=true
3、dao层注入及基本方法。
@Autowired
private RedisTemplate<K, V> redisTemplate;
public void setRedisTemplate(RedisTemplate<K, V> redisTemplate) {
this.redisTemplate = redisTemplate;
}
protected RedisSerializer<String> getRedisSerializer(){
return redisTemplate.getStringSerializer();
}
/**
* 添加
*/
@Override
public boolean add(final ExamList exam) throws Exception {
boolean result=redisTemplate.execute(new RedisCallback<Boolean>() {
@Override
public Boolean doInRedis(RedisConnection connection)
throws DataAccessException {
RedisSerializer<String> serializer =getRedisSerializer();
byte[] key = serializer.serialize("exam");
byte[] user1=null;
try {
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream oo = new ObjectOutputStream(bo);
oo.writeObject(exam);
user1 = bo.toByteArray();
bo.close();
oo.close();
} catch (Exception e) {
e.printStackTrace();
}
connection.append(key, user1);
return true;
}
});
return result;
}
/**
* 查询
*/
@Override
public ExamList getObj(final String string) throws Exception {
ExamList result=redisTemplate.execute(new RedisCallback<ExamList>() {
@Override
public ExamList doInRedis(RedisConnection connection)
throws DataAccessException {
RedisSerializer<String> serializer =getRedisSerializer();
byte[] key = serializer.serialize(string);
byte[] value = connection.get(key);
if(value==null){
return null;
}
ExamList user=null;
try {
ByteArrayInputStream bi = new ByteArrayInputStream(value);
ObjectInputStream oi = new ObjectInputStream(bi);
user = (ExamList)oi.readObject();
bi.close();
oi.close();
} catch (Exception e) {
e.printStackTrace();
}
return user;
}
});
return result;
}