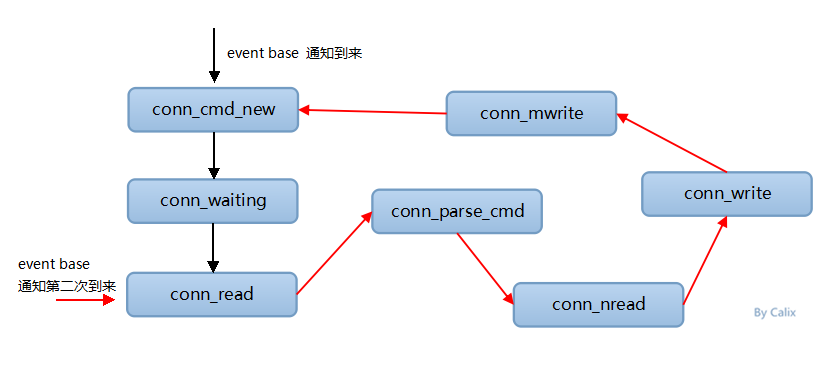
整体流程
1. 当客户端和Memcached建立TCP连接后,Memcached会基于Libevent的event事件来监听客户端是否有可以读取的数据。
2. 当客户端有命令数据报文上报的时候,就会触发drive_machine方法中的conn_read这个Case。
3. memcached通过try_read_network方法读取客户端的报文。如果读取失败,则返回conn_closing,去关闭客户端的连接;如果没有读取到任何数据,则会返回conn_waiting,继续等待客户端的事件到来,并且退出drive_machine的循环;如果数据读取成功,则会将状态转交给conn_parse_cmd处理,读取到的数据会存储在c->rbuf容器中。
4. conn_parse_cmd主要的工作就是用来解析命令。主要通过try_read_command这个方法来读取c->rbuf中的命令数据,通过 来分隔数据报文的命令。如果c->buf内存块中的数据匹配不到 ,则返回继续等待客户端的命令数据报文到来conn_waiting;否则就会转交给process_command方法,来处理具体的命令(命令解析会通过�符号来分隔)。
5. process_command主要用来处理具体的命令。其中tokenize_command这个方法非常重要,将命令拆解成多个元素(KEY的最大长度250)。例如我们以get命令为例,最终会跳转到process_get_command这个命令 process_*_command这一系列就是处理具体的命令逻辑的。
6. 我们进入process_get_command,当获取数据处理完毕之后,会转交到conn_mwrite这个状态。如果获取数据失败,则关闭连接。
7. 进入conn_mwrite后,主要是通过transmit方法来向客户端提交数据。如果写数据失败,则关闭连接或退出drive_machine循环;如果写入成功,则又转交到conn_new_cmd这个状态。
8. conn_new_cmd这个状态主要是处理c->rbuf中剩余的命令。主要看一下reset_cmd_handler这个方法,这个方法回去判断c->rbytes中是否还有剩余的报文没处理,如果未处理,则转交到conn_parse_cmd(第四步)继续解析剩余命令;如果已经处理了,则转交到conn_waiting,等待新的事件到来。在转交之前,每次都会执行一次conn_shrink方法。
9. conn_shrink方法主要用来处理命令报文容器c->rbuf和输出内容的容器是否数据满了?是否需要扩大buffer的大小,是否需要移动内存块。接受命令报文的初始化内存块大小2048,最大8192。
状态变迁
状态机drive_machine函数是worker线程网络请求进行业务逻辑处理的核心。
它的实现方式是:
一个while循环里面有一个巨大的switch case,根据连接对象 conn当前的连接状态conn_state,进入不同的case,而每个case可能会改变conn的连接状态,也就是说在这个while+switch中,conn会不断的发生状态转移,最后被分发到合适的case上作处理。可以理解为,这里是一个有向图,每个case是一个顶点,有些case通过改变conn对象的连接状态让程序在下一次循环中进入另一个case,几次循环后程序最终进入到“无出度的顶点”然后结束状态机,这里的无出度的顶点就是带设置stop=true的case分支。
看下大概的代码结构:
1 static void drive_machine(conn *c) { 2 while (!stop) { 3 switch(c->state) { 4 case conn_listening: 5 //...... 6 case conn_waiting: 7 //...... 8 stop = true; break; 9 //...... 10 } 11 } 12 }
主线程状态机的行为我们已经知道了,永远只会是conn_listening状态,永远只会进入drive_machine的conn_listening分支,accept连接把client fd 通过dispatch_conn_new函数分发给worker线程。
下面我们来看一下worker线程执行状态机:
当主线程调用dispatch_conn_new的时候,worker线程创建conn对象,初始状态为conn_new_cmd。所以当有worker线程监听的client fd有请求过来时,例如客户端发了一行命令(set xxx )会进入conn_new_cmd分支:
1 case conn_new_cmd: 2 /* 3 这里的reqs是请求的意思,其实叫“命令”更准确。一次event发生,有可能包含多个命令, 4 从client fd里面read到的一次数据,不能保证这个数据只是包含一个命令,有可能是多个 5 命令数据堆在一起的一次事件通知。这个nreqs是用来控制一次event最多能处理多少个命令。 6 */ 7 --nreqs; 8 if (nreqs >= 0) { 9 /** 10 准备执行命令。为什么叫reset cmd,reset_cmd_handler其实做了一些解析执行命令之前 11 的初始化动下一个,都会重新进入这个case作。而像上面说的,一次event有可能有多个命令,每执行一个命令,如果还有 12 conn_new_cmd,reset一下再执行下一个命令。 13 */ 14 reset_cmd_handler(c); 15 } else { 16 //...... 17 } 18 break;
当client fd第一次有请求过来的时候,会进入reset_cmd_handler函数:
1 static void reset_cmd_handler(conn *c) { 2 c->cmd = -1; 3 c->substate = bin_no_state; 4 if(c->item != NULL) { 5 item_remove(c->item); 6 c->item = NULL; 7 } 8 conn_shrink(c); 9 10 //第一次有请求过来触发到此函数时,c->rbytes为0 11 if (c->rbytes > 0) { 12 conn_set_state(c, conn_parse_cmd); 13 } else { 14 conn_set_state(c, c 15 onn_waiting); //第一次请求进入此分支 16 } 17 }
我们在conn_new函数里面把c->rbytes被始化为0,而直至此我们也没有看到这个c->rbytes有被重新赋新值,所以其实第一次有请求过来,这个值还是0,所以进入else分支,即执行conn_set_state(c,conn_waiting);然后重新回到状态机执行下一次循环,进入conn_waiting分支:
1 case conn_waiting: 2 if (!update_event(c, EV_READ | EV_PERSIST)) { 3 //。。。 4 } 5 conn_set_state(c, conn_read); 6 stop = true; 7 break;
在conn_waiting分支你会发现,这里的代码仅仅是把状态改变conn_read然后就stop=true,结束状态机了!没错,退出while循环了!这次事件触发就此结束了!你会觉得很奇怪,我客户端明明发了一个请求,(set xxx ),你什么都没处理就只是把连接状态改成conn_read就完事了?!没错,至少这一次状态机的执行行为是这样!
到底是怎么回事?其实这里是利用了一点:libevent的epoll默认是“水平触发”!也就是说,客户端发来一个set xxx ,我这边一天没有read,epoll还会有下一次通知,也就是说,这个请求有两次事件通知!第一次通知的作用仅是为了把连接状态改为conn_read! 当worker线程因为同一个client fd同一个请求收到第二次通知的时候,再次执行状态机,然后进入conn_read分支。
1 //读取事件 2 //例如有用户提交数据过来的时候,工作线程监听到事件后,最终会调用这块代码 3 //读取数据的事件,当客户端有数据报文上传的时候,就会触发libevent的读事件 4 case conn_read: 5 //try_read_network 主要读取TCP数据 6 //返回try_read_result的枚举类型结构,通过这个枚举类型,来判断是否已经读取到数据,是否读取失败等情况 7 res = IS_UDP(c->transport) ? try_read_udp(c) :try_read_network(c); 8 9 switch (res) { 10 //没有读取到数据,那么继续将事件设置为等待。 11 //while(stop)会继续循环,去调用conn_waiting这个case 12 case READ_NO_DATA_RECEIVED: 13 conn_set_state(c, conn_waiting); 14 break; 15 //如果有数据读取到了,这个时候就需要调用conn_parse_cmd逻辑 16 //conn_parse_cmd:主要用来解析读取到的命令 17 case READ_DATA_RECEIVED: 18 conn_set_state(c, conn_parse_cmd); 19 break; 20 //读取失败的状态,则直接调用conn_closing 关闭客户端的连接 21 case READ_ERROR: 22 conn_set_state(c, conn_closing); 23 break; 24 case READ_MEMORY_ERROR: /* Failed to allocate more memory */ 25 /* State already set by try_read_network */ 26 break; 27 } 28 break;
进入conn_read此时才调用函数try_read_network函数读出请求(set xxx )。读取到的数据会放进c->rbuf的buf中。如果buf没有空间存储更多数据的时候,就会触发内存块的重新分配。重新分配,memcached限制了4次,估计是担忧客户端的恶意攻击导致存储命令行数据报文的buf不断的realloc。
1 //这个方法是通过TCP的方式读取客户端传递过来的命令数据 2 static enum try_read_result try_read_network(conn *c) { 3 //这个方法会最终返回try_read_result的枚举类型 4 //默认设置READ_NO_DATA_RECEIVED:没有接受到数据 5 enum try_read_result gotdata = READ_NO_DATA_RECEIVED; 6 int res; 7 int num_allocs = 0; 8 assert(c != NULL); 9 10 //c->rcurr 存放未解析命令内容指针 c->rbytes 还有多少没解析过的数据 11 //c->rbuf 用于读取命令的buf,存储命令字符串的指针 c->rsize rbuf的size 12 //这边每次都会将前一次剩余的命令报文,移动到c->rbuf的头部。 13 if (c->rcurr != c->rbuf) { 14 if (c->rbytes != 0) /* otherwise there's nothing to copy */ 15 memmove(c->rbuf, c->rcurr, c->rbytes); 16 c->rcurr = c->rbuf; 17 } 18 //循环从fd中读取数据 19 while (1) { 20 //如果buf满了,则需要重新分配一块更大的内存 21 //当未解析的数据size 大于等于 buf块的size,则需要重新分配 22 if (c->rbytes >= c->rsize) { 23 //最多分配4次 24 if (num_allocs == 4) { 25 return gotdata; 26 } 27 ++num_allocs; 28 //从新分配一块新的内存块,内存大小为rsize的两倍 29 char *new_rbuf = realloc(c->rbuf, c->rsize * 2); 30 if (!new_rbuf) { 31 STATS_LOCK(); 32 stats.malloc_fails++; 33 STATS_UNLOCK(); 34 if (settings.verbose > 0) { 35 fprintf(stderr, "Couldn't realloc input buffer "); 36 } 37 c->rbytes = 0; /* ignore what we read */ 38 out_of_memory(c, "SERVER_ERROR out of memory reading request"); 39 c->write_and_go = conn_closing; 40 return READ_MEMORY_ERROR; 41 } 42 //c->rcurr和c->rbuf指向到新的buf块 43 c->rcurr = c->rbuf = new_rbuf; 44 c->rsize *= 2; //rsize则乘以2 45 } 46 47 //avail可以计算出buf块中剩余的空间多大 48 int avail = c->rsize - c->rbytes; 49 50 //这边我们可以看到Socket的读取方法 51 //c->sfd为Socket的ID 52 //c->rbuf + c->rbytes 意思是从buf块中空余的内存地址开始存放新读取到的数据 53 //avail 每次接收最大能读取多大的数据 54 res = read(c->sfd, c->rbuf + c->rbytes, avail); 55 56 //如果接受到的结果res大于0,则说明Socket中读取到了数据 57 //设置成READ_DATA_RECEIVED枚举类型,表明读取到了数据 58 if (res > 0) { 59 pthread_mutex_lock(&c->thread->stats.mutex); //线程锁 60 c->thread->stats.bytes_read += res; 61 pthread_mutex_unlock(&c->thread->stats.mutex); 62 gotdata = READ_DATA_RECEIVED; 63 c->rbytes += res; //未处理的数据量 + 当前读取到的命令size 64 if (res == avail) { 65 continue; 66 } else { 67 break; 68 } 69 } 70 //判断读取失败的两种情况 71 if (res == 0) { 72 return READ_ERROR; 73 } 74 if (res == -1) { 75 if (errno == EAGAIN || errno == EWOULDBLOCK) { 76 break; 77 } 78 return READ_ERROR; 79 } 80 } 81 return gotdata; 82 }
try_read_network函数就是从socket中把数据读到c->rbuf中去而已,同时初始化一些变量例如rbytes等,读取数据成功则返回READ_DATA_RECEIVED,状态机 conn_set_state(c, conn_parse_cmd);进入conn_parse_cmd状态:
1 case conn_parse_cmd : 2 /** 3 try_read_network后,到达conn_parse_cmd状态,但try_read_network并不确保每次到达 4 的数据都足够一个完整的cmd(ascii协议情况下往往是没有" ",即回车换行), 5 所以下面的try_read_command之所以叫try就是这个原因, 6 当读到的数据还不够成为一个cmd的时候,返回0,conn继续进入conn_waiting状态等待更多的数据到达。 7 */ 8 if (try_read_command(c) == 0) { 9 /* wee need more data! */ 10 conn_set_state(c, conn_waiting); 11 } 12 break;
进行conn_parse_cmd主要是调用try_read_command函数读取命令,上面注释也说明了数据不够一个cmd的情况,下面我们进入try_read_command,看看try_read_command不返回0时,也就是足够一个cmd后是怎么解析这个cmd的。
//如果我们已经在c->rbuf中有可以处理的命令行了,则就可以调用此函数来处理命令解析 static int try_read_command(conn *c) { //......省略部分代码 //有两种模式,是否是二进制模式还是ascii模式 if (c->protocol == binary_prot) { //更多代码 } else { //这边主要处理非二进制模式的命令解析 char *el, *cont; //如果c->rbytes==0 表示buf容器中没有可以处理的命令报文,则返回0 //0 是让程序继续等待接收新的客户端报文 if (c->rbytes == 0) return 0; //查找命令中是否有 ,memcache的命令通过 来分割 //当客户端的数据报文过来的时候,Memcached通过查找接收到的数据中是否有 换行符来判断收到的命令数据包是否完整 //例如命令:set username 10234344 get username //这个命令就可以分割成两个命令,分别是set和get的命令 //el返回 的字符指针地址 el = memchr(c->rcurr, ' ', c->rbytes); //如果没有找到 ,说明命令不完整,则返回0,继续等待接收新的客户端数据报文 if (!el) { //c->rbytes是接收到的数据包的长度 //这边非常有趣,如果一次接收的数据报文大于了1K,则Memcached回去判断这个请求是否太大了,是否有问题? //然后会关闭这个客户端的链接 if (c->rbytes > 1024) { /* * We didn't have a ' ' in the first k. This _has_ to be a * large multiget, if not we should just nuke the connection. */ char *ptr = c->rcurr; while (*ptr == ' ') { /* ignore leading whitespaces */ ++ptr; } if (ptr - c->rcurr > 100 || (strncmp(ptr, "get ", 4) && strncmp(ptr, "gets ", 5))) { conn_set_state(c, conn_closing); return 1; } } return 0; } //如果找到了 ,说明c->rcurr中有完整的命令了 cont = el + 1; //下一个命令开始的指针节点 //这边判断是否是 ,如果是 ,则el往前移一位 if ((el - c->rcurr) > 1 && *(el - 1) == ' ') { el--; } //然后将命令的最后一个字符用 �(字符串结束符号)来分隔 *el = '�'; assert(cont <= (c->rcurr + c->rbytes)); c->last_cmd_time = current_time; //最后命令时间 //处理命令,c->rcurr就是命令 process_command(c, c->rcurr); c->rbytes -= (cont - c->rcurr); //这个地方为何不这样写?c->rbytes = c->rcurr - cont c->rcurr = cont; //将c->rcurr指向到下一个命令的指针节点 assert(c->rcurr <= (c->rbuf + c->rsize)); } return 1; }
上面try_read_command把命令读出(其实只是简单地找出一个完整的命令,在后面加个�而已)。
在这里插一下memcached的SET命令的协议,或者你可以看memcached/doc/protocol.txt中的说明:
完成一个SET命令,其实需要两行,也就是需要按两次回车换行“ ”,第一行叫“命令行”,格式是SET key flags exptime bytes ,如SET name 0 0 5 , 键为name,flags标志位可暂时不管,超时设为0,value的字节长度是4。然后才有第二行叫“数据行”,格式为:value ,例如:calix 。这两行分别敲下去,SET命令才算完成。
所以处理SET命令时上面的try_read_command首先处理的是SET name 0 0 5 这个“命令行”。
看看进入process_command函数如何执行:
1 /** 2 这里就是对命令的解析和执行了 3 (其实准确来说,这里只是执行了命令的一半(例如如果是SET命令,则是“命令行”部分), 4 然后根据命令类型再次改变conn_state使程序再次进入状态机,完成命令的 5 另一半工作,后面详说) 6 command此时的指针值等于conn的rcurr 7 */ 8 static void process_command(conn *c, char *command) { 9 token_t tokens[MAX_TOKENS]; 10 size_t ntokens; 11 int comm; //命令类型 12 c->msgcurr = 0; 13 c->msgused = 0; 14 c->iovused = 0; 15 if (add_msghdr(c) != 0) { 16 out_of_memory(c, "SERVER_ERROR out of memory preparing response"); 17 return; 18 } 19 /** 20 下面这个tokenize_command是一个词法分析,把command分解成一个个token 21 */ 22 ntokens = tokenize_command(command, tokens, MAX_TOKENS); 23 //下面是对上面分解出来的token再进行语法分析,解析命令,下面的comm变量为最终解析出来命令类型 24 if (ntokens >= 3 && 25 ((strcmp(tokens[COMMAND_TOKEN].value, "get") == 0) || 26 (strcmp(tokens[COMMAND_TOKEN].value, "bget") == 0))) { 27 process_get_command(c, tokens, ntokens, false); 28 } else if ((ntokens == 6 || ntokens == 7) && 29 ((strcmp(tokens[COMMAND_TOKEN].value, "add") == 0 && (comm = NREAD_ADD)) || 30 (strcmp(tokens[COMMAND_TOKEN].value, "set") == 0 && (comm = NREAD_SET)) || 31 (strcmp(tokens[COMMAND_TOKEN].value, "replace") == 0 && (comm = NREAD_REPLACE)) || 32 (strcmp(tokens[COMMAND_TOKEN].value, "prepend") == 0 && (comm = NREAD_PREPEND)) || 33 (strcmp(tokens[COMMAND_TOKEN].value, "append") == 0 && (comm = NREAD_APPEND)) )) { 34 //add/set/replace/prepend/append为“更新”命令,调用同一个函数执行命令。详见process_update_command定义处 35 process_update_command(c, tokens, ntokens, comm, false); 36 } 37 //...... 38 }
process_command 方法中调用了tokenize_command方法来分解命令。例如:set username zhuli 则会分解成三个元素:set和username和zhuli这三个元素。
//拆分命令方法 static size_t tokenize_command(char *command, token_t *tokens, const size_t max_tokens) { char *s, *e; size_t ntokens = 0; //命令参数游标 size_t len = strlen(command); //命令长度 unsigned int i = 0; assert(command != NULL && tokens != NULL && max_tokens > 1); s = e = command; for (i = 0; i < len; i++) { //指针不停往前走,如果遇到空格,则会停下来,将命令元素拆分出来,放进tokens这个数组中 if (*e == ' ') { if (s != e) { tokens[ntokens].value = s; tokens[ntokens].length = e - s; ntokens++; //这边将空格替换成� //Memcached这边的代码写的非常的好,这边的命令进行切割的时候,并没有将内存块进行拷贝,而是在原来的内存块上进行切割 *e = '�'; //最多8个元素 if (ntokens == max_tokens - 1) { e++; s = e; /* so we don't add an extra token */ break; } } s = e + 1; } e++; } if (s != e) { tokens[ntokens].value = s; tokens[ntokens].length = e - s; ntokens++; } /* * If we scanned the whole string, the terminal value pointer is null, * otherwise it is the first unprocessed character. */ tokens[ntokens].value = *e == '�' ? NULL : e; tokens[ntokens].length = 0; ntokens++; //返回值为参数个数,例如分解出3个元素,则返回3 return ntokens; }
上面的代码可以看出首先我们要对命令进行“解析”,词法语法分析等等,最终我们的set name 0 0 5 命令会进入process_update_command函数中执行:
static void process_update_command(conn *c, token_t *tokens, const size_t ntokens, int comm, bool handle_cas) { if (tokens[KEY_TOKEN].length > KEY_MAX_LENGTH) { out_string(c, "CLIENT_ERROR bad command line format"); //key过长,out_string函数的作用是输出响应, //详见out_string定义处 return; } key = tokens[KEY_TOKEN].value; //键名 nkey = tokens[KEY_TOKEN].length; //键长度 //下面这个if同时把命令相应的参数(如缓存超时时间等)赋值给相应变量:exptime_int等 if (! (safe_strtoul(tokens[2].value, (uint32_t *)&flags) && safe_strtol(tokens[3].value, &exptime_int) && safe_strtol(tokens[4].value, (int32_t *)&vlen))) { out_string(c, "CLIENT_ERROR bad command line format"); return; } exptime = exptime_int; if (exptime < 0) exptime = REALTIME_MAXDELTA + 1; //在这里执行内存分配工作。详见内存管理篇 it = item_alloc(key, nkey, flags, realtime(exptime), vlen); ITEM_set_cas(it, req_cas_id); c->item = it; //将item指针指向分配的item空间 c->ritem = ITEM_data(it); //将 ritem 指向 it->data中要存放 value 的空间地址 c->rlbytes = it->nbytes; //data的大小 c->cmd = comm; //命令类型 conn_set_state(c, conn_nread); //继续调用状态机,执行命令的另一半工作。 }
process_update_command函数最终执行了item_alloc为我们要set的数据(称为item)分配了内存。同时,为c对象赋了相应的一些值。
但是其实这里仅仅是为item分配了空间,还没有把value塞进去,因为我们仅仅执行了SET命令的“命令行“部分,根据“命令行”部分的信息分配空间。代码最后一行看到在这里,我们又把c的状态变成了conn_nread,等“数据行”达到,epoll事件触发状态机下一次循环进入conn_nread分支,其实就是完成SET命令的第二部分,读出“数据行”:
case conn_nread: /** 由process_update_command执行后进入此状态,process_update_command函数只执行了add/set/replace 等命令的一半, 剩下的一半由这里完成。 例如如果是上面的set命令,process_update_command只完成了“命令行”部分,分配了item空间, 但还没有把value塞到对应的 item中去。因此,在这一半要完成的动作就是把value的数据从socket中读出来, 塞到刚拿到的item空间中去 */ /* 下面的rlbytes字段表示要读的“value数据”还剩下多少字节 (注意与"rbytes"的区别) 如果是第一次由process_update_command进入到此,rlbytes此时在process_update_command中被初始化为item->nbytes, 即value的总字节数,SET name 0 0 5 中的5。 */ if (c->rlbytes == 0) { /** 注意rlbytes为0才读完,否则状态机一直会进来这个conn_nread分支继续读value数据, 读完就调用complete_nread完成收尾工作,程序会跟着complete_nread进入下一个 状态。所以执行完complete_nread会break; */ complete_nread(c); break; } //如果还有数据没读完,继续往下执行。可知,下面的动作就是继续从buffer中读value数据往item中的data的value位置塞。 if (c->rbytes > 0) { /** 进入到这个if,是因为有可能先前读到的buffer已经有“数据行”部分,因为一次事件通知, 不保证socket可读数据只有一个 。 */ /** 取rbytes与rlbytes中最小的值。 为啥? 因为这里我们的目的是剩下的还没读的value的字节,而rlbytes代表的是还剩下的字节数 如果rlbytes比rbytes小,只读rlbytes长度就够了,rbytes中多出来的部分不是我们这个时候想要的 如果rbytes比rlbytes小,即使你要rlbytes这么多,但buffer中没有这么多给你读。 */ int tocopy = c->rbytes > c->rlbytes ? c->rlbytes : c->rbytes; if (c->ritem != c->rcurr) { memmove(c->ritem, c->rcurr, tocopy); //往分配的item中塞,即为key设置value的过程 } c->ritem += tocopy; c->rlbytes -= tocopy; c->rcurr += tocopy; c->rbytes -= tocopy; if (c->rlbytes == 0) { break; } } //这里往往是我们先前读到buffer的数据还没足够的情况下,从socket中读。 res = read(c->sfd, c->ritem, c->rlbytes);//往分配的item中塞,即为key设置value的过程 if (res > 0) { if (c->rcurr == c->ritem) { c->rcurr += res; } c->ritem += res; c->rlbytes -= res; break; }
上面主要通过这一行 res = read(c->sfd, c->ritem, c->rlbytes); 把value塞到刚分配出来的item空间,完成“数据行”部分的工作,逻辑上就是对key“赋值”。赋值结束后,调用complete_nread做一些收尾的工作。
static void complete_nread(conn *c) { //...... complete_nread_ascii(c); //...... } static void complete_nread_ascii(conn *c) { ret = store_item(it, comm, c); switch (ret) { case STORED: out_string(c, "STORED"); break; //...... } //...... } static void out_string(conn *c, const char *str) { size_t len; c->msgcurr = 0; c->msgused = 0; c->iovused = 0; add_msghdr(c); len = strlen(str); memcpy(c->wbuf, str, len); memcpy(c->wbuf + len, " ", 2); c->wbytes = len + 2; c->wcurr = c->wbuf; conn_set_state(c, conn_write); c->write_and_go = conn_new_cmd; return; }
进入状态机conn_write状态进行输出:
case conn_write: //...... /* fall through... */ case conn_mwrite: transmit(c); //...... static enum transmit_result transmit(conn *c) { //...... res = sendmsg(c->sfd, m, 0); //...... }
最后通过调用sendmsg把我们的”STORED”字符串响应给客户端。
附上处理 SET 命令状态机的状态转换图