1. 需求由来
1.Redis高并发的问题
Redis缓存的高性能有目共睹,应用的场景也是非常广泛,但是在高并发的场景下,也会出现问题:缓存击穿、缓存雪崩、缓存和数据一致性,以及今天要谈到的缓存并发竞争。
这里的并发指的是多个redis的client同时set key引起的并发问题。
2.出现并发设置Key的原因
Redis是一种单线程机制的nosql数据库,基于key-value,数据可持久化落盘。由于单线程所以Redis本身并没有锁的概念,多个客户端连接并不存在竞争关系,但是利用jedis等客户端对Redis进行并发访问时会出现问题。
比如:同时有多个子系统去set一个key。这个时候要注意什么呢?
3.举一个例子
多客户端同时并发写一个key,一个key的值是1,本来按顺序修改为2,3,4,最后是4,但是顺序变成了4,3,2,最后变成了2。
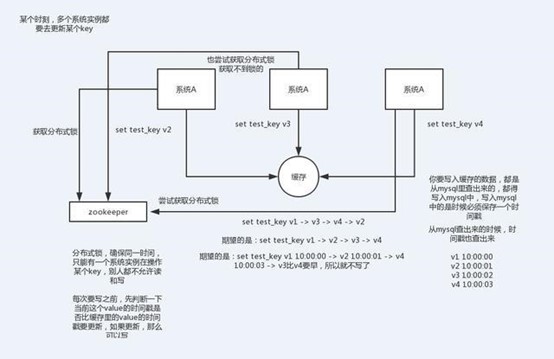
2. 解决方案
- 第一种方案:分布式锁+时间戳
1.整体技术方案
这种情况,主要是准备一个分布式锁,大家去抢锁,抢到锁就做set操作。
加锁的目的实际上就是把并行读写改成串行读写的方式,从而来避免资源竞争。
2.Redis分布式锁的实现
主要用到的redis函数是setnx()
用SETNX实现分布式锁。利用SETNX非常简单地实现分布式锁。例如:某客户端要获得一个名字youzhi的锁,客户端使用下面的命令进行获取:
SETNX lock.youzhi<current Unix time + lock timeout + 1>
如返回1,则该客户端获得锁,把lock.youzhi的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
如返回0,表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
3.时间戳
由于上面举的例子,要求key的操作需要顺序执行,所以需要保存一个时间戳判断set顺序。
系统A key 1 {ValueA 7:00} 系统B key 1 { ValueB 7:05}
假设系统B先抢到锁,将key1设置为{ValueB 7:05}。接下来系统A抢到锁,发现自己的key1的时间戳早于缓存中的时间戳(7:00<7:05),那就不做set操作了。
4.分布式锁
因为传统的加锁的做法(如java的synchronized和Lock)这里没用,只适合单点。因为这是分布式环境,需要的是分布式锁。
当然,分布式锁可以基于很多种方式实现,比如zookeeper、redis等,不管哪种方式实现,基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
- 第二种方案:利用消息队列
在并发量过大的情况下,可以通过消息中间件进行处理,把并行读写进行串行化。
把Redis.set操作放在队列中使其串行化,必须的一个一个执行。
这种方式在一些高并发的场景中算是一种通用的解决方案。
转载知乎https://zhuanlan.zhihu.com/p/52756935