第三章 数据库系统
随着应用系统的规模越来越大,现在的系统开发大部分都是基于数据库的应用。
因此,作为一名系统架构设计师,要熟练掌握数据库系统的设计方法和技术。
3.1数据库管理系统的类型:
分类标准:按数据模型分类、按用户数分类、按数据分布站点分类。
商业DBMS中所用的主要数据模型是:关系数据模型,有些实现了对象数据模型,但未得到广泛使用。
常见的DBMS按数据模型划分:关系型、稳定型、键值型、对象型等。
3.2数据库模式与范式
是数据库系统中的两个重要概念,是进行数据库设计的基础。
3.2.1 数据库的结构与模式
数据库技术中采用分级的方法将数据库的结构划分为多个层次。最著名的是美国ANSI/SPARC 数据库系统研究组1975 年提出的三级划分法。

1.三级抽象
数据库系统划分为三个抽象级:用户级、概念级、物理级。
(1)用户级数据库。 对应于外模式,是最接近用户的一级数据库,是用户可以看到和使用的数据库,又称用户视图。
用户级数据库主要由外部记录组成,不同的用户视图可以互相重叠,用户的所有操作都是针对用户视图进行的。
(2)概念级数据库。概念级数据库对应于概念模式,介于用户级和物理级之间,是所有用户视图的最小并集,是数据库管理员可看到和使用的数据库,又称DBA(DataBase Administrator,数据库管理员)视图。
概念级数据库由概念记录组成。
一个数据库可有多个不同的用户视图,每个用户视图由数据库某一部分的抽象表示。
概念级模式把用户视图有机地结合成一个整体,综合平衡考虑所有用户要求,实现数据的一致性、最大限度降低数据冗余、准确地反映数据间的联系。
(3)物理级数据库。对应于内模式,是数据库的低层表示,
它描述数据的实际存储组织,是最接近于物理存储的级,又称内部视图。
物理级数据库由内部记录组成,物理级数据库并不是真正的物理存储,而是最接近于物理存储的级。
2.三级模式
数据库系统的三级模式为外模式、概念模式、内模式。
(1)概念模式,描述整个数据库中数据库的逻辑结构,描述现实世界中的实体及其性质与联系,定义记录、数据项、数据的完整性约束条件及记录之间的联系,是数据项值的框架。
数据库系统概念模式通常还包含:
- 访问控制
- 保密定义
- 完整性检查
- 概念/物理之间的映射
概念模式是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
一个数据库只能有一个概念模式。
(2)外模式,用以描述用户看到或使用的那部分数据的逻辑结构,用户根据外模式用数据操作语句或应用程序去操作数据库中的数据。
外模式主要描述:
- 组成用户视图的各个记录的组成、相互关系、数据项的特征、数据的安全性和完整性约束条件。
外模式是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。一个数据库可有多个外模式。一个应用程序只能使用一个外模式。
(3)内模式,是整个数据库的最低层表示,不同于物理层,它假设外存是一个无限的线性地址空间。
内模式的定义的是
- 存储记录的类型
- 存储域的表示
- 存储记录的物理顺序
指引元、索引和存储路径等数据的存储组织。
内模式是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。一个数据库只有一个内模式。
内模式、模式、外模式之间的关系:
(1)模式是数据库的中心与关键;
(2)内模式依赖于模式,独立于外模式和存储设备;
(3)外模式面向具体的应用,独立于内模式和存储设备;
(4)应用程序依赖于外模式,独立于模式和内模式。
3.两级独立性
数据库系统两级独立性是指物理独立性和逻辑独立性。三个抽象级间通过两级映射(外模式-模式映射,模式-内模式映射)进行相互转换,使得数据库的三级形成一个统一的整体。
(1)物理独立性。指用户的应用程序与存储在磁盘上的数据库中的数据时相互独立的。
当数据的物理存储改变时,应用程序不需要改变。
物理独立性存在于概念模式和内模式之间的映射转换,说明物理组织发生变化时应用程序的独立程度。
(2)逻辑独立性,指用户的应用程序与数据库中的逻辑结构是相互独立的。
当数据的逻辑结构改变时,应用程序不需要改变。
逻辑独立性存在于外模式和概念模式之间的映射转换,说明概念模式发生变化时应用程序的独立程度。
希赛专家提示:逻辑独立性比物理独立性更难实现。
3.2.2数据模型
数据模型:
- 概念数据模型(实体-联系模型)
- 基本数据模型(结构数据模型)
概念数据模型是按照用户的观点来对数据和信息建模,主要用于数据库设计。
主要用实体--联系方法(Entity-Relationship Approach)表示,所以也称为E-R模型。
基本数据模型是按照计算机的观点对数据和信息建模,主要用于DBMS的实现。
是数据库系统的核心和基础。
三部分组成:
- 数据结构 (是对系统静态特性的描述)
- 数据操作 (是对系统动态特性的描述)
- 完整性约束 (是一组完整性规则的集合)
常用的基本数据模型有层次模型、网状模型、关系模型和面向对象模型。
(1)层次模型:用树形结构表示实体类型及实体间的联系。
优点:记录之间的联系通过指针来实现, 查询效率加哦噶偶。
缺点:只能表示1:n联系,要实现m:n联系的话,比较复杂,不易掌握。
由于层次顺序的严格和复杂,导致数据的查询和更新操作很复杂,应用程序的编写也比较复杂。
(2)网状模型:用有向图表示实体类型及实体间的联系。
优点:记录之间的联系通过指针实现,m:n联系也容易实现,查询效率高。
缺点:编写应用程序的过程比较复杂,程序员必须熟悉数据库的逻辑结构。
(3)关系模型:用表格结构表达实体集,用外键表示实体间的联系。
优点:
- 建立在严格的数学概念基础上;
- 概念(关系)单一,结构简单、清晰,用户易懂易用;
- 存储路径对用户透明,从而数据独立性、安全性好,简化数据库开发工作。
3.2.3关系代数
关系代数的基本运算主要有并、交、差、笛卡尔积、选择、投影、连接和除法运算。
(1)并。计算两个关系在集合理论上的并集,RUS的元组包括R和S所有元组的集合。
R∪S=S∪R。
(2)交。计算两个关系集合理论上的交集,R∩S的元组包括R和S相同元组的集合。
显然,R∩S=R-(R-S) 和R∩S=S-(S-R)成立。
(3)差。计算两个关系的区别集合,R-S的元组包括R中有而S中没有的元组的集合。
(4)笛卡尔积。计算两个关系的笛卡尔乘积。
令R为有m元的关系,S为有n元的关系,则R×S是m+n元的元组的集合。定义形式:
R'S
若R有u个元组,S有v个元组,则R×S 有u×v个元组。

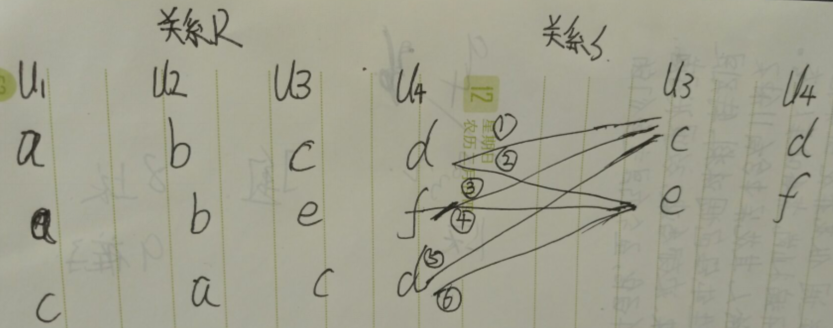
(5)投影,从一个关系中抽取指明的属性(列)。令R为一个包含属性A的关系,
pA(R)
例:对关系R做投影操作,p1,2(R)。
p1,2(R)操作是对第1列与第2列做投影。
(6)选择。 从关系R中抽取出满足给定 限制条件的记录,记作:
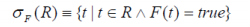
例:

F:表示选择条件,是一个逻辑表达式(逻辑运算符+算术表达式)。选择运算是从元组(行)的角度进行的运算。
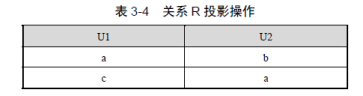
(7)θ 连接。θ 连接从两个关系的笛卡儿积中选取属性之间满足一定条件的元组,记作:
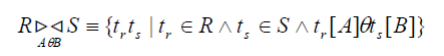


例:对关系R与关系S做自然连接操作。因为关系S的属性在关系R中都包含,所以得到的结果就是关系R的表。
(8)除。设有关系R(X,Y)与关系S(Z),Y和Z具有相同的属性个数,且对应属性出自相同域。
关系R(X,Y)÷S(Z)所得商关系,记为:R÷S。是:
- 关系R在属性X上投影的一个子集,
- 该子集和S(Z)的笛卡尔积必须包含在R(X,Y)中
具体计算公式:
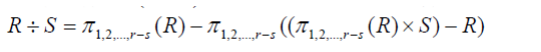
例:对关系R与关系S做除法运算。
求解过程:
首先,按除运算定义要求,确定X,Y,Z属性集合。Y是关系R中的属性集合,
Z是S中全部属性的集合,即Z={U3,U4},
由于Y=Z,因此Y={U3,U4},X={U1,U2}.
R÷S结果集包含属性U1和U2;然后,将关系R的U1、U2与关系S作笛卡尔积操作。
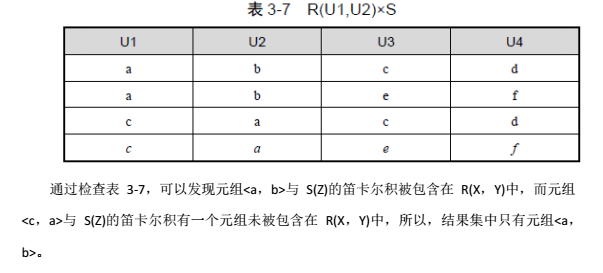

3.2.4数据的规范化
关系模型满足的确定约束条件称为范式,
根据满足约束条件的级别不同,范式由低到高分为:1NF(第一范式)、2NF(第二范式)、3NF(第三范式)、BCNF(BC范式)、4NF(第四范式)等。
不同的级别范式性质不同。
把一个低一级的关系模型分解为高一级关系模型的过程,称为关系模型的规范化。
关系模型分解必须遵守两个准则:
- 无损连接性:信息不失真(不增减信息)。
- 函数依赖保持性:不破坏属性间存在的依赖关系。
规范化的基本思想是:逐步消除不合适的函数依赖,使数据库中的各个关系模型达到某种程度的分离。
规范化解决的主要是:单个实体的质量问题,是对于问题域中原始数据展现的正规化处理。
规范化理论给出了判断关系模型优劣的理论标准,帮助预测模式可能出现的问题,是数据库逻辑设计的指南和工具,具体有:
- 用数据依赖的概念分析和表示各数据项之间的关系。
- 消除E-R图中的冗余联系。
1.函数依赖
(类似:自变量x确定后,相应函数值f(x)也就唯一确定了)
是衡量和调整数据规范化的最基础的理论依据。
例: 记录职工信息的结构如下:
职工工号(EMP_NO)
职工姓名(EMP_NAME)
所在部门(DEPT)
EMP_NO函数决定EMP_NAME 和 DEPT,
或者说 EMP_NAME,DEPT函数依赖于EMP_NO,
记为:EMP_NO→EMP_NAME,EMP_NO→DEPT。
给定一个K则唯一决定U中的一个元组,也就是U函数完全依赖于属性K,就称K为R的码。
一个关系可能有多个码,选中其中一个作为主码。
包含在任一码中的属性称为主属性,不包含在任何码中的属性称为非主属性。
关系R中的属性或属性组X不是R的码,但X是另一个关系模型的码,称X是R的外码。
主码和外码是一种表示关系间关联的重要手段。
数据库设计中一个重要的任务就是要找到问题域中正确的关联关系,孤立的关系模型很难描述清楚业务逻辑。
2.第一范式
1NF是最低的规范化要求。如果关系R中所有属性的值域都是简单域,其元素(即属性)不可再分,是属性项而不是属性组,那么关系模型R是第一范式的。记作 。
。
这一限制是关系的基本性质,所以任何关系都必须满足第一范式。第一范式是实际数据库设计中必须先达到的,通常称为数据元素的结构化。


满足第一范式,可以以省、市为条件进行查询和统计。
满足1NF的关系模型会有许多重复值,并且增加了修改其数据时引起纰漏的可能性。
为了消除这种数据冗余和避免更新数据的遗漏,需要更加规范的2NF。
3.第二范式
如果一个关系R属于1NF,且所有的非主属性都完全依赖于主属性,则称之为第二范式,记作 。
。
例:有一个获得专业技术证书的人员情况登记表结构为:
省份、姓名、证书名称、证书编号、核准项目、发证部门、发证时间、有效期。
这个结构符合1NF,其中“证书名称”和“证书编号”是主码,但是因为“发证部门”只完全依赖于“证书名称”,即只依赖于主关键字的一部分(即部分依赖),所以它不符合2NF,
这样首先存在数据冗余,因为证书种类可能不多。
其次,在更改发证部门时,如果漏改了某一记录,存在数据不一致。
再次,如果获得某种证书的职工全部跳槽了,那么这个发证部门的信息就可能丢失,即这种关系不允许存在某种证书没有获得者的情况。
可以用分解的方法消除部分依赖的情况,而使关系达到2NF的标准。
方法是,从现有关系中分解出新的关系表,使每个表中所有的非关键字都完全依赖于各自的主关键字。可以分解成两个表(省份、姓名、证书名称、证书编号、核准项目、发证日期、有效期)和(证书名称、发证部门),这样就完全符合2NF了。
4.第三范式
如果一个关系R属于2NF,且每个非主属性不传递依赖于主属性,这种关系是3NF,记作 。
。
从2NF中消除传递依赖,就是3NF。
例:有一个表(职工姓名,工资级别,工资额),其中职工姓名是关键字,此关系符合2NF,
因为工资级别决定工资额,也就是说非主属性“工资额”传递依赖于主属性“职工姓名”,它不符合3NF,同样可以使用投影分解的办法分解成两个表:(职工姓名,工资级别),(工资级别,工资额)。
5.BC范式
一般满足3NF的关系模型已能消除冗余和各种异常现象,获得比较满意的效果,但无论2NF还是3NF都没有涉及主属性间的函数依赖,所以有时仍会引起一些问题。因此引入了BC范式(由Boyeet和Codd提出)。通常认为BCNF是第三范式的改进。
BC范式的定义:如果关系模型 R∈ 1NF,且R中每一个函数依赖关系中的决定因素都包含码,则R是满足BC范式的关系,记作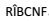 。
。
当一个关系模型,则在函数依赖范畴里,就认为已彻底实现了分离,消除了插入、删除的异常。
综合1NF、2NF和3NF、BCNF的内涵可概括如下:
(1)非主属性完全函数依赖于码(2NF的要求)
(2)非主属性不传递依赖于任何一个候选码(3NF的要求)
(3)主属性对不含它的码完全函数依赖(BCNF的要求)
(4)没有属性完全函数依赖于一组非主属性(BCNF的要求)。
3.2.5反规范化
数据库中的数据规范化的优点是:减少了数据冗余,节约了存储空间,相应逻辑和物理的I/O次数减少,同时加快了增、删、改的速度,但是对完全规范的数据库查询,通常需要更多的连接操作,从而影响查询速度。
有时为了提高某些查询或应用的性能而破坏规范规则,即反规范化(非规范化处理)。
常见的反规范化技术包括:
(1)增加冗余列
增加冗余列是指在多个表中具有相同的列,它常用来在查询时避免连接操作。
其他笔记整理在笔记本上,后续贴图