Spark安装
参照教程安装Spark 和 Scala 参考链接:http://dblab.xmu.edu.cn/blog/1307-2/
环境:Linux 已安装Hadoop
spark官方下载地址:http://spark.apache.org/downloads.html
参照图中内容下载spark,由于我们已经自己安装了Hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Apache Hadoop ”,然后,点击“Download Spark”后面的“spark-2.4.4-bin-without-hadoop.tgz”下载即可。

Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
对已下载内容进行解压并修改用户权限
sudo tar -zxf ~/下载/spark-2.1.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.1.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名

安装后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
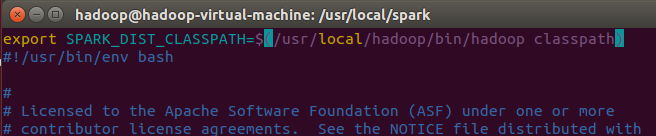
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
vim中键入i进行插入,esc推出编辑,:wq进行保存并退出
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
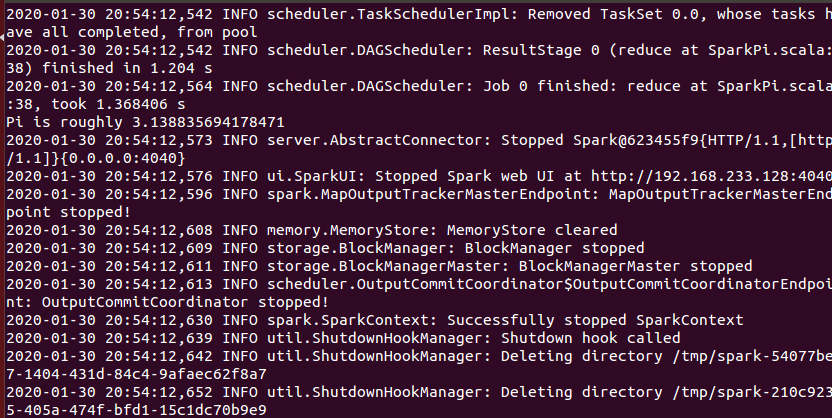
bin/run-example SparkPi 2>&1 | grep "Pi is"
![]()
获得π的近似值
Spark shell中运行代码
使用命令bin/spark-shell进入spark-shell环境
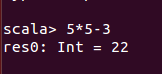
输入表达式进行计算
可以使用命令“:quit”或直接使用“Ctrl+D”组合键退出