6、对象流 ObjectInputStream和ObjectOutStream
6.1 Java序列化
Java提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。
将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化,也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象。
整个过程都是Java虚拟机(JVM)独立的,也就是说,在一个平台上序列化的对象可以在另一个完全不同的平台上反序列化该对象。
类ObjectInputStream和ObjectOutStream是高层次的数据流,他们包含反序列化和序列化对象的方法。
意义:序列化机制允许将实现序列化的Java对象转换为字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
应用场景:
-
所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method incoke,远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;
-
所有需要保存到磁盘的Java对象都必须是可序列化的,通常建议,程序创建的每个JavaBean类都实现Serializeable接口。
6.2 Serializable接口
一个类的对象要想序列化成功,必须满足两个条件:
-
该类必须实现java.io.Serializable接口
-
该类的所有属性必须是可序列话的。如果有一个属性不是可序列话的,则该属性必须注明是短暂的(trianstient)。
java.io.Serializable序列化接口没有方法或字段,仅用于标识可序列化的语义,未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。
要允许不可序列化类的子类型序列化,可以假定该子类型负责保存和恢复超类型的公用(public)、受保护(protected)和(如果可访问)包(package)字段的状态。尽在子类型拓展的类有一个可访问的无参数构造方法来初始化该类的状态时,才可以假定子类型有此职责。如果不是这种情况,则声明一个类为可序列化类是错误的,该错误将在运行时检测到。
在反序列化过程中,将使用该类的公用或受保护的午餐构造方法初始化不可序列化的字段。可序列化的子类必须能够访问无参数构造方法。可序列化子类的字段将从该流中恢复。
6.3 Externalizable接口
java.io.Externalizable的实例类的唯一特性是可以被写入序列化流中,该类负责保存和恢复实例的内容。其继承了接口Serializable,定义了两个方法writeExternal和readExternal。
public interface Externalizable extends java.io.Serializable { void writeExternal(ObjectOutput out) throws IOException; void readExternal(ObjectInput in) throws IOException, ClassNotFoundException; }
若某个要完全控制某一对象及其超类型的流格式和内容,则他要实现Externalizable接口的这两个方法,这些方法必须显式与超类型进行协调以保存其状态,这些方法将替代定制的writeObject 和 readObject 方法实现。
在序列化过程中,如果对象支持Externalizable,则调用writeExternal方法,若是不支持Externalizable但是实现了Serializable,则使用ObjectOutputStream 保存该对象。
6.4 ObjectOutputStream ObjectInputStream
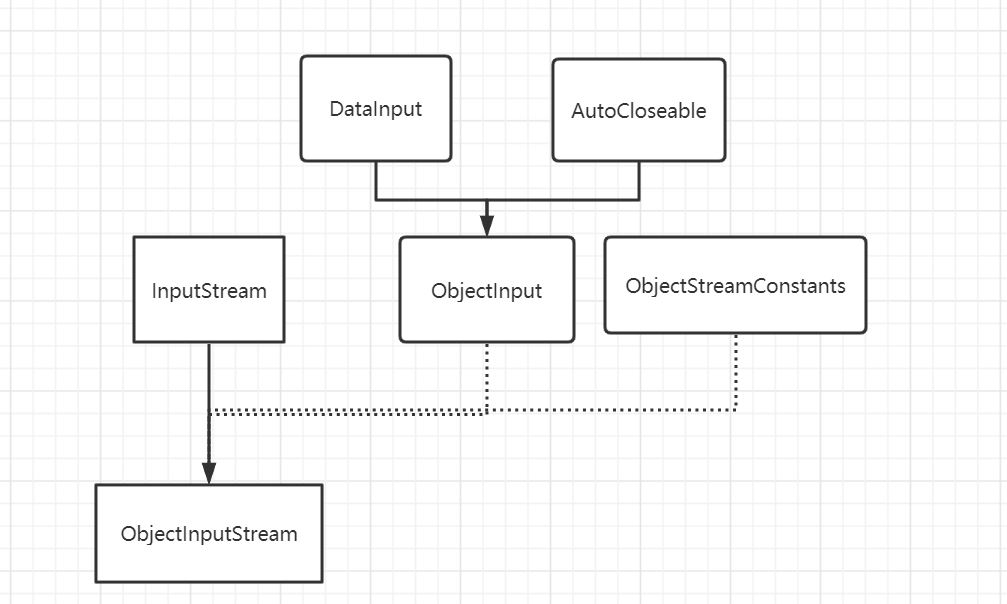
ObjectOutputStream 继承了虚拟类OutputStream,实现了接口ObjectOutput,而接口ObjectOutput继承了接口AutoCloseble和接口DataOutput。
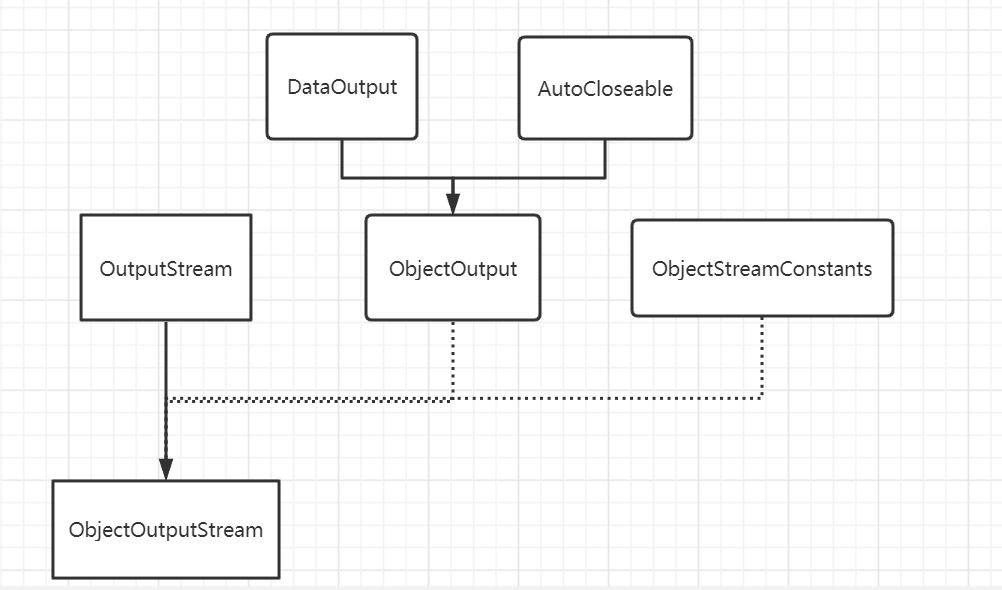
ObjectInputStream继承了虚拟类InputStream,实现了接口ObjectInput,而接口ObjectInput继承了接口AutoCloseble和接口DataInput。
接下来先从对象流所继承的接口着手进行分析。
6.4.1 AutoCloseble
java.lang.AutoCloseble仅仅定义了方法close()。
AutoCloseable可以保存资源的对象(如文件或套接字句柄),直到它关闭。AutoCloseable对象的close()方法在退出已在资源规范头中声明对象的try-with-resources块时自动调用。这种结构确保迅速释放,避免资源耗尽异常和可能发生的错误。
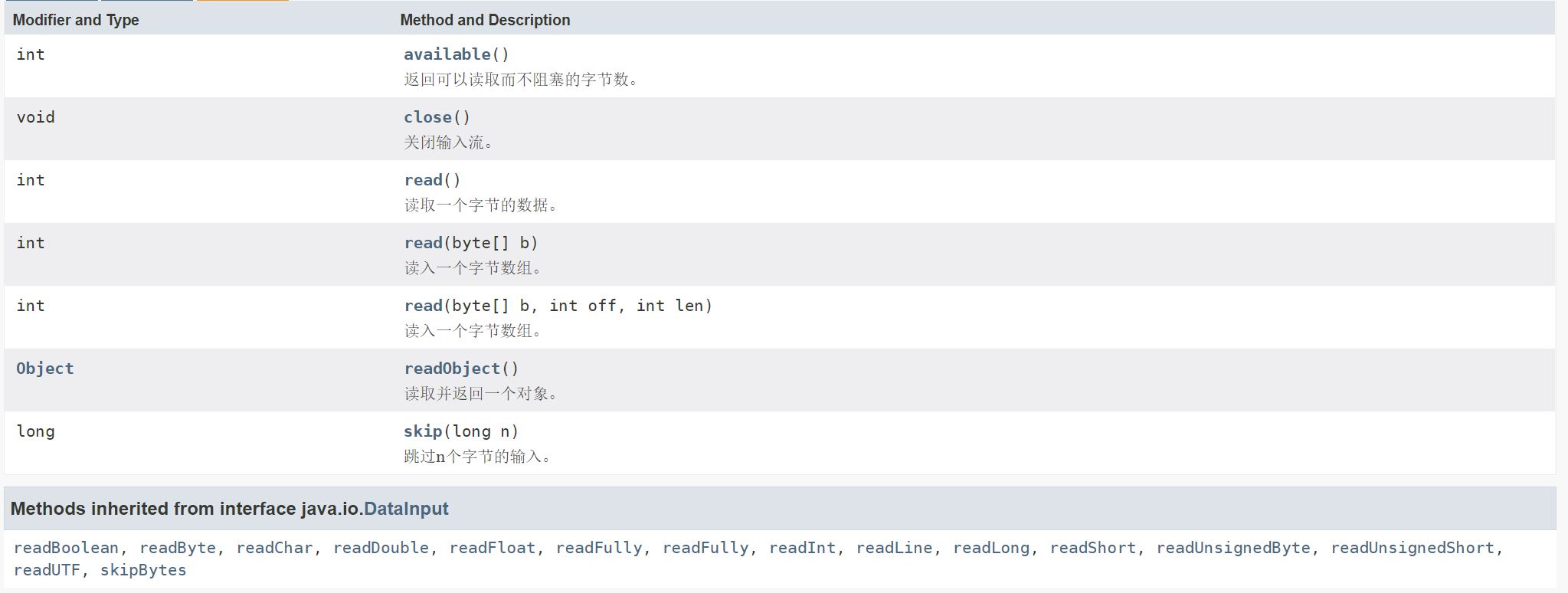
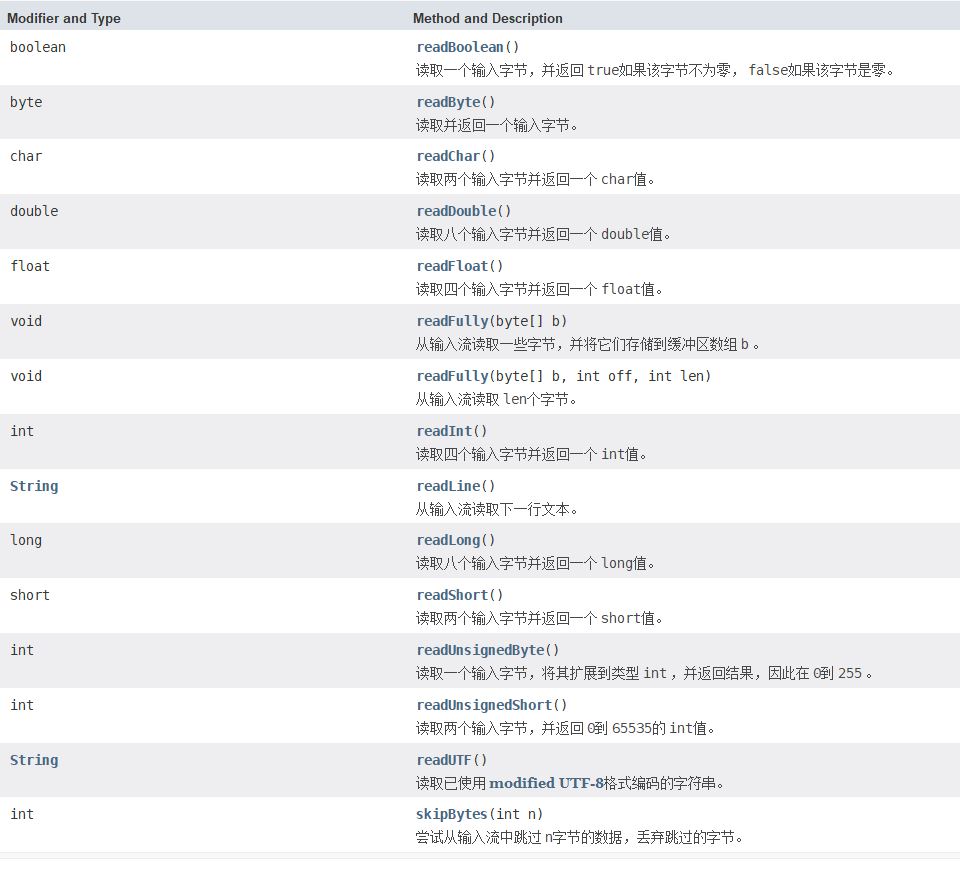
6.4.2 DataInput/DataOutput
java.io.DataOutput接口提供将数据从任何Java基本数据类型转换为一系列字节,并将这些字节写入二进制流。还有一种将String转换为modified UTF-8格式并编写结果字节系列的功能。
java.io.DataInput接口提供从二进制流读取字节,并根据所有的Java基本数据类型进行重构。还有,同时还提供根据modified UTF-8格式的数据重构String的工具。
Modified UTF-8:Datainput和DataOutput接口实现表示modified UTF-8格式的Unicode字符串,这种格式与标准UTF-8格式之间的不同如下:
-
null字节'u0000'是用2-byte格式而不是1-byte格式编码的,因此已编码的字符串中绝不会有嵌入的null。
-
仅使用1-byte、2-byte和3-byte格式。
-
DataOutput所做的是将Java基本数据类型转换为一系列字节,进行的是“写”的操作,其方法总结如下:

DataInput所做的是将DataOutput生成的字节重构成为Java基本数据类型,进行的是“读”的操作,其方法总结如下:

6.4.3 ObjectInput/ObjectOutput
java.io.ObjectOutput接口继承了接口DataOutput和AutoCloseable接口,java.io.ObjectInput接口继承了接口DataInput和AutoCloseable接口.
ObjectOutput和ObjectInput分别拓展了DataOutput和DataInput接口以包含对象的写入和读取。
DataOutput保妥用于输出原始类型的方法,Object将该接口拓展为包含对象、数组和字符串。

DataInput包括用于输入原始类型的方法,ObjectInput将该接口拓展为包含对象、数组和字符串。
6.4.4 ObjectStreamConstants
java.io.ObjectStreamConstants是指写入对象序列化流的常量,接口中仅仅包含了许多的静态常量。
public interface ObjectStreamConstants { /*写入流标题的魔数*/ final static short STREAM_MAGIC = (short)0xaced; /*写入流标题的版本号*/ final static short STREAM_VERSION = 5; /* 流中的每个项的前面都有一个标记 */ /*第一个标签值*/ final static byte TC_BASE = 0x70; /*空对象引用*/ final static byte TC_NULL = (byte)0x70; /* 引用已写入流的对象 */ final static byte TC_REFERENCE = (byte)0x71; /* 新的类描述符*/ final static byte TC_CLASSDESC = (byte)0x72; /* 新对象*/ final static byte TC_OBJECT = (byte)0x73; /*新的字符串*/ final static byte TC_STRING = (byte)0x74; /* 新数组*/ final static byte TC_ARRAY = (byte)0x75; /* 结束对象的可选数据块 */ final static byte TC_ENDBLOCKDATA = (byte)0x78; /* 重新设置流上下文 */ final static byte TC_RESET = (byte)0x79; /* 长块数据 */ final static byte TC_BLOCKDATALONG= (byte)0x7A; /* 写入时异常 */ final static byte TC_EXCEPTION = (byte)0x7B; /*长串*/ final static byte TC_LONGSTRING = (byte)0x7C; /* 新的代理类描述符 */ final static byte TC_PROXYCLASSDESC = (byte)0x7D; /* 新的枚举常数 */ final static byte TC_ENUM = (byte)0x7E; /* 最后一个标签值 */ final static byte TC_MAX = (byte)0x7E; /* 要分配的第一个wire句柄 */ final static int baseWireHandle = 0x7e0000; /******************************************************/ /* ObjectStreamClass标志的位掩码。*/ /*指示可序列化类定义其自己的writeObject方法的位掩码 */ final static byte SC_WRITE_METHOD = 0x01; /* 指示以块模式写入Externalizable数据的位掩码 * Added for PROTOCOL_VERSION_2. */ final static byte SC_BLOCK_DATA = 0x08; /*指示类是可序列化的位掩码*/ final static byte SC_SERIALIZABLE = 0x02; /*指示类是Externalizable的位掩码*/ final static byte SC_EXTERNALIZABLE = 0x04; /** 指示类是枚举类型的位掩码 * @since 1.5 */ final static byte SC_ENUM = 0x10; /* *******************************************************************/ /* 安全权限 */ /** 在序列化/反序列化期间启用一个对象替换另一个对象 * @see java.io.ObjectOutputStream#enableReplaceObject(boolean) * @see java.io.ObjectInputStream#enableResolveObject(boolean) * @since 1.2 */ final static SerializablePermission SUBSTITUTION_PERMISSION = new SerializablePermission("enableSubstitution"); /** *启用对readObject和writeObject的重写 * @see java.io.ObjectOutputStream#writeObjectOverride(Object) * @see java.io.ObjectInputStream#readObjectOverride() * @since 1.2 */ final static SerializablePermission SUBCLASS_IMPLEMENTATION_PERMISSION = new SerializablePermission("enableSubclassImplementation"); /** * 流协议版本 * * All externalizable data is written in JDK 1.1 external data * format after calling this method. This version is needed to write * streams containing Externalizable data that can be read by * pre-JDK 1.1.6 JVMs. * * @see java.io.ObjectOutputStream#useProtocolVersion(int) * @since 1.2 */ public final static int PROTOCOL_VERSION_1 = 1; /** * 流协议版本 * * This protocol is written by JVM 1.2. * * Externalizable data is written in block data mode and is * terminated with TC_ENDBLOCKDATA. Externalizable class descriptor * flags has SC_BLOCK_DATA enabled. JVM 1.1.6 and greater can * read this format change. * * Enables writing a nonSerializable class descriptor into the * stream. The serialVersionUID of a nonSerializable class is * set to 0L. * * @see java.io.ObjectOutputStream#useProtocolVersion(int) * @see #SC_BLOCK_DATA * @since 1.2 */ public final static int PROTOCOL_VERSION_2 = 2; }
6.4.5 ObjectOutputStreamObjectInputStream具体介绍
有关ObjectOutputStream和ObjectInputStream的描述还有许多细节,具体可以去看
ObjectOutputStream将Java对象的原始数据类型和图形写入OutputStream,之后可以使用ObjectInputStream读取(重构)对象,也可以通过使用文件流来实现对象的持久化存储(persistent storage for graphs of objects),如果流是网络套接字流,则可以在另一个主机或者另一个进程中重构对象。
在序列化过程中,ObjectOutputStream进行的是序列化,ObjectInputStream进行的是反序列化,需要确保从流中创建的所有对象的类型与Java虚拟机中存在的类匹配,根据需要使用标准机制加载类。
所以只有支持java.io.Serializable接口的对象才能写入流中。每个可序列化对象的类被编码,包括类的类名和签名,对象的字段和数组的值以及从初始化对象引用的任何其他对象的关闭。
ObjectOutputStream
ObjectOutputStream实现了ObjectOutput,其中方法writeObject用于将一个对象写入流中。任何对象,包括字符串和数组,都是writeObject编写的。多个对象或原语可以写入流。必须从队形的ObjectInputStream读取对象,其类型和写入次序相同。
对象的默认序列化机制写入对象的类,类签名以及所有非瞬态和非静态字段的值。引用其他对象(除了在瞬态或静态字段中)也会导致这些对象被写入。使用引用共享机制对单个对象的多个引用进行编码,以便可以将对象的图形恢复为与原始文件相同的形状。
try { FileOutputStream fos = new FileOutputStream("data/1.txt"); ObjectOutputStream oos = new ObjectOutputStream(fos); oos.writeInt(123); oos.writeObject("Today"); oos.writeObject(new Date()); oos.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }
ObjectInputStream
在ObjectInputStream中,readObject用于从流中读取对象,应使用Java的安全铸造(Java's safe casting)来获得所需的类型。在Java中,字符串和数组是对象,在序列化过程中被视为对象,读取时,需要将其转换为预期类型。
对象的默认反序列化机制将每个字段的内容恢复为写入时的值和类型。声明为瞬态(transtient)或静态(static)的字段被反序列化过程忽略。对其他对象的引用导致根据需要从流中读取这些对象,使用参考共享机制正确恢复对象的图形。反序列化时总是分配新对象,这样可以防止现有对象被覆盖。
读取对象类似于运行新对象的构造函数。为对象分配内存,并初始化为零(NULL)。对非可序列化类调用无参构造函数,然后从最接近java.lang.object的可序列化类开始到最特化 (most specific)的可序列化类结束,从串中还原可序列化类的字段。
try { FileInputStream fis = new FileInputStream("data/1.txt"); ObjectInputStream ois = new ObjectInputStream(fis); System.out.println(ois.readInt()); System.out.println((String) ois.readObject()); System.out.println((Date) ois.readObject()); ois.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); }
6.5 ObjectOutputStream部分源码分析
ObjectOutputStream的源码比较复杂,所以只打算从五点入手看一下,
-
变量信息
-
构造方法
-
writeObject方法
-
内部类简要介绍
6.5.1 变量信息
这些变量中内部类Caches用于安全审计缓存。bout是下层输出流,HandleTableReplaceTable和两个表是用于记录已输出对象的缓存便于重复输出的时候输出上一个相同内容的位置。接下来两个是writeObject()/writeExternal()上行调用记录上下文用的。debugInfoStack用于存储错误信息。
private static class Caches { /** 子类的安全审计结果缓存*/ static final ConcurrentMap<WeakClassKey,Boolean> subclassAudits = new ConcurrentHashMap<>(); /** 对审计子类弱引用的队列*/ static final ReferenceQueue<Class<?>> subclassAuditsQueue = new ReferenceQueue<>(); } /** 解决块数据转换的过滤流*/ private final BlockDataOutputStream bout; /** obj -> 线性句柄映射*/ private final HandleTable handles; /** obj -> 替代obj映射*/ private final ReplaceTable subs; /** 流协议版本*/ private int protocol = PROTOCOL_VERSION_2; /** 递归深度*/ private int depth; /** 写基本数据类型字段值缓冲区 */ private byte[] primVals; /** 子类重写writeObject()的方式,如果被设置为true,调用writeObjectOverride()来替代writeObject() */ private final boolean enableOverride; /** 如果被设置为true 调用 replaceObject() */ private boolean enableReplace; // 下面的值只在上行调用writeObject()/writeExternal()时有效 /** 上行调用类定义的writeObject方法时的上下文,持有当前被序列化的对象和当前对象描述符。在非writeObject上行调用时为null */ private SerialCallbackContext curContext; /** 当前PutField对象*/ private PutFieldImpl curPut; /** 用户存储debug追踪信息 */ private final DebugTraceInfoStack debugInfoStack; /**关于异常位置的扩展信息为true或false*/ private static final boolean extendedDebugInfo = java.security.AccessController.doPrivileged( new sun.security.action.GetBooleanAction( "sun.io.serialization.extendedDebugInfo")).booleanValue();
6.5.2 构造方法

构造方法有两个,public所修饰构造函数是自身构造需要提供一个输入流,protect所修饰的构造函数是提供给子类用的,创建一个自身相关内部变量全为空的对象输出流。但是,两个构造器都会进行安全检查,检查序列化的类是否重写了安全敏感方法,如果违反了规则会抛出异常。正常的构造类还会直接输出头部信息,包括对象输出流的魔数和协议版本信息,所以集市只新建一个对象输出流就会输出头部信息。
/*创建一个ObjectOutputStream写到指定的OutputStream,这个构造器写序列化流头部到下层流中。 *调用者可能希望立即刷新流来确保接受ObjectInputStream构造器不会在读取头部时阻塞。 *如果一个安全管理器被安装,这个构造器将会在被直接调用和被重写了ObjectOutputStream.putFields或者ObjectOutputStream.writeUnshared方法的子类的构造器简介调用时检查enableSubclassImplementation序列化许可。 */ public ObjectOutputStream(OutputStream out) throws IOException { verifySubclass(); bout = new BlockDataOutputStream(out);//块输出流,ObjectOutputStream内部类,起缓冲作用 handles = new HandleTable(10, (float) 3.00);// subs = new ReplaceTable(10, (float) 3.00);// enableOverride = false; writeStreamHeader(); bout.setBlockDataMode(true);//块输出流默认是false,即不起缓冲作用,这里设置true,即在ObjectOutputStream中默认使用块模式 if (extendedDebugInfo) { debugInfoStack = new DebugTraceInfoStack(); } else { debugInfoStack = null; } } /*给子类提供一个路径完全重新实现ObjectOutputStream,不会分配任何用于实现ObjectOutputStream的私有数据 * 如果安装了一个安全管理器,这个方法会先调用安全管理器的checkPermission方法来检查序列化许可来确保可以使用子类 */ protected ObjectOutputStream() throws IOException, SecurityException { SecurityManager sm = System.getSecurityManager(); if (sm != null) { sm.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION); } bout = null; handles = null; subs = null; enableOverride = true; debugInfoStack = null; }
在构造函数中涉及三个内部类BlockDataOutputStream、HandleTable、ReplaceTable和两个方法verifySubclass()和writeStreamHeader();
/** * 验证这个实例(可能是子类实例)可以不用违背安全约束被构造:子类不能重写安全敏感的非final方法,或者其他enableSubclassImplementation序列化许可检查 * 这个检查会增加运行时开支 */ private void verifySubclass() { Class<?> cl = getClass(); if (cl == ObjectOutputStream.class) { return;//不是ObjectOutputStream及其子类的实例直接返回 } SecurityManager sm = System.getSecurityManager(); if (sm == null) { return;//没有设置安全管理器直接返回 } processQueue(Caches.subclassAuditsQueue, Caches.subclassAudits);//从弱引用队列中出队所有类,并移除缓存中相同的类 WeakClassKey key = new WeakClassKey(cl, Caches.subclassAuditsQueue); Boolean result = Caches.subclassAudits.get(key);//缓存中是否已有这个类 if (result == null) { result = Boolean.valueOf(auditSubclass(cl));//检查这个子类是否安全 Caches.subclassAudits.putIfAbsent(key, result);//将结果存储到缓存 } if (result.booleanValue()) { return;//子类安全直接返回 } sm.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);//检查子类实现许可 } /** * 提供writeStreamHeader方法这样子类可以扩展或者预先考虑它们自己的流头部。 * 这个方法写魔数和版本到流中。 */ protected void writeStreamHeader() throws IOException { bout.writeShort(STREAM_MAGIC);//流魔数 bout.writeShort(STREAM_VERSION);//流版本 }
6.5.3 writeObject方法
writeObject方法是一个final修饰的方法,其子类不能直接重写它。若子类想要重写该方法,需要设置enableOverride为true,然后通过调用重写后的writeObjectOverride来实现。
到这里我去了解了下为什么要把一个方法声明成final,除了最简单的已知的“为了安全”以外,还有一个原因是“Java中绑定的所有方法都采用后期绑定技术,除非一个方法已被声明成final。这意味着我们通常不必决定是否应进行后期绑定--它是自动发生的。”这个我有印象类加载的机制中有提及过。所以将一个方法声明称为final,除了防止其他人覆盖这个方法,也因为它可有效地“关闭”动态绑定,或者告诉编译器不需要进行动态绑定,这样一来,编译器就可为final方法调用生成效率更高的代码。
public final void writeObject(Object obj) throws IOException { if (enableOverride) { writeObjectOverride(obj);//子类重写后调用writeObjectOverride return; } try { writeObject0(obj, false); } catch (IOException ex) { if (depth == 0) { writeFatalException(ex); } throw ex; } }
在上面的代码可以看出,writeObject方法在确认子类没有重写后,则进入调用writeObject0方法的分支。
writeObject0这个方法前面都是缓存替换部分,第一次进入这个方法是不会存在这些情况,可以直接看到writeOrdinaryObject这里,因为用于数据化的类是实现了Serializable接口,所以会进入这个分支。
/** * 底层writeobject/writeunshared实现 */ private void writeObject0(Object obj, boolean unshared) throws IOException { boolean oldMode = bout.setBlockDataMode(false);//将输出流设置为非块模式 depth++;//增加递归深度 try { // 处理以前写入的和不可替换的对象 int h; //替代对象映射中这个对象为null的时候写入null代码 if ((obj = subs.lookup(obj)) == null) { writeNull(); return; } //共享模式下且这个对象在句柄的映射表中已有缓存,写入该对象在缓存中的句柄值 else if (!unshared && (h = handles.lookup(obj)) != -1) { writeHandle(h); return; } //如果obj是Class类的实例,则写类名 else if (obj instanceof Class) { writeClass((Class) obj, unshared); return; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared);//写类描述 return; } // 检查替代对象,要求对象重写了writeReplace方法 Object orig = obj; Class<?> cl = obj.getClass(); ObjectStreamClass desc; for (;;) { // REMIND: skip this check for strings/arrays? Class<?> repCl; desc = ObjectStreamClass.lookup(cl, true); if (!desc.hasWriteReplaceMethod() || (obj = desc.invokeWriteReplace(obj)) == null || (repCl = obj.getClass()) == cl) { break; } cl = repCl; } if (enableReplace) { Object rep = replaceObject(obj);、、//如果不重写这个方法直接返回了obj也就是什么也没做 if (rep != obj && rep != null) { cl = rep.getClass(); desc = ObjectStreamClass.lookup(cl, true); } obj = rep; } // 如果对象被替换,第二次运行原本的检查,大部分情况下不执行此段 if (obj != orig) { subs.assign(orig, obj);////将原本对象和替代对象作为一个键值对存入缓存 if (obj == null) { writeNull(); return; } else if (!unshared && (h = handles.lookup(obj)) != -1) { writeHandle(h); return; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return; } } // 剩下的情况 if (obj instanceof String) { writeString((String) obj, unshared); } else if (cl.isArray()) { writeArray(obj, desc, unshared); } else if (obj instanceof Enum) { writeEnum((Enum<?>) obj, desc, unshared); } else if (obj instanceof Serializable) { writeOrdinaryObject(obj, desc, unshared);//传入流的对象第一次执行的是这个方法 } else { if (extendedDebugInfo) { throw new NotSerializableException( cl.getName() + " " + debugInfoStack.toString()); } else { throw new NotSerializableException(cl.getName()); } } } finally { depth--; bout.setBlockDataMode(oldMode); } }
writeOrdinaryObject这个方法主要是在Externalizable和Serializable的接口出现分支,如果实现了Externalizable接口并且类描述符非动态代理,则执行writeExternalData,否则执行writeSerialData。同时,这个方法会写类描述信息。
private void writeOrdinaryObject(Object obj, ObjectStreamClass desc, boolean unshared) throws IOException { if (extendedDebugInfo) { debugInfoStack.push( (depth == 1 ? "root " : "") + "object (class "" + obj.getClass().getName() + "", " + obj.toString() + ")"); } try { desc.checkSerialize(); bout.writeByte(TC_OBJECT); writeClassDesc(desc, false);//写类描述 handles.assign(unshared ? null : obj);//如果是share模式把这个对象加入缓存 if (desc.isExternalizable() && !desc.isProxy()) { //如果实现了Externalizable接口并且类描述符非动态代理 writeExternalData((Externalizable) obj); } else { //否则 writeSerialData(obj, desc); } } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } }
writeExternalData和writeSerialData(Object,ObjectStreamClass)这里有个上下文的操作,目的是保证序列化操作同一时间只能由一个线程调用。writeExternalData直接调用writeRcternal方法,writeSerialData方法中如果传入实例的类重写了writeObject则调用它,否则调用defaultWriteFields。defaultWriteFields方法会先输出基本数据类型,对于非基本数据类型部分会再递归调用writeObject0,所以这里会增加递归深度depth。
private void writeExternalData(Externalizable obj) throws IOException { PutFieldImpl oldPut = curPut; curPut = null; if (extendedDebugInfo) { debugInfoStack.push("writeExternal data"); } SerialCallbackContext oldContext = curContext;//存储上下文 try { curContext = null; if (protocol == PROTOCOL_VERSION_1) { obj.writeExternal(this); } else {//默认协议是2,所以会使用块输出流 bout.setBlockDataMode(true); obj.writeExternal(this);//这里取决于类的方法怎么实现 bout.setBlockDataMode(false); bout.writeByte(TC_ENDBLOCKDATA); } } finally { curContext = oldContext;//恢复上下文 if (extendedDebugInfo) { debugInfoStack.pop(); } } curPut = oldPut; } private void writeSerialData(Object obj, ObjectStreamClass desc) throws IOException { ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout(); for (int i = 0; i < slots.length; i++) { ObjectStreamClass slotDesc = slots[i].desc; if (slotDesc.hasWriteObjectMethod()) {//重写了writeObject方法 PutFieldImpl oldPut = curPut; curPut = null; SerialCallbackContext oldContext = curContext; if (extendedDebugInfo) { debugInfoStack.push( "custom writeObject data (class "" + slotDesc.getName() + "")"); } try { curContext = new SerialCallbackContext(obj, slotDesc); bout.setBlockDataMode(true); slotDesc.invokeWriteObject(obj, this);//调用writeObject方法 bout.setBlockDataMode(false); bout.writeByte(TC_ENDBLOCKDATA); } finally { curContext.setUsed(); curContext = oldContext; if (extendedDebugInfo) { debugInfoStack.pop(); } } curPut = oldPut; } else { defaultWriteFields(obj, slotDesc);//如果没有重写writeObject则输出默认内容 } } } private void defaultWriteFields(Object obj, ObjectStreamClass desc) throws IOException { Class<?> cl = desc.forClass(); if (cl != null && obj != null && !cl.isInstance(obj)) { throw new ClassCastException(); } desc.checkDefaultSerialize(); int primDataSize = desc.getPrimDataSize(); if (primVals == null || primVals.length < primDataSize) { primVals = new byte[primDataSize]; } desc.getPrimFieldValues(obj, primVals);//将基本类型数据的字段值存入缓冲区 bout.write(primVals, 0, primDataSize, false);//输出缓冲区内容 ObjectStreamField[] fields = desc.getFields(false); Object[] objVals = new Object[desc.getNumObjFields()];//获取非基本数据类型对象 int numPrimFields = fields.length - objVals.length; desc.getObjFieldValues(obj, objVals); for (int i = 0; i < objVals.length; i++) { if (extendedDebugInfo) { debugInfoStack.push( "field (class "" + desc.getName() + "", name: "" + fields[numPrimFields + i].getName() + "", type: "" + fields[numPrimFields + i].getType() + "")"); } try { writeObject0(objVals[i], fields[numPrimFields + i].isUnshared());//递归输出 } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } } }
writeClassDesc方法写入类描述信息时,动态代理类和普通类有一些区别,但都是先写这个类本身的信息再写入父类的信息。
private void writeClassDesc(ObjectStreamClass desc, boolean unshared) throws IOException { int handle; if (desc == null) { writeNull();//描述符不存在时写null } else if (!unshared && (handle = handles.lookup(desc)) != -1) { writeHandle(handle);//共享模式且缓存中已有该类描述符时,写对应句柄值 } else if (desc.isProxy()) { writeProxyDesc(desc, unshared);//描述符是动态代理类时 } else { writeNonProxyDesc(desc, unshared);//描述符是标准类时 } } private void writeProxyDesc(ObjectStreamClass desc, boolean unshared) throws IOException { bout.writeByte(TC_PROXYCLASSDESC); handles.assign(unshared ? null : desc);//存入缓存 //获取类实现的接口,然后写入接口个数和接口名 Class<?> cl = desc.forClass(); Class<?>[] ifaces = cl.getInterfaces(); bout.writeInt(ifaces.length); for (int i = 0; i < ifaces.length; i++) { bout.writeUTF(ifaces[i].getName()); } bout.setBlockDataMode(true); if (cl != null && isCustomSubclass()) { ReflectUtil.checkPackageAccess(cl); } annotateProxyClass(cl);//装配动态代理类,子类可以重写这个方法存储类信息到流中,默认什么也不做 bout.setBlockDataMode(false); bout.writeByte(TC_ENDBLOCKDATA); writeClassDesc(desc.getSuperDesc(), false);//写入父类的描述符 } private void writeNonProxyDesc(ObjectStreamClass desc, boolean unshared) throws IOException { bout.writeByte(TC_CLASSDESC); handles.assign(unshared ? null : desc); if (protocol == PROTOCOL_VERSION_1) { // do not invoke class descriptor write hook with old protocol desc.writeNonProxy(this); } else { writeClassDescriptor(desc); } Class<?> cl = desc.forClass(); bout.setBlockDataMode(true); if (cl != null && isCustomSubclass()) { ReflectUtil.checkPackageAccess(cl); } annotateClass(cl);//子类可以重写这个方法存储类信息到流中,默认什么也不做 bout.setBlockDataMode(false); bout.writeByte(TC_ENDBLOCKDATA); writeClassDesc(desc.getSuperDesc(), false);//写入父类的描述信息 }
其他的写方法中,writeString是写入UTF编码的二进制流数据。writeEnum会额外写入一次枚举的类描述,然后将枚举名作为字符串写入。如果是写一个数组,先写入数组长度,然后如果数组是基本数据类型则可以直接写入,否则需要递归调用writeObject0
private void writeString(String str, boolean unshared) throws IOException { handles.assign(unshared ? null : str); long utflen = bout.getUTFLength(str);//获得UTF编码长度 if (utflen <= 0xFFFF) { bout.writeByte(TC_STRING); bout.writeUTF(str, utflen); } else { bout.writeByte(TC_LONGSTRING); bout.writeLongUTF(str, utflen); } } private void writeEnum(Enum<?> en, ObjectStreamClass desc, boolean unshared) throws IOException { bout.writeByte(TC_ENUM); ObjectStreamClass sdesc = desc.getSuperDesc(); writeClassDesc((sdesc.forClass() == Enum.class) ? desc : sdesc, false); handles.assign(unshared ? null : en); writeString(en.name(), false); }
6.5.4 内部类简要介绍
ObjectOutputStream中设计了许多内部类:
-
Caches
-
PutField:提供对要写入的输出流的持久字段的编程访问
-
PutFieldImpl:PutField的子类,是其默认实现。
-
BlockDataOutputStream:块输出流。
-
HandleTable:将对象映射到整数句柄的轻量级标识哈希表,按升序分配。
-
ReplaceTable:将对象映射到替换对象的轻量级标识哈希表
-
DebugTraceInfoStack:保留有关序列化进程状态的调试信息,可用于嵌入到异常信息中区。
下面会主要讲讲BlockDataOutputStream、HandleTable和PutField。
BlockDataOutputStream
BlockDataOutputStream是一个内部类,它继承了OutputStream并实现了DataOutput的接口。缓冲输出流有两种模式:在默认模式下,输出数据和DataOutputStream使用同样模式;在块数据模式下,使用一个缓冲区来缓存数据到达最大长度或者手动刷新时将内容写入下层输入流,这点和BufferedOutputStream类似。不同之处在于,快模式在写数据之前,要先写入一个头部来表示当前块的长度。
从内部变量和构造函数中可以看出,缓冲区的大小是固定且不可修改的,其中包含了一个下层输入流和一个数据输出流以及是否采用快模式的表示,在构造时默认不采用块数据模式。
可以使用setBlockDataMode改变当前的数据模式,从块数据模式切换到非块数据模式,要将缓冲区内的数据写入到下层输入流中。getBlockDataMode可以查询当前的数据模式。
/** * 设置块数据模式为给出的模式true是开启,false是关闭,并返回之前的模式值。 * 如果新的模式和旧的一样,什么都不做。 * 如果新的模式和旧的模式不同,所有的缓冲区数据要在转换到新模式之前刷新。 */ boolean setBlockDataMode(boolean mode) throws IOException { if (blkmode == mode) { return blkmode; } drain();//将缓冲区内的数据全部写入下层输入流 blkmode = mode; return !blkmode; } /** * 当前流为块数据模式返回true,否则返回false */ boolean getBlockDataMode() { return blkmode; }
HandleTable
HandleTable是一个轻量的hash表,它的作用是缓存写过的共享class便于下次查找,内部含有3个数组:spine、next和objs存储的是对象也就是class,spine是hash桶,next是冲突链表,每有一个新的元素插入需要计算它的hash值然后用spine的大小取模,找到它的链表,新对象会被插入到链表的头部,它在objs和next中对应的数据是根据加入的序号顺序存储,spine存储它的handle值也就是在另外两个数组中的下标。
/**表中映射的个数或者下一个有效的句柄*/ private int size; /**决定什么时候扩展hash脊柱的大小阈值*/ private int threshold; /** 计算大小阈值的因子*/ private final float loadFactor; /** 映射hash值->候选句柄值*/ private int[] spine; /** 映射句柄值->下一个候选句柄值*/ private int[] next; /** 映射句柄值->关联的对象*/ private Object[] objs; /** * 创建一个新的hash表使用给定的容量和负载因子 */ HandleTable(int initialCapacity, float loadFactor) { this.loadFactor = loadFactor; spine = new int[initialCapacity]; next = new int[initialCapacity]; objs = new Object[initialCapacity]; threshold = (int) (initialCapacity * loadFactor); clear(); }
assign就是插入操作,它会检查3个数组大小是否足够,其中spine是根据next.length*负载因子来决定阈值的,数组大小扩大是乘以2加1,这个和HashTable时同样的设计。插入的时候注意到next的值被赋为原本的spine[index]值,说明之前的链表头成为了新结点的后驱,也就是说结点被插入链表头部。
/** * 分配下一个有效的句柄给给出的对象并返回句柄值。句柄从0开始升序被分配。相当于put操作 */ int assign(Object obj) { if (size >= next.length) { growEntries(); } if (size >= threshold) { growSpine(); } insert(obj, size); return size++; } /** * 通过延长条目数组增加hash表容量,next和objs大小变为旧大小*2+1 */ private void growEntries() { int newLength = (next.length << 1) + 1;//长度=旧长度*2+1 int[] newNext = new int[newLength]; System.arraycopy(next, 0, newNext, 0, size);//复制旧数组元素到新数组中 next = newNext; Object[] newObjs = new Object[newLength]; System.arraycopy(objs, 0, newObjs, 0, size); objs = newObjs; } /** * 扩展hash脊柱,等效于增加常规hash表的桶数 */ private void growSpine() { spine = new int[(spine.length << 1) + 1];//新大小=旧大小*2+1 threshold = (int) (spine.length * loadFactor);//扩展阈值=spine大小*负载因子 Arrays.fill(spine, -1);//spine中全部填充-1 for (int i = 0; i < size; i++) { insert(objs[i], i); } } /** * 插入映射对象->句柄到表中,假设表足够大来容纳新的映射 */ private void insert(Object obj, int handle) { int index = hash(obj) % spine.length;//hash值%spine数组大小 objs[handle] = obj;//objs顺序存储对象 next[handle] = spine[index];//next存储spine[index]原本的handle值,也就是说新的冲突对象插入在链表头部 spine[index] = handle;//spine中存储handle大小 } //hash值计算就是通过系统函数计算出hash值然后去有符号int的有效位 private int hash(Object obj) { return System.identityHashCode(obj) & 0x7FFFFFFF;//取系统计算出的hash值得有效整数值部分 }
lookup是查找hash表中是否含有指定对象,这里相等必须是==,因为class在完整类名相等时就是==
/** * 查找并返回句柄值关联给与的对象,如果没有映射返回-1 */ int lookup(Object obj) { if (size == 0) { return -1; } int index = hash(obj) % spine.length;//通过hash值寻找在spine数组中的位置 for (int i = spine[index]; i >= 0; i = next[i]) { if (objs[i] == obj) {//遍历spine[index]位置的链表,必须是对象==才是相等 return i; } } return -1;
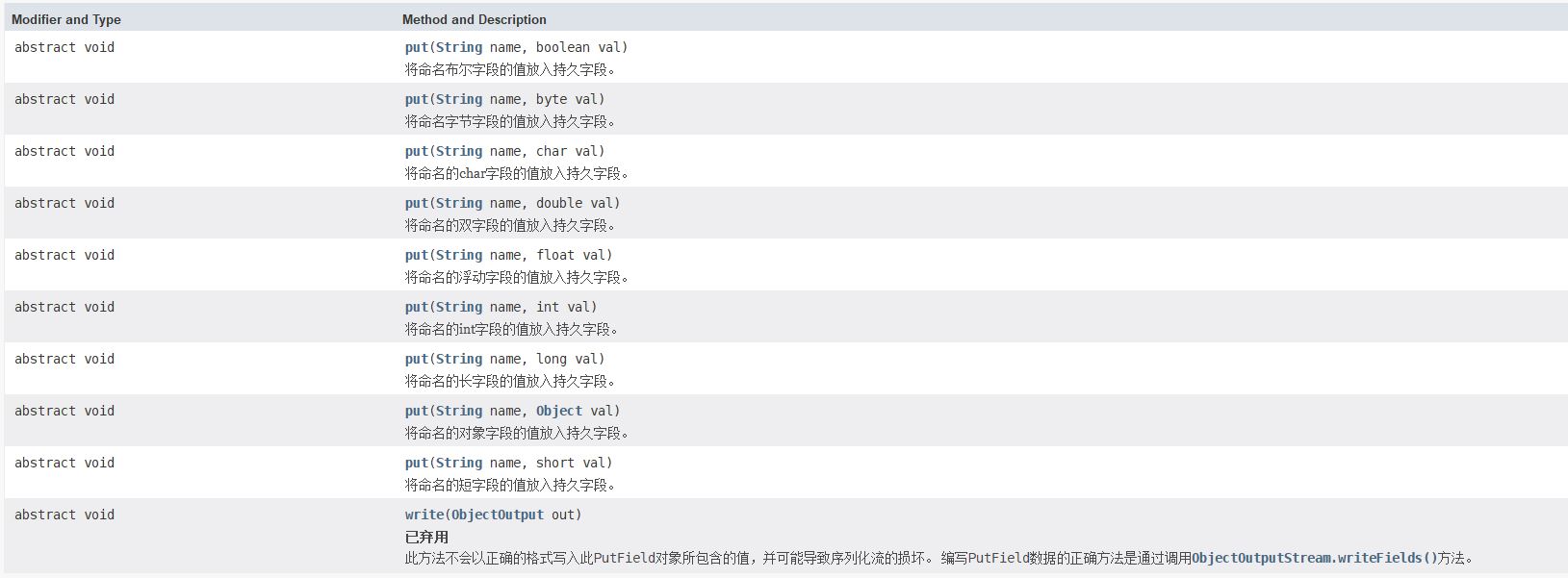
PutField
PutField提供对要写入ObjectOutput的持久字段的编程访问,是一个抽象类,其中PutFieldImpl是其默认实现。
PutField定义了多个put方法,其子类需要实现这些方法。
6.6 ObjectInputStream部分源码分析
ObjectInputStream的实现是跟ObjectOutputStream是对应的,做的是反序列化的工作,即将ObjectOutputStream序列化的数据重新生成Java数据,也从以下五点入手:
-
变量信息
-
构造方法
-
readObject方法
-
内部类简要介绍
6.6.1 变量信息
ObjectInputStream内部包含一个块输入流,因为有handle机制,所以也有一个内部缓存表但不是hash表。
/** 处理数据块转换的过滤流 */ private final BlockDataInputStream bin; /** 确认调用返回列表 */ private final ValidationList vlist; /** 递归深度 */ private long depth; /** 对任何种类的对象、类、枚举、代理的引用总数 */ private long totalObjectRefs; /** 流是否关闭 */ private boolean closed; /** 线柄->obj/exception映射 */ private final HandleTable handles; /** 传递句柄值上下调用栈的草稿区 */ private int passHandle = NULL_HANDLE; /** 当在字段值末尾因没有TC_ENDBLOCKDATA阻塞时设置的标志 */ private boolean defaultDataEnd = false; /** b读取原始字段值的缓冲区 */ private byte[] primVals; /** 如果为true,调用readObjectOverride()来替代readObject() */ private final boolean enableOverride; /** if true, invoke resolveObject()如果为true调用resolveObject() */ private boolean enableResolve; /** * 向上调用类定义的readObject方法期间的上下文,保持当前在被反序列化的对象和当前类的描述符。非readObject向上调用期间为null。 */ private SerialCallbackContext curContext; /** * 类描述符过滤器和从流中读取的类,可能是null */ private ObjectInputFilter serialFilter;
6.6.2 构造函数
ObjectInputStream也包含两个构造函数。
public修饰的构造函数是ObjectInputStream的默认构造函数,在验证了类的安全性之后,对ObjectInputStream内部的块输入流、Handle表、确认调用返回列表等进行初始化。同时会在初始化时自动读取Java序列化头部信息。同时预留了一个生成全控的ObjectInputStream初始化方法,用于继承了ObjectInputStream的子类进行重写。其安全验证和输出流中是相同的,而读取头部信息的方法readStreamHeader需要读取魔数和版本号并验证与当前JDK中的是否一致。
/** * 创建一个ObjectInputStream从指定的InputStream中读取。一个序列化流头部从这个流读取和验证。这个构造器会阻塞直到对应的ObjectOutputStream已经写并刷新了头部。 * 如果安装了安全管理器,这个构造器会在被重写了ObjectInputStream.readFields或ObjectInputStream.readUnshared的子类构造器直接或间接调用的时候检查enableSubclassImplementation序列化许可 */ public ObjectInputStream(InputStream in) throws IOException { verifySubclass(); bin = new BlockDataInputStream(in); handles = new HandleTable(10); vlist = new ValidationList(); serialFilter = ObjectInputFilter.Config.getSerialFilter(); enableOverride = false; readStreamHeader(); bin.setBlockDataMode(true); } protected ObjectInputStream() throws IOException, SecurityException { SecurityManager sm = System.getSecurityManager(); if (sm != null) { sm.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION); } bin = null; handles = null; vlist = null; serialFilter = ObjectInputFilter.Config.getSerialFilter(); enableOverride = true; } protected void readStreamHeader() throws IOException, StreamCorruptedException { short s0 = bin.readShort(); short s1 = bin.readShort(); if (s0 != STREAM_MAGIC || s1 != STREAM_VERSION) { throw new StreamCorruptedException( String.format("invalid stream header: %04X%04X", s0, s1)); } }
6.6.3 readObject方法
readObject方法也是final方法,子类要重写必须通过readObjectOverride实现。如果类里面定义了非基本数据变量,需要进行嵌套读取,outerHandle用来存储上一层读取对象的句柄,然后调用readObject0读取生成对象。完成后要记录句柄依赖,并检查有无异常产生。最上层读取完成之后要发起回调。
public final Object readObject() throws IOException, ClassNotFoundException { if (enableOverride) { return readObjectOverride();//因为是final方法,子类要重写只能通过这里 } // 如果是嵌套读取,passHandle包含封闭对象的句柄 int outerHandle = passHandle; try { Object obj = readObject0(false); handles.markDependency(outerHandle, passHandle);//记录句柄依赖 ClassNotFoundException ex = handles.lookupException(passHandle); if (ex != null) { throw ex; } if (depth == 0) { vlist.doCallbacks();//最上层调用的读取完成后,发起回调 } return obj; } finally { passHandle = outerHandle; if (closed && depth == 0) { clear();//最上层调用退出时清除调用返回列表和句柄缓存 } } }
readObject0必须在块输入流内为空,也就是上一次反序列化完全结束后才能开始,否则会抛出异常。首先,从流中读取一个标志位,判断当前下一个内容是什么类型的。在ObjectOutputStream中,输出的时候会先输出TC_OBJECT,所以在默认情况下也是先读取到TC_OBJECT,也就是先执行readOrdinaryObject。
private Object readObject0(boolean unshared) throws IOException { boolean oldMode = bin.getBlockDataMode(); if (oldMode) {//之前是块输入模式且有未消费的数据会抛出异常 int remain = bin.currentBlockRemaining(); if (remain > 0) { throw new OptionalDataException(remain); } else if (defaultDataEnd) { /* * 流当前在字段值通过默认序列化块写的末尾,因为没有终止TC_ENDBLOCKDATA标记,模拟通常数据结尾的行为 */ throw new OptionalDataException(true); } bin.setBlockDataMode(false); } byte tc; while ((tc = bin.peekByte()) == TC_RESET) {//读到流reset标志 bin.readByte();//消耗缓存的字节 handleReset();//depth为0时执行clear方法,否则抛出异常 } depth++;//增加递归深度 totalObjectRefs++;//增加引用对象数 try { switch (tc) { case TC_NULL: return readNull(); case TC_REFERENCE: return readHandle(unshared); case TC_CLASS: return readClass(unshared); case TC_CLASSDESC: case TC_PROXYCLASSDESC: return readClassDesc(unshared); case TC_STRING: case TC_LONGSTRING: return checkResolve(readString(unshared)); case TC_ARRAY: return checkResolve(readArray(unshared)); case TC_ENUM: return checkResolve(readEnum(unshared)); case TC_OBJECT: return checkResolve(readOrdinaryObject(unshared));//一般会先进入这里 case TC_EXCEPTION: IOException ex = readFatalException(); throw new WriteAbortedException("writing aborted", ex); case TC_BLOCKDATA: case TC_BLOCKDATALONG: if (oldMode) { bin.setBlockDataMode(true); bin.peek(); // force header read throw new OptionalDataException( bin.currentBlockRemaining()); } else { throw new StreamCorruptedException( "unexpected block data"); } case TC_ENDBLOCKDATA: if (oldMode) { throw new OptionalDataException(true); } else { throw new StreamCorruptedException( "unexpected end of block data"); } default: throw new StreamCorruptedException( String.format("invalid type code: %02X", tc)); } } finally { depth--; bin.setBlockDataMode(oldMode); } }
readOrdinaryObject是读取一个自定义类最上层直接调用的方法。几个关键的点,首先是要读取类的描述信息,然后根据类描述符创建一个实例,将对象的实例存储到句柄缓存中并将句柄存储到passHandle,然后读取内部变量数据,最后检查有没有替换对象。
private Object readOrdinaryObject(boolean unshared) throws IOException { if (bin.readByte() != TC_OBJECT) { throw new InternalError(); } ObjectStreamClass desc = readClassDesc(false);//读取类描述信息 desc.checkDeserialize(); Class<?> cl = desc.forClass(); if (cl == String.class || cl == Class.class || cl == ObjectStreamClass.class) { throw new InvalidClassException("invalid class descriptor"); } Object obj; try { obj = desc.isInstantiable() ? desc.newInstance() : null;//根据类描述新建一个实例 } catch (Exception ex) { throw (IOException) new InvalidClassException( desc.forClass().getName(), "unable to create instance").initCause(ex); } passHandle = handles.assign(unshared ? unsharedMarker : obj);//将对象存储到句柄缓存中 ClassNotFoundException resolveEx = desc.getResolveException(); if (resolveEx != null) { handles.markException(passHandle, resolveEx); } //读取序列化内部变量数据 if (desc.isExternalizable()) { readExternalData((Externalizable) obj, desc); } else { readSerialData(obj, desc); } handles.finish(passHandle);//标记句柄对应的对象读取完成 if (obj != null && handles.lookupException(passHandle) == null && desc.hasReadResolveMethod())//存在替换对象 { Object rep = desc.invokeReadResolve(obj); if (unshared && rep.getClass().isArray()) { rep = cloneArray(rep); } if (rep != obj) { // Filter the replacement object if (rep != null) { if (rep.getClass().isArray()) { filterCheck(rep.getClass(), Array.getLength(rep)); } else { filterCheck(rep.getClass(), -1); } } handles.setObject(passHandle, obj = rep); } } return obj; }
那么先来看下怎么读取类的描述信息readClassDesc,从上面方法的case中不能分析出,在没有发生异常使用的情况下,此时的case只会进入TC_PROXYCLASSDESC或者TC_CLASSDESC也就是动态代理类的描述符和普通类的描述符。对于readProxyDesc读取并返回一个动态代理类的类描述符,而readNonProxyDesc则是返回一个普通类的描述符,两个方法都会设置passHandle到动态类描述符的设置句柄。如果类描述符不能被解析为本地虚拟机中的一个类,一个ClassNotFoundException会被关联到描述符的句柄中。关于动态代理和反射的部分下次要再仔细看一下。不过这里又是读取类描述,又是安全检查还有类合法性检查,跟直接在读取端指定类相比额外多出很多开销。
private ObjectStreamClass readClassDesc(boolean unshared) throws IOException { byte tc = bin.peekByte(); ObjectStreamClass descriptor; switch (tc) { case TC_NULL: descriptor = (ObjectStreamClass) readNull(); break; case TC_REFERENCE: descriptor = (ObjectStreamClass) readHandle(unshared); break; case TC_PROXYCLASSDESC: descriptor = readProxyDesc(unshared); break; case TC_CLASSDESC: descriptor = readNonProxyDesc(unshared); break; default: throw new StreamCorruptedException( String.format("invalid type code: %02X", tc)); } if (descriptor != null) { validateDescriptor(descriptor); } return descriptor; } private ObjectStreamClass readProxyDesc(boolean unshared) throws IOException { if (bin.readByte() != TC_PROXYCLASSDESC) { throw new InternalError(); } ObjectStreamClass desc = new ObjectStreamClass(); int descHandle = handles.assign(unshared ? unsharedMarker : desc);//添加描述符到句柄缓存中 passHandle = NULL_HANDLE; int numIfaces = bin.readInt();//接口实现类数量 if (numIfaces > 65535) { throw new InvalidObjectException("interface limit exceeded: " + numIfaces); } String[] ifaces = new String[numIfaces]; for (int i = 0; i < numIfaces; i++) { ifaces[i] = bin.readUTF();//读取接口名 } Class<?> cl = null; ClassNotFoundException resolveEx = null; bin.setBlockDataMode(true); try { if ((cl = resolveProxyClass(ifaces)) == null) { resolveEx = new ClassNotFoundException("null class"); } else if (!Proxy.isProxyClass(cl)) { throw new InvalidClassException("Not a proxy"); } else { //这个检查等价于isCustomSubclass ReflectUtil.checkProxyPackageAccess( getClass().getClassLoader(), cl.getInterfaces()); // Filter the interfaces过滤接口 for (Class<?> clazz : cl.getInterfaces()) { filterCheck(clazz, -1); } } } catch (ClassNotFoundException ex) { resolveEx = ex; } // Call filterCheck on the class before reading anything else filterCheck(cl, -1); skipCustomData(); try { totalObjectRefs++; depth++; desc.initProxy(cl, resolveEx, readClassDesc(false));//初始化类描述符 } finally { depth--; } handles.finish(descHandle); passHandle = descHandle; return desc; } private ObjectStreamClass readNonProxyDesc(boolean unshared) throws IOException { if (bin.readByte() != TC_CLASSDESC) { throw new InternalError(); } ObjectStreamClass desc = new ObjectStreamClass(); int descHandle = handles.assign(unshared ? unsharedMarker : desc);//将描述符存储到句柄缓存中,返回句柄值 passHandle = NULL_HANDLE; ObjectStreamClass readDesc = null; try { readDesc = readClassDescriptor(); } catch (ClassNotFoundException ex) { throw (IOException) new InvalidClassException( "failed to read class descriptor").initCause(ex); } Class<?> cl = null; ClassNotFoundException resolveEx = null; bin.setBlockDataMode(true); final boolean checksRequired = isCustomSubclass(); try { if ((cl = resolveClass(readDesc)) == null) {//通过类描述解析类 resolveEx = new ClassNotFoundException("null class"); } else if (checksRequired) { ReflectUtil.checkPackageAccess(cl); } } catch (ClassNotFoundException ex) { resolveEx = ex; } // Call filterCheck on the class before reading anything else filterCheck(cl, -1); skipCustomData(); try { totalObjectRefs++; depth++; desc.initNonProxy(readDesc, cl, resolveEx, readClassDesc(false));//初始化类描述符 } finally { depth--; } handles.finish(descHandle); passHandle = descHandle; return desc; }
接下来是读取序列化内部变量数据,由于readExternalData除了一些安全性的判断外,直接调用了类中的方法,所以就不看了,直接看readSerialData中默认的读取数据部分defaultReadFields。注意到基本数据类型可以直接通过字节输入流来进行读取,而非基本数据类型则需要递归调用readObject0来读取。
private void defaultReadFields(Object obj, ObjectStreamClass desc) throws IOException { Class<?> cl = desc.forClass(); if (cl != null && obj != null && !cl.isInstance(obj)) { throw new ClassCastException(); } int primDataSize = desc.getPrimDataSize(); if (primVals == null || primVals.length < primDataSize) { primVals = new byte[primDataSize];//第一次进行需要初始化缓冲区,缓冲区不足时需要新建一个更大的缓冲区 } bin.readFully(primVals, 0, primDataSize, false);//将字节流读取到缓冲区 if (obj != null) {//从readSerialData进入这个方法时obj为null desc.setPrimFieldValues(obj, primVals); } int objHandle = passHandle; ObjectStreamField[] fields = desc.getFields(false); Object[] objVals = new Object[desc.getNumObjFields()]; int numPrimFields = fields.length - objVals.length; for (int i = 0; i < objVals.length; i++) { ObjectStreamField f = fields[numPrimFields + i]; objVals[i] = readObject0(f.isUnshared());//递归读取非基本数据类型类 if (f.getField() != null) { handles.markDependency(objHandle, passHandle);//记录依赖 } } if (obj != null) { desc.setObjFieldValues(obj, objVals); } passHandle = objHandle; }
然后看一下其他非基本数据类的读取。readNull读取null代码并将句柄设置为NULL_HANDLE,readString读取UTF编码,readArray需要先读取数组长度,然后根据类的类型进行读取。
private Object readNull() throws IOException { if (bin.readByte() != TC_NULL) { throw new InternalError(); } passHandle = NULL_HANDLE; return null; } private String readString(boolean unshared) throws IOException { String str; byte tc = bin.readByte(); switch (tc) { case TC_STRING: str = bin.readUTF(); break; case TC_LONGSTRING: str = bin.readLongUTF(); break; default: throw new StreamCorruptedException( String.format("invalid type code: %02X", tc)); } passHandle = handles.assign(unshared ? unsharedMarker : str); handles.finish(passHandle); return str; } private Object readArray(boolean unshared) throws IOException { if (bin.readByte() != TC_ARRAY) { throw new InternalError(); } ObjectStreamClass desc = readClassDesc(false); int len = bin.readInt(); filterCheck(desc.forClass(), len); Object array = null; Class<?> cl, ccl = null; if ((cl = desc.forClass()) != null) { ccl = cl.getComponentType(); array = Array.newInstance(ccl, len); } int arrayHandle = handles.assign(unshared ? unsharedMarker : array); ClassNotFoundException resolveEx = desc.getResolveException(); if (resolveEx != null) { handles.markException(arrayHandle, resolveEx); } if (ccl == null) { for (int i = 0; i < len; i++) { readObject0(false); } } else if (ccl.isPrimitive()) { if (ccl == Integer.TYPE) { bin.readInts((int[]) array, 0, len); } else if (ccl == Byte.TYPE) { bin.readFully((byte[]) array, 0, len, true); } else if (ccl == Long.TYPE) { bin.readLongs((long[]) array, 0, len); } else if (ccl == Float.TYPE) { bin.readFloats((float[]) array, 0, len); } else if (ccl == Double.TYPE) { bin.readDoubles((double[]) array, 0, len); } else if (ccl == Short.TYPE) { bin.readShorts((short[]) array, 0, len); } else if (ccl == Character.TYPE) { bin.readChars((char[]) array, 0, len); } else if (ccl == Boolean.TYPE) { bin.readBooleans((boolean[]) array, 0, len); } else { throw new InternalError(); } } else { Object[] oa = (Object[]) array; for (int i = 0; i < len; i++) { oa[i] = readObject0(false); handles.markDependency(arrayHandle, passHandle); } } handles.finish(arrayHandle); passHandle = arrayHandle; return array; }
readHandle方法从缓存中寻找该对象
private Object readHandle(boolean unshared) throws IOException { if (bin.readByte() != TC_REFERENCE) { throw new InternalError(); } passHandle = bin.readInt() - baseWireHandle;//因为写的时候handle值加上了baseWireHandle if (passHandle < 0 || passHandle >= handles.size()) { throw new StreamCorruptedException( String.format("invalid handle value: %08X", passHandle + baseWireHandle)); } if (unshared) { // REMIND: what type of exception to throw here? throw new InvalidObjectException( "cannot read back reference as unshared"); } Object obj = handles.lookupObject(passHandle);//缓存中寻找该对象 if (obj == unsharedMarker) { // REMIND: what type of exception to throw here? throw new InvalidObjectException( "cannot read back reference to unshared object"); } filterCheck(null, -1); // just a check for number of references, depth, no class检查引用数量,递归深度,是否有这个类 return obj; }
6.6.4 内部类简要介绍
ObjectInputStream涉及的内部类包含:
-
Caches:安全审计缓存
-
Logging:用于将日志模块推迟到需要时的单独的类
-
GetField:提供对从输入流读取的持久字段的访问
-
GetFieldImpl:GetField的子类,是其默认实现
-
ValidationList:对象图完全反序列化后要执行的回调的优先级列表
-
FilterValues:接口ObjectInputStreamFilter.FilterInfo的子类,保存要传递给ObjectInputFilter的值得快照。
-
PeekInputStream:InputStream的子类,支持单字节peek操作的输入流
-
BlockDataInputStream:块输入流
-
HandleTable:跟踪线句柄到对象映射的非同步表。
以下详细说说BlockDataInputStream、HandleTable和GetField。
BlockDataInputStream
BlockDatainputStream是具有两种模式的输入流:在默认模式下,以与DataOutputStream相同的格式写入的输入数据;在“块数据”模式下,输入由块数据标记括起来的数据。缓冲取决于块数据模式:在默认模式下,没有数据被预先缓冲;当处于块数据模式时,当前数据块的所有数据将立即读入(并缓冲)。
内部变量需要注意两个不同的输入流,din是块输入流,in是取数输入流,in中的下层输入流是最初在构造ObjectInputStream中传入的变量,所以通常是FileInputStream。
/** 最大数据块长度1K */ private static final int MAX_BLOCK_SIZE = 1024; /** 最大数据块头部长度 */ private static final int MAX_HEADER_SIZE = 5; /** 可调节的字符缓冲的长度作为供读取的字符串 */ private static final int CHAR_BUF_SIZE = 256; /** 返回的值指示头部可能阻塞 */ private static final int HEADER_BLOCKED = -2; /** 读取一般/块数据的缓冲区 */ private final byte[] buf = new byte[MAX_BLOCK_SIZE]; /** 读取块数据头部的缓冲区 */ private final byte[] hbuf = new byte[MAX_HEADER_SIZE]; /** 快速字符串读取的字符缓冲区 */ private final char[] cbuf = new char[CHAR_BUF_SIZE]; /** block data mode */ private boolean blkmode = false; // 块数据状态字段,这些值仅在blkmode为true时有意义 /** 当前进入buf的偏移 */ private int pos = 0; /** buf中有效值的结束偏移,没有更多块数据buf时为-1 */ private int end = -1; /** 在当前block中还没有从流中读取的字节数 */ private int unread = 0; /** 下层流包装在可见过滤流中 */ private final PeekInputStream in; /** 回路流用于扩展数据块的数据读取 */ private final DataInputStream din;
构造函数就是初始化两个流变量
BlockDataInputStream(InputStream in) { this.in = new PeekInputStream(in); din = new DataInputStream(this); }
setBlockDataMode是切换快输入流的模式,true代表打开块模式。不同的是,若输入流在从快模式切换到默认模式时,若缓冲区仍有未消费的块数据,会抛出IllegalStateException。
boolean setBlockDataMode(boolean newmode) throws IOException { if (blkmode == newmode) { return blkmode; } if (newmode) {//从关闭到打开,重置块数据参数状态 pos = 0; end = 0; unread = 0; } else if (pos < end) {//从打开到关闭且有未消费的块数据 throw new IllegalStateException("unread block data"); } blkmode = newmode; return !blkmode; }
除此之外,暂不对BlockInputStream的方法进行深入了解,只提及一点,BlockInputStream中涉及java.io.Bits类,Bits类功能主要是字节转换 将字节数组转换为基本数据类型 或者将基本数据类型转为byte数组(全部为网络字节序)。
HandleTable
HandleTable是跟踪线句柄到对象映射以及与反序列化对象关联的ClassNotFoundException的非同步表。此类实现了一个异常传播算法,用于确定哪些对象具有与其关联的ClassNotFoundException,同时考虑对象图中的循环和不连续性(如,跳过的字段)。
该表的一般用途如下:在反序列化过程中,首先通过调用assign方法为给定对象分配句柄。此方法使分配的句柄保持“打开”状态,其中可以通过调用markDependency方法注册对其他句柄的异常状态的依赖关系,或者通过调用markException将异常直接与句柄关联。当句柄被标记为异常时,HandleTable负责将异常传播到依赖于(传递性地)异常标记对象的任何其他对象。
一旦注册了句柄的所有异常信息/依赖项,就应该通过调用句柄上的finish方法来关闭该句柄。完成句柄的行为允许异常传播算法积极地修剪依赖关系链接,从而减少异常跟踪对性能/内存的影响。请注意,使用的异常传播算法取决于按先进先出顺序分配/完成的句柄;然而,为了简单和节省内存,它不强制执行此约束。
以上是源码中HandleTable的注释。
ObjectInputStream中的HandleTable比起输入流中的来说,多了一个HandleList[] deps来存储依赖。HandleList是HandleTable的内部类,可以理解为一个建议版的ArrayList,当数组被填满时再次增加元素的时候,自动分配一个新的2配大小的数据,把就的数据复制过去再插入新的。另外两个数组,Object[] entries存储对象或异常,byte[] status存储对象的状态。并且这个缓存表并没有使用hash,它是依靠ObjectInputStream中的passHandle来获取位置的。
/** array mapping handle -> object status 句柄->对象状态的数组映射*/ byte[] status; /** array mapping handle -> object/exception (depending on status) */ Object[] entries; /** array mapping handle -> list of dependent handles (if any) */ HandleList[] deps; /** lowest unresolved dependency 最低的未解决依赖*/ int lowDep = -1; /** number of handles in table */ int size = 0;
从assign可以看到,对象和它的状态(默认为UnKNOW)被顺序存储到了数组中,并返回下标值。
int assign(Object obj) { if (size >= entries.length) { grow(); } status[size] = STATUS_UNKNOWN; entries[size] = obj; return size++; }
那么deps这个数组到底是干什么的?我们可以一步步来分析,首先,寻找deps在HandleTable中被修改的地方,排除构造初始化,clear和grow增加空间外,deps数组的用途关键在markDependency和markException两个方法中。
markException的所有调用都是发生在出现ClassNotFoundException的时候,传入参数是类的handle值和异常。“markDependency关联一个ClassNotFoundException和当前活动句柄并传播它到其他合适的引用对象,这个特定句柄必须是打开的。”即,如果一个类解析失败,那么添加到entries缓存里的对象会是一个异常,它对象的status为STATUS_EXCEPTION。
void markException(int handle, ClassNotFoundException ex) { switch (status[handle]) { case STATUS_UNKNOWN: status[handle] = STATUS_EXCEPTION;//标记当前对象状态为异常 entries[handle] = ex;//修改缓存中的对象为异常 // propagate exception to dependents传播异常给依赖 HandleList dlist = deps[handle]; if (dlist != null) { int ndeps = dlist.size(); for (int i = 0; i < ndeps; i++) { markException(dlist.get(i), ex);//递归传播依赖列表内的所有对象 } deps[handle] = null;//清除依赖表中的对象,因为只要再有对象关联到相同类它必然是会从缓存中获取异常,不再需要依赖表项 } break; case STATUS_EXCEPTION: break; default: throw new InternalError(); } }
而markDependency的调用有三处(readObject调用readObject0之后、readArray中读取非基本数据类型调用readObject0之后和defalutReadFileds中递归读取非基本数据类中),每一处的传入参数都是上一层对象的句柄和本层对象的句柄。可以推测出来这里deps的作用是在一层层读取对象时(如自定义类中又有自定义类),记录下一层指向上一层的关系,用来传递异常状态。
从代码中可以看出,在存在依赖双方的情况下,如果上一层状态是unknow,下一层状态是EXCEPTION,则从依次向上将整个依赖表上所有的状态全部置为Exception,如果下一层也是UNKWON状态,则在下一层的依赖表中增加上一层的句柄,并将位置状态最底层设为target。如果上一层状态是OK,则出现InternalERrror,因为上一层的句柄已经被关闭,不能再增加对它依赖的对象。
void markDependency(int dependent, int target) { if (dependent == NULL_HANDLE || target == NULL_HANDLE) { return; } switch (status[dependent]) { case STATUS_UNKNOWN: switch (status[target]) { case STATUS_OK: // ignore dependencies on objs with no exception忽略没有异常的对象上依赖 break; case STATUS_EXCEPTION: // eagerly propagate exception急切传播的异常 markException(dependent, (ClassNotFoundException) entries[target]);//如果依赖是未知状态也需将它们改为异常状态 break; case STATUS_UNKNOWN: // add to dependency list of target增加到依赖目标列表 if (deps[target] == null) { deps[target] = new HandleList(); } deps[target].add(dependent); // remember lowest unresolved target seen记录被看见最低的未解决目标 if (lowDep < 0 || lowDep > target) { lowDep = target; } break; default: throw new InternalError(); } break; case STATUS_EXCEPTION: break; default: throw new InternalError(); } }
finish方法的作用是关闭句柄,是唯一可以将状态设为STATUS_OK的方法,标记给出的句柄为结束状态,说明这个句柄不会有新的依赖标记。调用设置和结束方法必须以后进后出的顺序。必须要handle之前不存在无法确认的状态才能修改状态为OK。
void finish(int handle) { int end; if (lowDep < 0) { // 没有还没处理的未知状态,只需要解决当前句柄 end = handle + 1; } else if (lowDep >= handle) { // handle之后存在还没有处理的未知状态,但上层句柄都已经解决了 end = size; lowDep = -1; } else { // handle之前还有没有处理的向前引用,还不能解决所有对象 return; } // change STATUS_UNKNOWN -> STATUS_OK in selected span of handles for (int i = handle; i < end; i++) { switch (status[i]) { case STATUS_UNKNOWN: status[i] = STATUS_OK; deps[i] = null; break; case STATUS_OK: case STATUS_EXCEPTION: break; default: throw new InternalError(); } } }
GetField
GetField提供了对从输入流读取的持久性字段的访问,是一个抽象类,其中GetFieldImpl是其默认实现。
GetField定义了多个get方法,其子类需要实现这些方法。
6.7 总结
序列化相关的知识点比我想象的复杂,后面应该会另外再去了解一下。而有关ObjectOutputStream和ObjectInputStream的源码解析,因为比较复杂,大部分是参考了