写随笔大概也是做笔记记录下自己思考的意思吧,之前有些事情觉得做随笔还是比较有用的,mark一下一个有用的网址
关于rdd的操作,网上有很多很多的教程,当初全部顺一遍,除了对rdd这个类型有了点概念,剩下具体的方法以及方法的写法已经快忘记了,所以具体还是记一下对某些事情的思考吧。
关于将rdd保存为文件,我使用的是
import org.apache.spark.{SparkConf, SparkContext} object Wordcount { def main(args: Array[String]): Unit = { val conf=new SparkConf().setAppName("wordcount").setMaster("local") val sc=new SparkContext(conf) val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2))) val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2))) //求jion val rdd3 = rdd1.union(rdd2) //按key进行聚合 val rdd4 = rdd3.reduceByKey(_ + _) rdd4.collect().foreach({println}) //按value的降序排序 val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1)) rdd5.collect().foreach({println}) rdd5.saveAsTextFile("aaaaa1") } }
以上代码,rdd是我通过将两个rdd合并后得到,查看的时候发现rdd5是有两个分区的,输出结果是:

而保存的文件aaaa1则是一个文件夹,所以如果已存在会报文件已存在的错误无法运行(源代码里应该没有做相关的判断和处理),最终结果生成在文件夹中,如下:
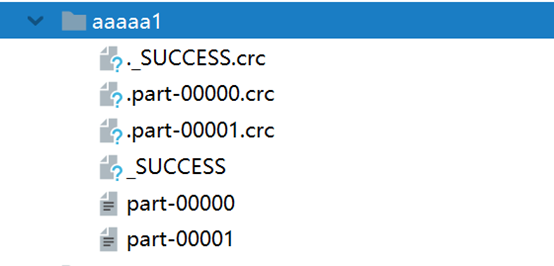
具体的数据保存在后两个文件夹中:
part-00000:
(jerry,5)
part-00001:
(tom,2) (shuke,2) (kitty,2)
这是按rdd5里面本身的分区数,各分区内容来生成的,而crc指的是循环冗余,.crc文件是指文件摘要,好像并没有什么特殊的,就是进行crc校验的文件。我本来以为crc和几个分区文件的联系有关系,后来想想spark处理大量数据的时候各分区数据的联系也并不算紧密,基本不会去区分前后顺序,并不需要保存彼此的联系。
大概发现了两件事情:
1、是小文件产生的大量冗余,有时候这些是没必要的,给读写它带来了一些麻烦,但是这个是有方法解决的,暂时还没有涉猎。
2、分区间不平衡,虽然只是很少条数据,但是之前也有做过某些RDD练习也说明rdd里分区并不会实时帮你平衡各分区的数据数量,但是spark有提供相应的方法,其他的,比如hive可能就不一定了。