MapReduce计算框架
一、MapReduce实现原理
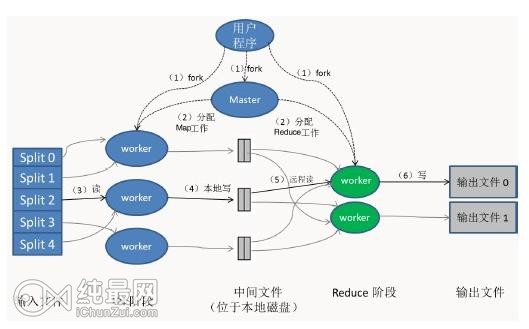
图展示了MapReduce实现中的全部流程,处理步骤如下:
1、用户程序中的MapReduce函数库首先把输入文件分成M块(每块大小默认64M),在集群上执行处理程序,见序号1
2、主控程序master分配Map任务和Reduce任务给工作执行机器worker。见序号2
3、一个分配了Map任务的worker读取并处理输入数据块。从数据片段中解析出key/value键值对,然后把其传递给Map函数,由Map函数生成并输出中间key/value键值对集合,暂缓内存中。见序号3
4、缓存中key/value键值对通过分区函数分成R个区域,之后周期性地写到本地磁盘上。同时将本地磁盘的存储位置传给master,由master负责把这些存储位置再传递给Reduce worker,见序号4
5、当Reduce worker收到master的存储位置信息后,使用RPC从Map worker所在的磁盘上读取数据。最后通过对key进行排序使得具有key值的数据聚合到一起。见序号5
6、Reduce worker程序遍历排序后的中间数据。Reduce worker程序将这个key值和相关的中间value值的集合传递给Rdeduce函数,最后,Reduce的输出被追加到所属分区的输入文件。见序号6
二、计算流程与机制
2.1、作业提交和初始化
MapReduce的JobTracker接收到客户端提交的作业后首先要把作业初始化为Map任务和Reduce任务,然后等待调度执行。

图中展示了MapReduce客户端提交作业以及初始化的流程。
作业提交过程:
1、命令行提交。调用JobClient.runJob()方法开始提交,最终通过Job对象内部JobClient对象的submitJobInternal方法来提交作业到JobTracker。
2、作业上传。在提交到JobTracker之前还需要完成相关的初始化工作(获取用户作业的JobId,创建HDFS目录,上传作业、相关依赖库,需要分发的文件等到HDFS上,获取用户输入数据的所有分片信息)。
3、产生切片文件。在作业提交后,JobClient调用InputFormat中的getSplits()方法产生用户数据的split分片信息。
4、提交作业到JobTracker。JobClient通过RPC将作业提交到JobTracker作业调度器中,首先为作业创建JobInProgress对象,用于跟踪正在运行的作业的状态和进度。其次检查用户是否具有指定队列的作业提交权限。接着检查作业配置的内存使用量是否合理。最后通过TaskScheduler初始化作业,JobTracker收到提交的作业后,会交给TaskScheduler调度器,然后按照一定的策略对作业执行初始化操作。
作业的初始化:主要是构造Map Task和Reduce Task并对他们进行初始化操作,主要是调度器调用JobTracker.initJob()方法来进行的。具体分为四个类型的任务:
Setup Task--->Map Task--->Reduce Task--->Cleanup Task
2.2、Mapper
在作业提交完成之后,就开始执行Map Task任务了,Mapper的任务就是执行用户的Map()函数将输入键值对(key/value pair)映像到一组中间格式的键值对集合。
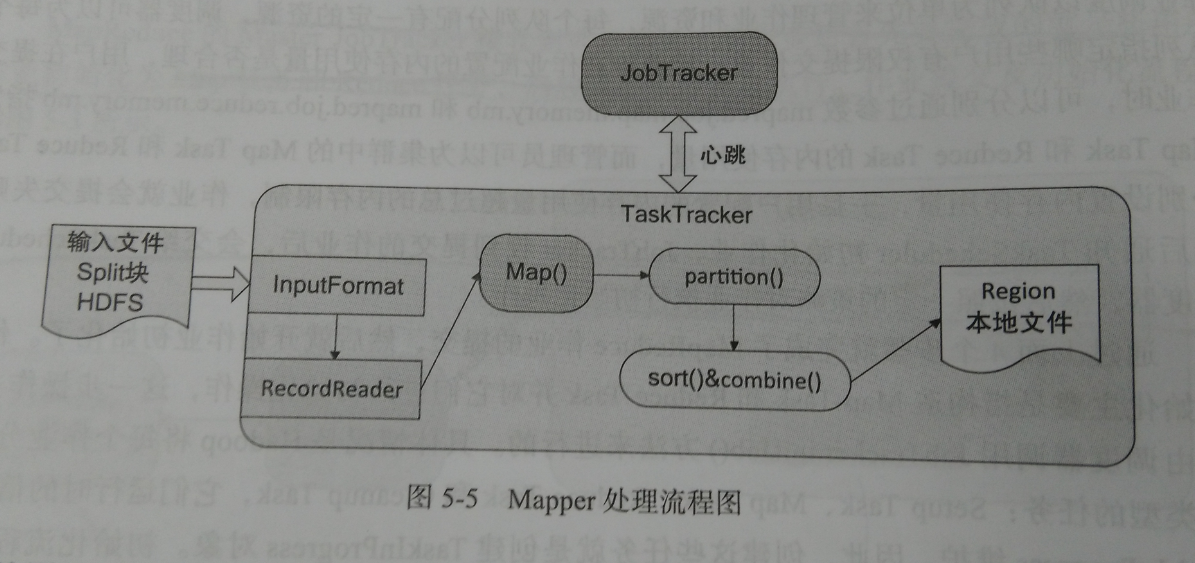
图中是Mapper的处理流程图。Mapper的输入文件在HDFS上;InputFormat接口描述文件的格式信息,通过这个接口可以获得InputSplit的实现,然后对输入的数据进行切分;每一个Split分块对应一个Mapper任务,通过RecordReader对象从输入分块中读取并生成<k,v>键值对;Map函数接收这些键值对根据用户的Map函数进行处理后输出<k1,v1>键值对,Map函数通过context.collect方法将结果写到context对象中;当Mapper的输出键值对被收集后,他们会被Partitioner类中的partition()函数以指定的分区写到输出缓冲区,同时调用sort函数对输出进行排序,如果用户为Mapper指定了Combiner,则在Mapper输出它的键值对<k1,v1>时,不会马上写到输出中,会被收集在list对象中,当写入一定数量的键值对,这部分缓冲会被Combiner中的combine函数合并,然后输出被写入本地文件系统之后会进入Reduce阶段。
2.3、Reducer
Reducer有三个主要阶段:Shuffer、Sort和Reduce,处理流程图为:
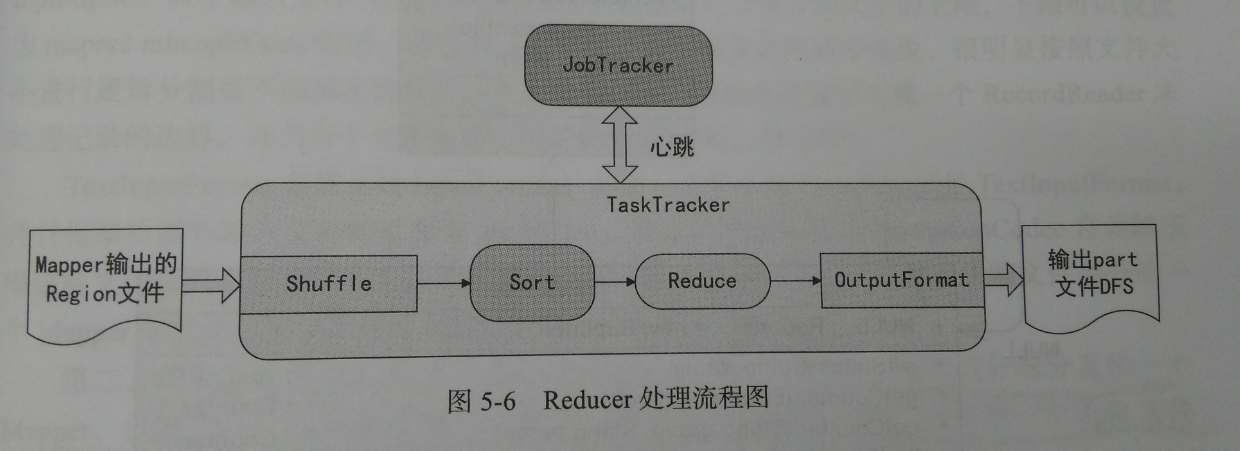
Reducer的整个处理流程为:
1、Shuffle阶段,此时Reducer的输入就是Mapper已经排序好的输出。可以理解为混洗阶段,相当于数据复制阶段。
2、Sort阶段,按照key值对Reducer的输入进行分组,Shuffle和Sort是同时进行的。
3、Reduce阶段,通过前两个阶段得到的<key,(list of values)>会送到Reducer中的reduce()函数中处理。输出的结果通过OutputFormat输出到DFS中。
2.4、Reporter和OutputCollector
Reporter是用于MapReduce应用程序报告进度,设定应用级别的消息,更新Counters计数器的机制。

OutputCollector是一个由Map/Reduce框架提供的,用于收集Mapper和Reducer输出数据的通用机制,老版本用collect函数,新版本用write函数。
三、MapReduce的I/O格式
3.1、输入格式
Hadoop中的MapReduce框架依赖InputFormat提供数据输入,也就是InputFormat为MapReduce作业描述输入的细节规范。InputFormat有三个作用:
1、检查作业输入的有效性。
2、把输入文件切分成多个逻辑InputSplit实例,并把每一个实例分别分发给一个Mapper,也就是一个Mapper的输入只对应一个逻辑InputSplit,只处理一个Split文件的数据块。
3、提供ReduceReader的实现。从逻辑InputSplit中获取输入记录,这些记录将由Mapper处理,Mapper利用该实现从InputSplit中读取输入的<K,V>键值对。
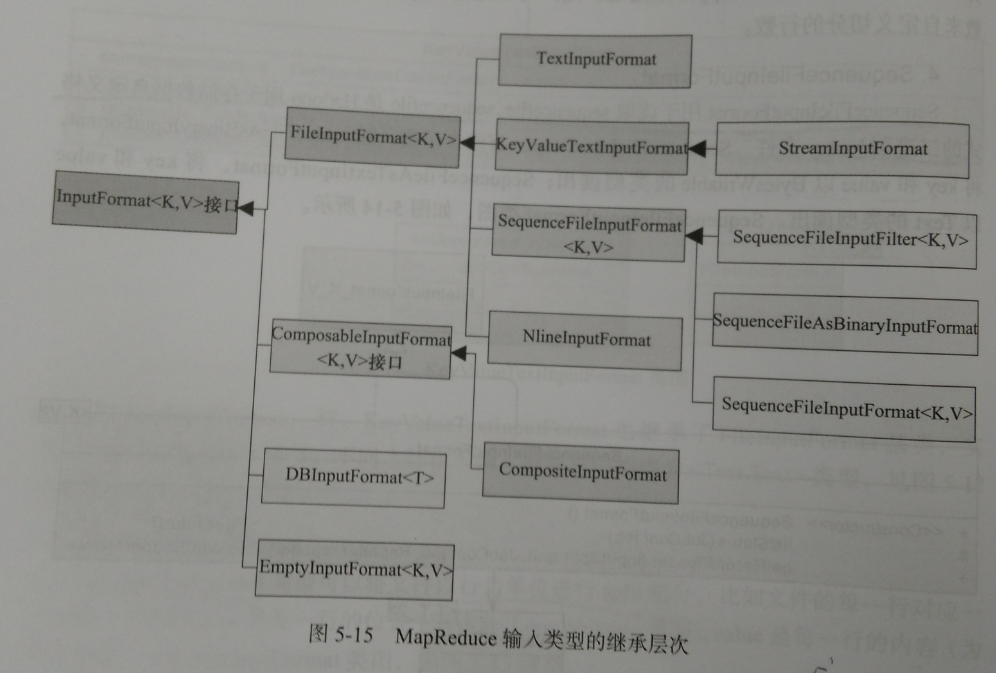
1、TextInputFormat
用于读取纯文本文件,是Hadoop默认的InputFormat的派生类。LineRecordReader将Inputsplit解析成<key,value>对,key是每一行的位置(偏移量,为LongWritable类型),value是每一行的内容(为Text类型)。类图如下。
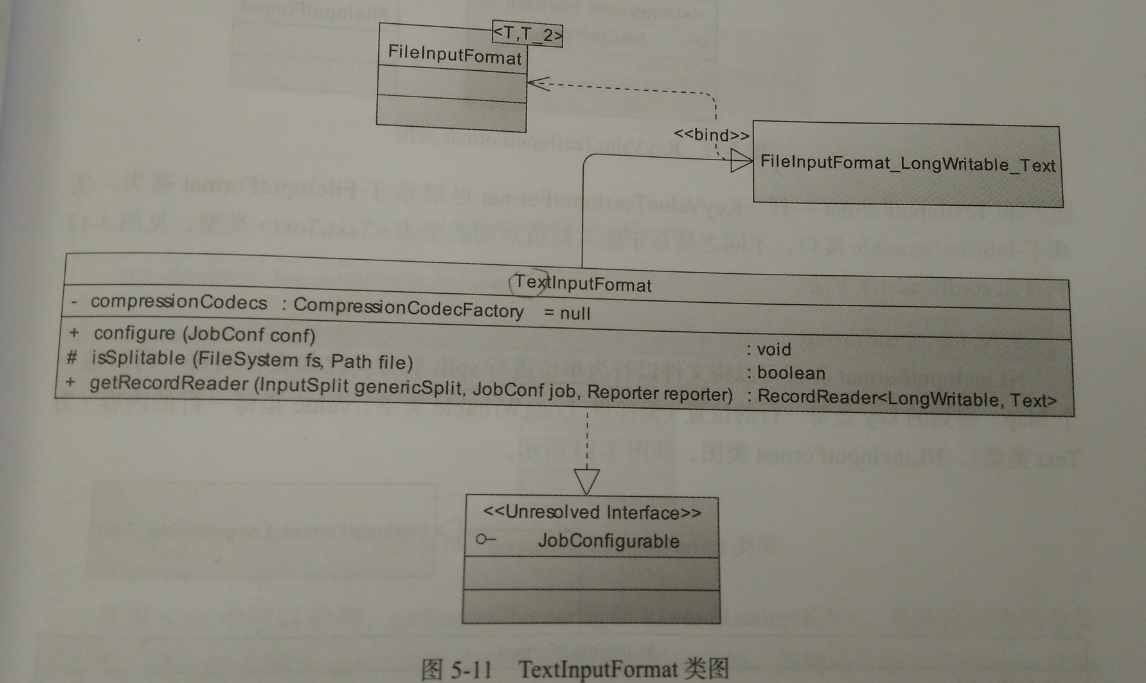
通过类图看出,TextInputFormat类继承了FileInputFormat基类,实现了JobConfigure接口,实现了InputFormat中的getRecordReader这一方法,返回一个RecordReader用于划分中读取<key,value>键值对。
2、KeyValueTextInputFormat
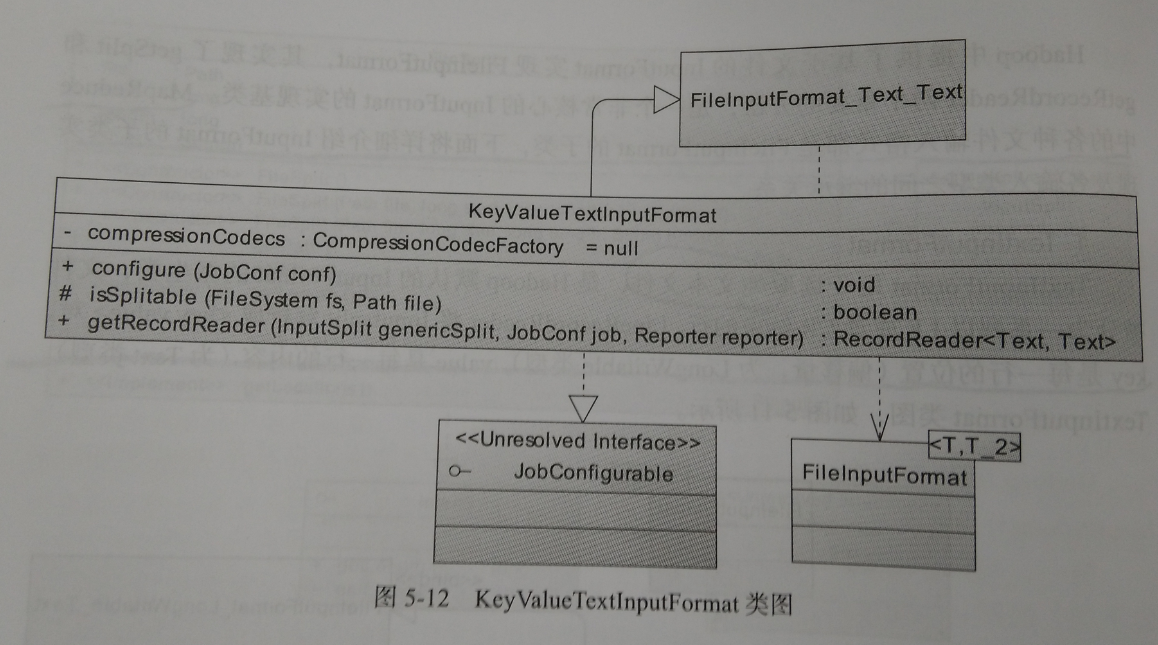
类似TextInputFormat一样。
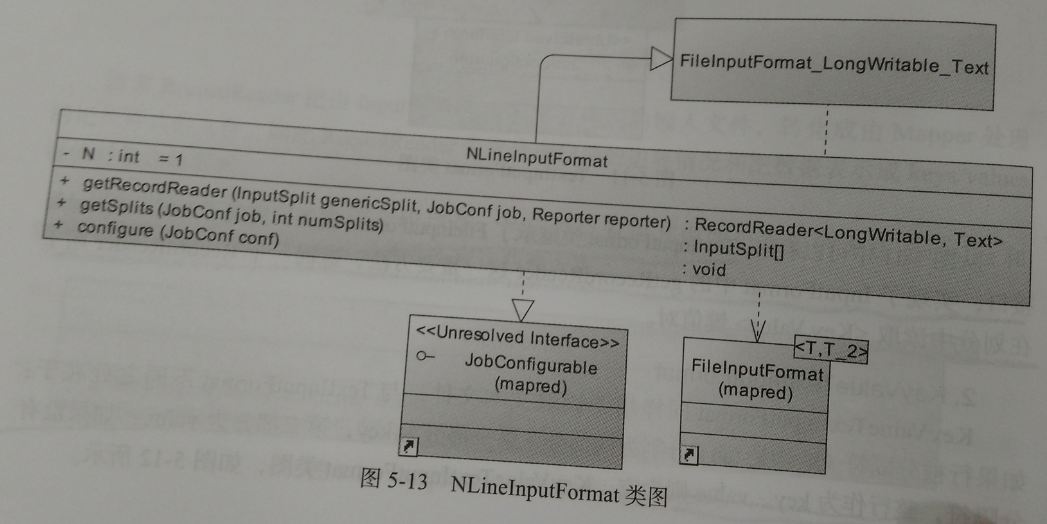
3、NLineInputFormat
这个类型可以将文件以行为单位进行split切分,比如每一行对应一个Map,得到key是每一行的位置,value是每一行的内容。这里的N指的是每一个Mapper接收的对应一个mapper来处理。
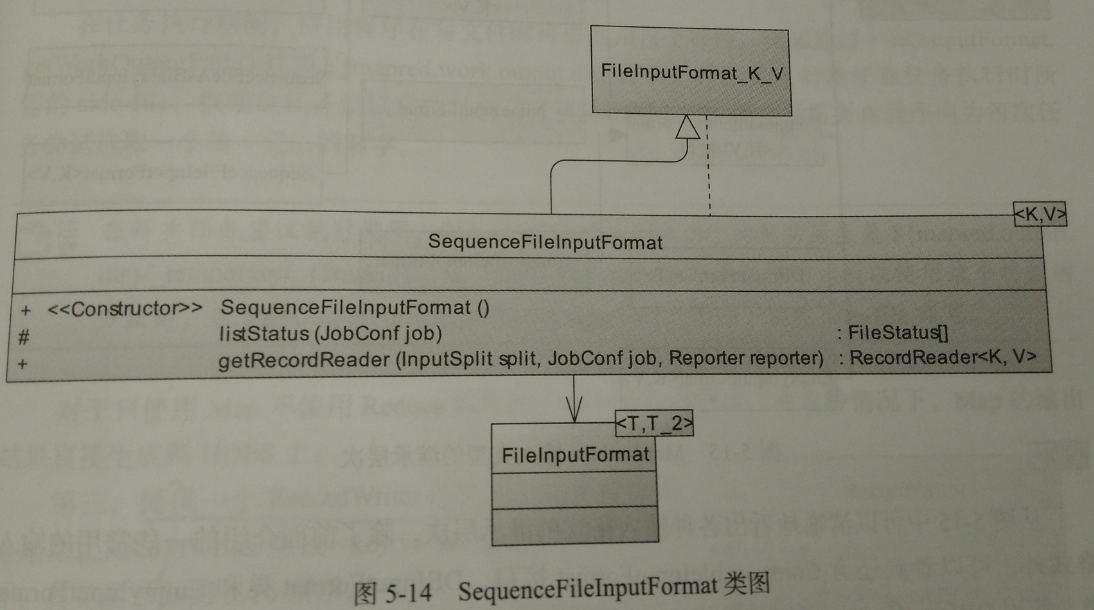
4、SequenceFileInputFormat
用于读取sequencefile。sequence是hadoop用于存储数自定义格式的二进制binary文件。其主要有两个子类。SequenceFileAsBinaryInputFormat用于处理二进制数据。SequenceFileAsTextInputFormat,主要是为了适应Hadoop streaming接口而设计的,在读取键值对后会调用toString()方法将key和value类型转化为Text类型对象。
3.2、输出格式
hadoop中的OutputFormat用来描述MapReduce作业的输出格式。OutputFormat主要有三个作用:
1、检验作业的输出
2、验证输出结果类型是否如在Config中所配置的。
3、提供一个RecordWriter的实现,用来输出作业结果。RecordWriter生成<key,value>键值对到输出文件。
1、TextOutputFormat
是默认的输出格式,就是输出纯文本文件,格式为key+" "+value,key与value之间默认以 分割。

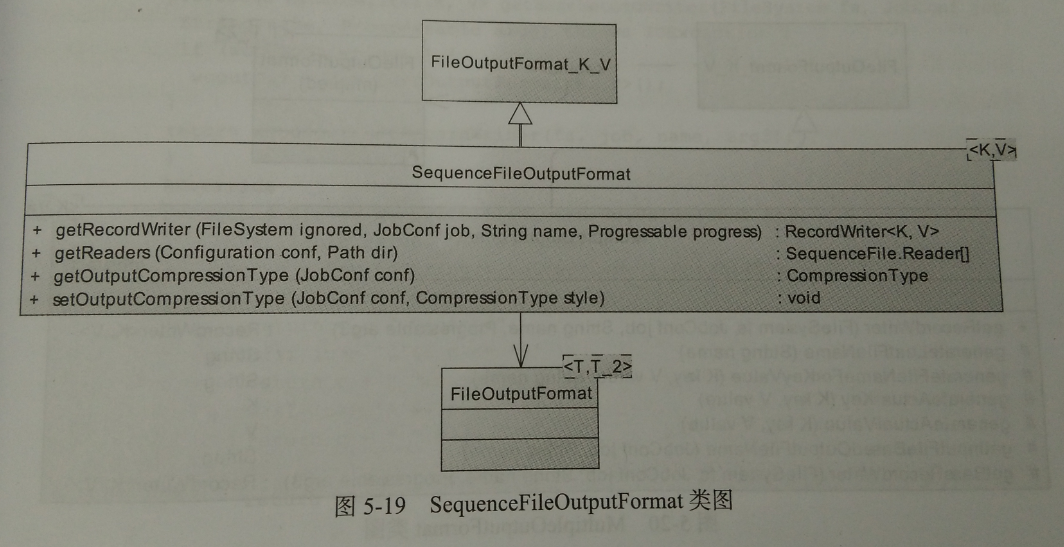
2、SequeceFileOutputFormat
和输入类似
3、MapFileOutputFormat
这个输出类型可以将数据输出为hadoop中的MpaFile文件格式。MapFile与SequenceFile类似。
4、MultipleOutputFormat
是hadoop类中的多路输出