1、首先要下载poi相关的包:http://poi.apache.org/ ,以下是所需的jar包
2、贴上详细的代码
public class ExcelToXml { /** * 将excel的数据转换成xml格式 * @param excelPath * @param xmlPath * @throws Exception */ public static void generateXml(final String excelPath, final String xmlPath) throws Exception{ //格式化输出 final OutputFormat format = OutputFormat.createPrettyPrint(); //指定XML编码 format.setEncoding("UTF-8"); //用于指定显示和编码方式 final XMLWriter output = new XMLWriter(new FileWriter(xmlPath), format); //定义一个XML文档对象 final Document document = DocumentHelper.createDocument(); //获取根节点 Element root = document.getRootElement(); //获取excel文件 final File tempFile =new File(excelPath.trim()); //获取带后缀的文件名,例如system.xlsx final String fileName = tempFile.getName(); //获取后面的部分,例如.xlsx final String prefix=fileName.substring(fileName.lastIndexOf(".")); //获取后面部分的长度 int num=prefix.length(); //获取去掉了后缀的文件名,例如system final String fileOtherName=fileName.substring(0, fileName.length()-num); //创建根节点 //e.g. <system position="system.xlsx"> if( root == null) { root = document.addElement(fileOtherName); root.addAttribute("position",fileName); } //利用工厂读取excel可以不需要关心excel的版本问题 final Workbook wb = WorkbookFactory.create(new File(excelPath)); //获取sheet页的数量 final int sheetNum = wb.getNumberOfSheets(); System.out.println("sheet页的数量:"+sheetNum); //循环读取每一个页sheet的内容start for(int i = 0; i < sheetNum; i++) { //读取某一页sheet final Sheet sheet = wb.getSheetAt(i); //标记是否接下来的是否为FieldIdLabel(数据行是否为属性名) boolean isFieldIdLabel = false; //标记是否接下来的是否为FieldValue(数据行是否为值) boolean isFieldValue = false; //每一行具有数据值的列数量 int coloumNum = 0; //定义一个集合存放FieldIdLabel final List<String> fields = new ArrayList<String>(); //获取每一页sheet底下Tab的名字 final String sheetName = sheet.getSheetName(); System.out.println("一级节点:"+sheetName); //定义prePosition,拼接存储位置,e.g. system.xlsx,role final String prePosition=new String(fileName+","+sheetName); //添加一级节点 //e.g <sheet id="role" position="system.xlsx,role"> final Element firstElm = root.addElement("sheet"); firstElm.addAttribute("id",sheetName); firstElm.addAttribute("position",prePosition.toString()); //定义二级节点 Element secondElm = null; //定义三级节点 Element thirdElm = null; //循环读取每一行的内容start for (final Row row : sheet) { //获取每一行具有可读数据值的列数量 coloumNum = row.getPhysicalNumberOfCells(); System.out.println("列的数量:"+coloumNum); //行数 final String rowNum=String.valueOf(row.getRowNum() + 1); //定义四级节点 Element fourthElm = null; //标志是否接下来row的FieldValue是数据行 boolean isNextRow = true; //循环读取每一列的值start for (final Cell cell : row) { //将单元格的内容转换成字符串 final String cellStr = cellValueToString(cell); //单元格的列索引 final int cellIndex = cell.getColumnIndex(); //各种不同的情况start if (cellStr.startsWith("##")) { //第一种情况##Role System.out.println("第一种情况##"); //获取##后面的值,例如##Role,截取之后是Role final String cellElm = cellStr.substring(2); System.out.println("二级节点:"+cellElm); //添加二级节点 //e.g. <Role position="system.xlsx,role,1"> secondElm = firstElm.addElement(cellElm); secondElm.addAttribute("position", prePosition+","+rowNum); }else if (cellStr.startsWith("#begin")) {//第二种情况#begin_elem System.out.println("第二种情况#begin_elem"); //添加三级节点 //e.g. <elements id="default"> thirdElm = secondElm.addElement("elements"); final String []arrayStr = cellStr.split(":"); if(arrayStr.length == 1) { thirdElm.addAttribute("id", "default"); } else { thirdElm.addAttribute("id", arrayStr[1]); } isFieldIdLabel = true; } else if (isFieldIdLabel){//第三种情况字段名称roleId*,description存进fields集合 //System.out.println("cellIndex:"+cell.getColumnIndex()+"..."+cellStr); System.out.println("第三种情况字段名称:"+cellStr+",索引:"+cellIndex); if( !cellStr.isEmpty()){ if (coloumNum != 0) { fields.add(cellStr); coloumNum-=1; } }else{//如果为空 if (coloumNum != 0) { coloumNum-=1; } } if (coloumNum == 0) { System.out.println("fields集合长度:"+fields.size()); printList(fields); isFieldIdLabel = false; isFieldValue = true; } } else if (cellStr.startsWith("#end")) { System.out.println("这是结尾#end"); isFieldValue = false; fields.clear(); }else if (isFieldValue) {//循环读取每一行数据 if(isNextRow) { //添加四级节点 //e.g. <element position="system.xlsx,role,4"> fourthElm = thirdElm.addElement("element"); fourthElm.addAttribute("position",prePosition+","+rowNum); //添加五级节点 //e.g. <roleId>$DEFAULT_ROLE</roleId> 先添加第一行数据 final Element fifthElm = fourthElm.addElement(fields.get(cellIndex)); fifthElm.setText(cellStr); isNextRow = false; } else { //继续添加五级节点 //e.g. <description>Default Role</description> 第二行数据开始 if (cellIndex < fields.size()) { final Element fifthElm = fourthElm.addElement(fields.get(cellIndex)); fifthElm.setText(cellStr); } } } else { System.out.println("这是其他的情况,行数是:"+String.valueOf(row.getRowNum()+1)+",列数是:"+String.valueOf(cellIndex+1)); }//各种不同的情况end }//循环读取每一列的值end }//循环读取每一行的内容end }//循环读取每一个页sheet的内容end System.out.println("恭喜你,excel转化为xml文件已经完成!"); output.write(document); output.flush(); output.close(); } /** * 将单元格的内容全部转换成字符串 * @param cell * @return */ private static String cellValueToString(final Cell cell) { String str = ""; switch (cell.getCellType()) { case Cell.CELL_TYPE_STRING: str = cell.getRichStringCellValue().getString(); break; case Cell.CELL_TYPE_NUMERIC: if (DateUtil.isCellDateFormatted(cell)) { str = cell.getDateCellValue().toString(); }else { str = String.valueOf(cell.getNumericCellValue()); } break; case Cell.CELL_TYPE_BOOLEAN: str = String.valueOf(cell.getBooleanCellValue()); break; case Cell.CELL_TYPE_FORMULA: str = cell.getCellFormula(); break; default: str = cell.getRichStringCellValue().getString(); break; } return str; } /** * 打印list集合 * @param list */ public static void printList(final List<String> list){ for(int k = 0;k < list.size(); k++){ System.out.println(list.get(k)); } } public static void main(final String[] args) throws Exception{ // TODO Auto-generated method stub generateXml("excel/system.xlsx", "xml/system.xml"); } }
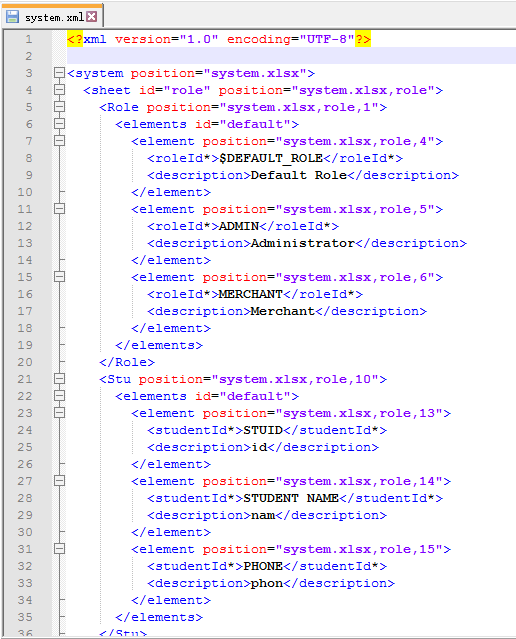
3、转换后xml文件数据
本文参考自博客![]() Damon huang : https://www.cnblogs.com/jrsmith/archive/2013/03/30/2991042.html,非常感谢。
Damon huang : https://www.cnblogs.com/jrsmith/archive/2013/03/30/2991042.html,非常感谢。