namenode元数据管理要点
1、什么是元数据?
hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>)
2、元数据由谁负责管理?
namenode
3、namenode把元数据记录在哪里?
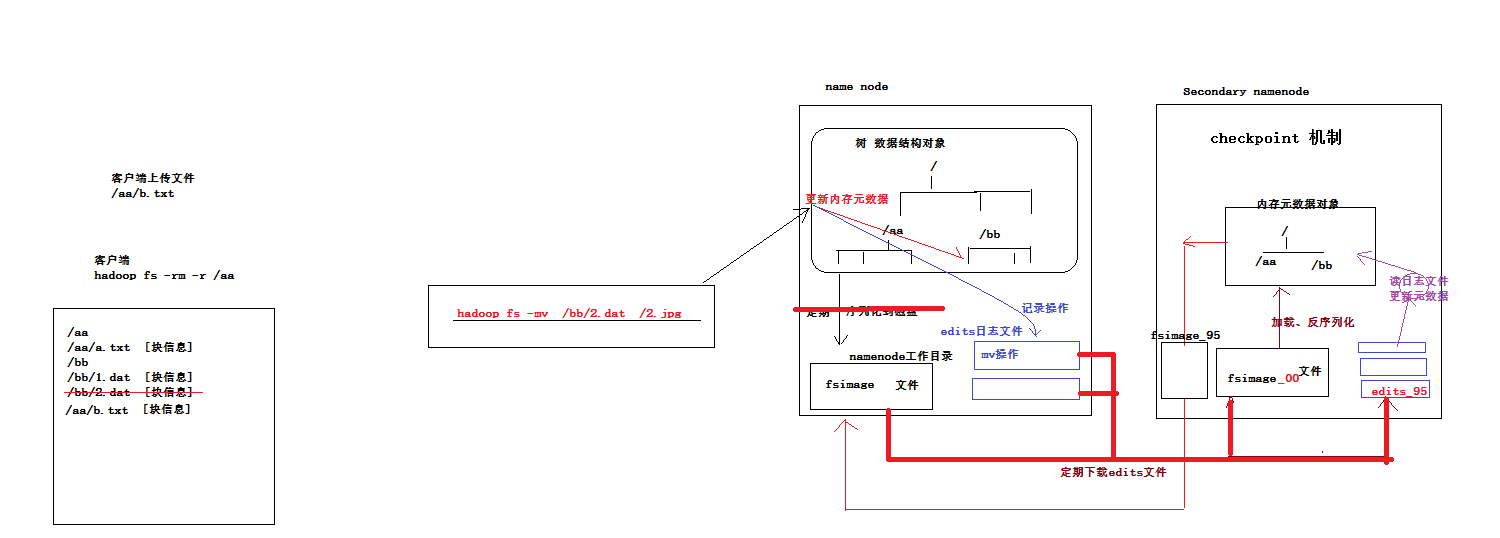
namenode的实时的完整的元数据存储在内存中;
namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件;
namenode会把引起元数据变化的客户端操作记录在edits日志文件中;
|
secondarynamenode会定期从namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合) 整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给namenode |
|
上述过程叫做:checkpoint操作 提示:secondary namenode每次做checkpoint操作时,都需要从namenode上下载上次的fsimage镜像文件吗? 第一次checkpoint需要下载,以后就不用下载了,因为自己的机器上就已经有了。 |
补充:secondary namenode启动位置的配置
|
默认值 |
<property> <name>dfs.namenode.secondary.http-address</name> <value>0.0.0.0:50090</value> </property> |
把默认值改成你想要的机器主机名即可
secondarynamenode保存元数据文件的目录配置:
|
默认值 |
<property> <name>dfs.namenode.checkpoint.dir</name> <value>file://${hadoop.tmp.dir}/dfs/namesecondary</value> </property> |
改成自己想要的路径即可:/root/dfs/namesecondary
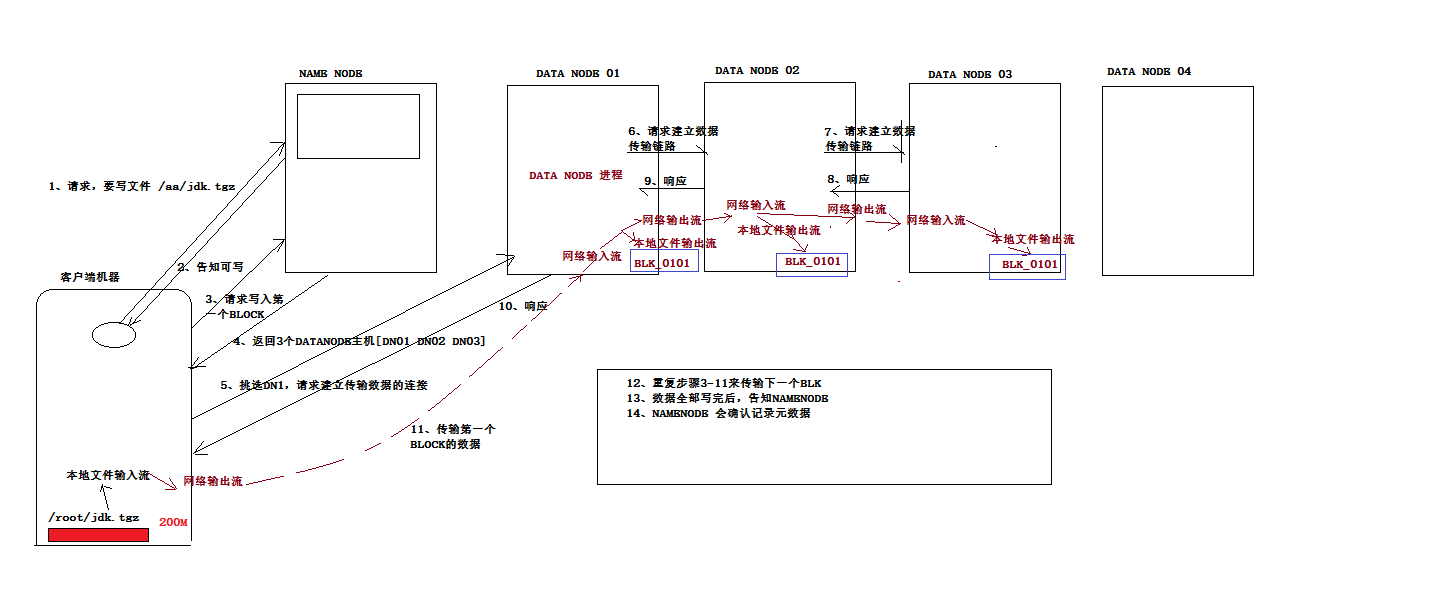
写数据流程
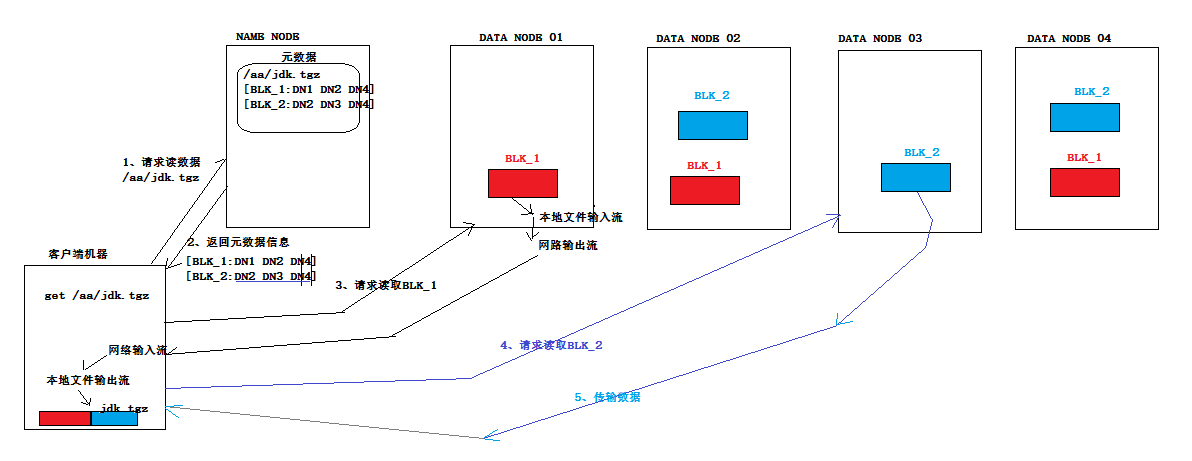
读数据流程