参考https://github.com/kiwenlau/hadoop-cluster-docker/blob/master/start-container.sh
因为之前在VMware上操作Hadoop时发现资源消耗大,配置麻烦,所以思考能不能使用docker搭建Hadoop集群,感谢上面链接的大神弄的集群镜像,所以很快就能搭建出Hadoop3节点集群。我使用的是windows下dockerTool安装启动vagrant、vitrualbox
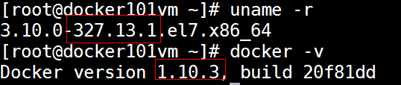
3节点Hadoop集群搭建步骤
1. 拉取镜像
docker pull index.alauda.cn/kiwenlau/hadoop-master:0.1.0


docker pull index.alauda.cn/kiwenlau/hadoop-slave:0.1.0


docker pull index.alauda.cn/kiwenlau/hadoop-base:0.1.0
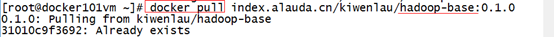

docker pull index.alauda.cn/kiwenlau/serf-dnsmasq:0.1.0
查看下载的镜像
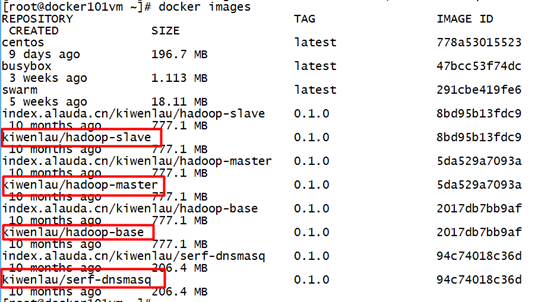
sudo docker images
hadoop-base镜像是基于serf-dnsmasq镜像的,hadoop-slave镜像和hadoop-master镜像都是基于hadoop-base镜像
所以其实4个镜像一共也就777.4MB:)
2. 修改镜像tag
docker tag 8bd95b13fdc9 kiwenlau/hadoop-slave:0.1.0 docker tag 5da529a7093a kiwenlau/hadoop-master:0.1.0
docker tag 2017db7bb9af kiwenlau/hadoop-base:0.1.0
docker tag 94c74018c36d kiwenlau/serf-dnsmasq:0.1.0


查看修改tag后镜像
docker images
3.下载源代码
git clone https://github.com/kiwenlau/hadoop-cluster-docker
(git clone http://git.oschina.net/kiwenlau/hadoop-cluster-docker)

4. 运行容器
cd hadoop-cluster-docker

./start-container.sh
一共开启了3个容器,1个master, 2个slave
开启容器后就进入了master容器root用户的家目录(/root)
查看master的root用户家目录的文件
ls

5.测试容器是否正常启动(此时已进入master容器)
查看hadoop集群成员
serf members
运行结果

若结果缺少节点,可以稍等片刻,再执行"serf members"命令。因为serf agent需要时间发现所有节点。
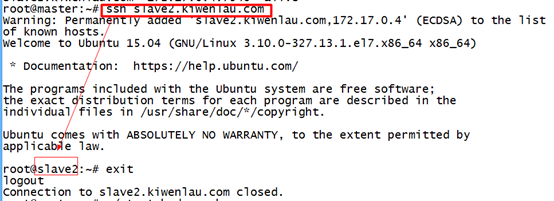
测试ssh
ssh slave2.kiwenlau.com
6. 开启hadoop
./start-hadoop.sh
 hadoop的启动速度取决于机器性能....vitrualbox太慢了
hadoop的启动速度取决于机器性能....vitrualbox太慢了


6.运行单词计数
.
./run-wordcount.sh

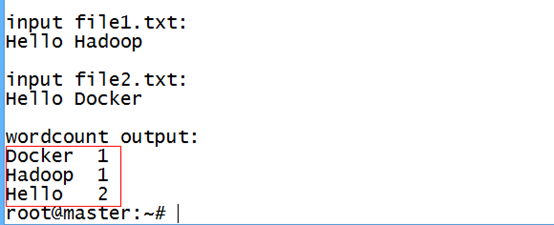
使用内存3G才跑得出来,集群的资源消耗很大