生成式对抗网络
背景
Ian Goodfellow 2014年 NIPS 首次提出GAN
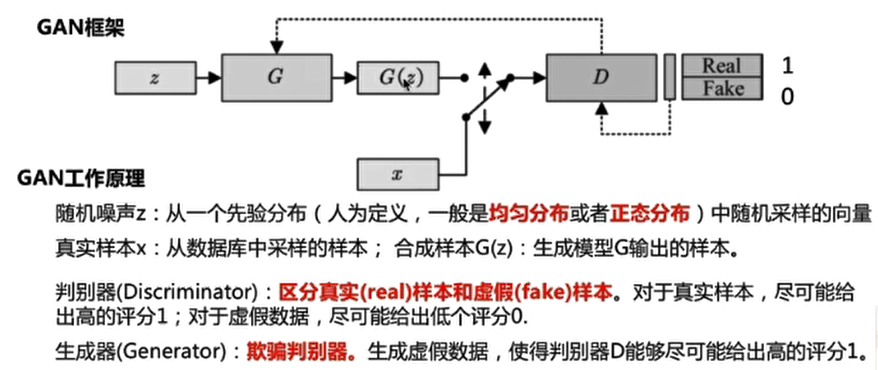
GAN
目的:训练一个生成模型,生成想要的数据。
为什么罪犯制造的假币越来越逼真?
为什么GAN可以生成数据?
GAN目标函数:

Tanh 把图片映射到[-1,1],可以让网络更快地收敛。
问题:随机种子是0-100维的数字还是向量
输入维数与图片大小的关系?
KL散度:衡量两个概率分布匹配程度的指标
具有不对称性,提出JS散度
JS散度:两种KL散度的组合,做了对称变换
具有非负性、对称性
极大似然估计 等价于 最小化生成数据分布和真实分布的KL散度。
当判别器D最优的时候,最小化生成器G的目标函数等价于最小化真实分布和生成分布的JS散度。
GAN到底在做一个什么事情?
最大化判别器损失,等价于计算合成数据分布和真实数据分布的JS散度
最小化生成器损失,等价于最小化JS散度(也就是优化生成模型)
cGAN
条件生成式对抗网络
改进判别器
DCGAN
深度卷积生成式对抗网络
原始GAN使用全连接网络作为判别器和生成器:
不利于建模图像信息,向量数据丢失了图像空间信息。
参数量大。
DCGAN使用卷积神经网络作为判别器和生成器:
通过大量的工程实践,经验性地提出一系列的网络结构和优化策略,来有效的建模图像数据。
通过pooling下采样,pooling是不可学习的,可能造成GAN训练困难。
判别器:使用滑动卷积(slide>1),使神经网络变得容易训练。
通过插值法上采样,插值方法固定不可学习,给训练造成困难。
生成器(从小的feature map生成大的feature map):滑动反卷积,3×3变为5×5后卷积,无像素位置补0。
批归一化:
加速神经网络收敛
减小神经网络参数对于初始化的依赖
激活函数:
sigmoid改为ReLU或LReLU
代码练习
# 定义生成器
net_G = nn.Sequential(
nn.Linear(z_dim,hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 2))
# 定义判别器
net_D = nn.Sequential(
nn.Linear(2,hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim,1),
nn.Sigmoid())
optimizer_G = torch.optim.Adam(net_G.parameters(),lr=0.001)
optimizer_D = torch.optim.Adam(net_D.parameters(),lr=0.001)
batch_size = 250
loss_D_epoch = []
loss_G_epoch = []
for e in range(nb_epochs):
np.random.shuffle(X)
real_samples = torch.from_numpy(X).type(torch.FloatTensor)
loss_G = 0
loss_D = 0
for t, real_batch in enumerate(real_samples.split(batch_size)):
z = torch.empty(batch_size,z_dim).normal_().to(device)
fake_batch = net_G(z)
D_scores_on_real = net_D(real_batch.to(device))
D_scores_on_fake = net_D(fake_batch)
loss = -torch.mean(torch.log(1-D_scores_on_fake) + torch.log(D_scores_on_real))
optimizer_D.zero_grad()
loss.backward()
optimizer_D.step()
loss_D += loss
z = torch.empty(batch_size,z_dim).normal_().to(device)
fake_batch = net_G(z)
D_scores_on_fake = net_D(fake_batch)
loss = -torch.mean(torch.log(D_scores_on_fake))
optimizer_G.zero_grad()
loss.backward()
optimizer_G.step()
loss_G += loss
if e % 50 ==0:
print(f'
Epoch {e} , D loss: {loss_D}, G loss: {loss_G}')
loss_D_epoch.append(loss_D)
loss_G_epoch.append(loss_G)
z = torch.empty(n_samples,z_dim).normal_().to(device)
fake_samples = net_G(z)
fake_data = fake_samples.cpu().data.numpy()
fig, ax = plt.subplots(1, 1, facecolor='#4B6EA9')
all_data = np.concatenate((X,fake_data),axis=0)
Y2 = np.concatenate((np.ones(n_samples),np.zeros(n_samples)))
plot_data(ax, all_data, Y2)
plt.show()

CGAN
class Discriminator(nn.Module):
'''全连接判别器,用于1x28x28的MNIST数据,输出是数据和类别'''
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28*28+10, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x, c):
x = x.view(x.size(0), -1)
validity = self.model(torch.cat([x, c], -1))
return validity
class Generator(nn.Module):
'''全连接生成器,用于1x28x28的MNIST数据,输入是噪声和类别'''
def __init__(self, z_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(z_dim+10, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(in_features=512, out_features=28*28),
nn.Tanh()
)
def forward(self, z, c):
x = self.model(torch.cat([z, c], dim=1))
x = x.view(-1, 1, 28, 28)
return x

DCGAN
class D_dcgan(nn.Module):
'''滑动卷积判别器'''
def __init__(self):
super(D_dcgan, self).__init__()
self.conv = nn.Sequential(
# 第一个滑动卷积层,不使用BN,LRelu激活函数
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
# 第二个滑动卷积层,包含BN,LRelu激活函数
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, inplace=True),
# 第三个滑动卷积层,包含BN,LRelu激活函数
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
# 第四个滑动卷积层,包含BN,LRelu激活函数
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True)
)
# 全连接层+Sigmoid激活函数
self.linear = nn.Sequential(nn.Linear(in_features=128, out_features=1), nn.Sigmoid())
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
validity = self.linear(x)
return validity
class G_dcgan(nn.Module):
'''反滑动卷积生成器'''
def __init__(self, z_dim):
super(G_dcgan, self).__init__()
self.z_dim = z_dim
# 第一层:把输入线性变换成256x4x4的矩阵,并在这个基础上做反卷机操作
self.linear = nn.Linear(self.z_dim, 4*4*256)
self.model = nn.Sequential(
# 第二层:bn+relu
nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# 第三层:bn+relu
nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# 第四层:不使用BN,使用tanh激活函数
nn.ConvTranspose2d(in_channels=64, out_channels=1, kernel_size=4, stride=2, padding=2),
nn.Tanh()
)
def forward(self, z):
# 把随机噪声经过线性变换,resize成256x4x4的大小
x = self.linear(z)
x = x.view([x.size(0), 256, 4, 4])
# 生成图片
x = self.model(x)
return x
