图灵机介绍
图灵机是什么
图灵机并不具体指代实体计算机,图灵机只是一种机器可以计算的理论模型,该理论严格从数学推理上证明了机器可以完成计算。即:图灵机是计算机的基础理论模型。
图灵机模型
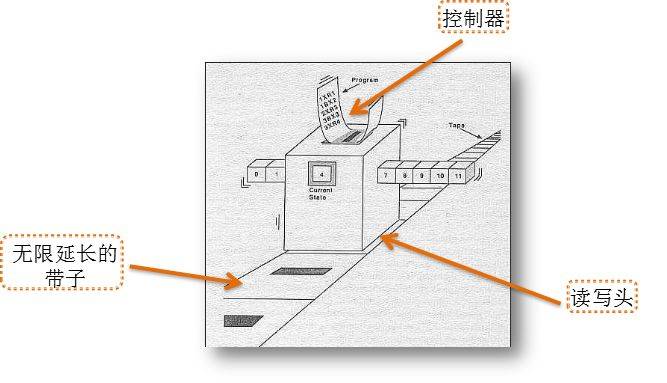
图灵机的构成如上图,一共有有四个组件构成,分别是
-
外部的记忆单元:无线延长的织带,表示可以存储任意长度的信息。
-
读写头:读取头可以从纸带上读取信息。写入头可以将数据写到纸带上,可以写入空,表示删除。
-
控制器:控制器包括两个部分,控制器自身的当前状态和程序指令。
读取头附着在控制器上,控制器可以在纸带上前后移动。控制器可以控制读取头执行具体的动作:读取头读取,写入头写入。
控制器受1.输入程序指令 2.自身状态 3.读取头返回的信息 三者的综合作用决定左右移动。
图灵机的计算理论
为了简单起见,假设所有的信息均为二进制。即纸带的信息格式为一个位置能存储一位二进制位的0或者1,或者什么都不存,为空。读取头也是每次读取和写入0或者1,或者擦除当前纸带位置的0或者1。
下面以小虫为例,进行图灵机计算理论的介绍。
假设理想的情况一
-
虫子所处的二维世界是一个无限长的纸带,这个纸带上被分成了若干小的方格,而每个方格都仅仅只有黑和白两种颜色。纸带的片段为:

-
假设虫子的感官只有眼睛,并且它的视力短的可怜,只能看到当前所处格子的颜色
-
虫子可以向前爬一个格子或向后爬一个格子
-
虫子的操作系统、程序为:我们假设黑色是食物区,虫子吃到食物后前移一格,白色是空白区,没有食物后退一格,
| 输入 | 输出 |
|---|---|
| 黑色 | 前移一格 |
| 白色 | 后移一格 |
在这个情况中格子的颜色是虫子的输入信息,集合为IN={黑色,白色},输出集合为 OUT= {前移一格,后移一格} 从开始位置开始,虫子会怎么移动呢?
-
开始是黑色,虫子前移一格,到达第2格
-
第2还是黑色,虫子前移一格,到达第3格
-
第3格还是黑色,虫子前移一格,到达第4格
-
第4格为白色,虫子后移一格,回到第3格
-
可见,这条带子上,虫子在第4格和第3格来回移动循环不止。
假设理想的情况二
现实中虫子肯定不可能傻到无线循环,虫子会有饥饿、吃饱的感受,食物吃了后也会消失。因此我们在情况下中改进下模型。
-
虫子在黑色的格子时,如果是饥饿状态,吃掉食物把格子变成白色;如果是吃饱状态,后移一格
-
虫子在白色的格子时,如果是饥饿状态,停下来等食物长出来涂黑;如果是吃饱状态,前移一格
-
虫子的操作系统、程序为:
| 输入 | 当前状态 | 输出 | 下一个状态 |
|---|---|---|---|
| 黑色 | 吃饱 | 后移一格 | 饥饿 |
| 黑色 | 饥饿 | 吃完食物格子变白(不移动) | 吃饱 |
| 白色 | 吃饱 | 前移一格 | 饥饿 |
| 白色 | 饥饿 | 等待食物长出来涂黑(不移动) | 吃饱 |
在这种情况中,输入集合为IN={黑色,白色},输出集合为 OUT= {前移一格,后移一格,吃掉食物涂白,等待食物长出来涂黑},内部状态S={吃饱,饥饿}
二维纸带不变,从开始位置开始,虫子初始是饥饿状态,虫子会怎么移动呢?
-
第1格是黑色,虫子饥饿,吃掉食物格子变白,虫子新状态为吃饱
-
第1格为白色,虫子吃饱,虫子前移一格,到达第2格,虫子新状态为饥饿
-
第2格为黑色,虫子饥饿,吃掉食物格子变白,虫子新状态为吃饱
-
第2格为白色,虫子吃饱,虫子前移一格,到达第3格,虫子新状态为饥饿
-
第3格为黑色,虫子饥饿,吃掉食物格子变白,虫子新状态为吃饱
-
第3格为白色,虫子吃饱,虫子前移一格,到达第4格,虫子新状态为饥饿
-
第4格为白色,虫子饥饿,等待食物长出来涂黑,虫子新状态为吃饱
-
第4格为黑色,虫子吃饱,虫子后退一格,到达第3格,虫子新状态为饥饿
-
这时,第3格已经长出来食物,是黑色,因此流程和第5步的情况一样了
情况二,小虫的行为比情况以复杂了一些,但小虫最后仍然会落入无限循环当中。
二维虫子是怎么移动的,本质上就是图灵机的工作原理!因为从本质上讲,最后的小虫模型就是一个图灵机!
图灵机的本质
其实虫子的所有决策和行为都可以抽象成一个图灵机模型。
为什么可以做这种抽象呢? 其实可以把二维虫子的模型进行更多扩展,以和现实世界基本或完全一致。因为二维虫子模型是以一切都简化的前提开始的,所以它的确是太太简单了。
然而,我们可以把二维虫子的输入集合、输出行动集合、内部状态集合进行扩大,这个模型就一下子实用多了。
-
二维虫子完全可以处于一个三维的空间中而不是简简单单的纸带。
-
二维虫子的视力很好,它一下子能读到方圆500米的信息。
-
二维虫子也可以拥有其他的感觉器官,比如嗅觉、听觉等等,而这些改变都仅仅是扩大了输入集合的维数和范围,并没有其他更本质的改变。
-
二维虫子可能的输出集合也是异常的丰富,它不仅仅能移动自己,还可以尽情的改造它所在的自然界。
-
进一步的,二维虫子的内部状态可能非常的多,而且控制它行为的程序可能异常复杂
那么二维虫子会有什么本事呢?这就很难说了,因为随着小虫内部的状态数的增加,随着它所处环境的复杂度的增加,我们正在逐渐失去对二维虫子行为的预测能力。
但是所有这些改变仍然没有逃出图灵机的模型: "输入集合、输出集合、内部状态、固定的程序指令!" 就是这四样东西抓住了二维虫子信息处理的根本。
以上虫子的例子来源于:
作者:jerry区块链技术与思维 链接:https://www.jianshu.com/p/c07d83c4f3a1 来源:简书
图灵机的计算实例
更多的相关内容可以查阅:可行性计算相关的内容。
图灵完备
可图灵指在可计算性理论中,编程语言或任意其他的逻辑系统如具有等用于通用图灵机的计算能力。换言之,此系统可与通用图灵机互相模拟。
即:能够抽象成图灵机的系统或编程语言就是图灵完备的;一切可计算的问题图灵机都能计算,因此满足这样要求的逻辑系统、装置或者编程语言就叫图灵完备的。
机器计算的实例-冯诺依曼体系结构
冯诺依曼体系是指一种具体的实体计算机的物理构成。冯诺依曼体系可以视为图灵机的一种实例。
神经网络图灵机
神经网络图灵机就是基于神经网络实现的图灵机。
即:基于神经网络实现了控制器,记忆体,读写头,并且能完成计算的系统。
现在的神经网络是建立在特定的物理实体机上的,如基于改进型冯诺依曼的x86-64架构的计算机。
所以狭义上神经网络图灵机是:
基于x86-64架构,并且使用神经网络实现了控制器,记忆体,读写头,并且能完成计算的系统。
Neural Turing Machines
下载:论文
NTM的操作和组件
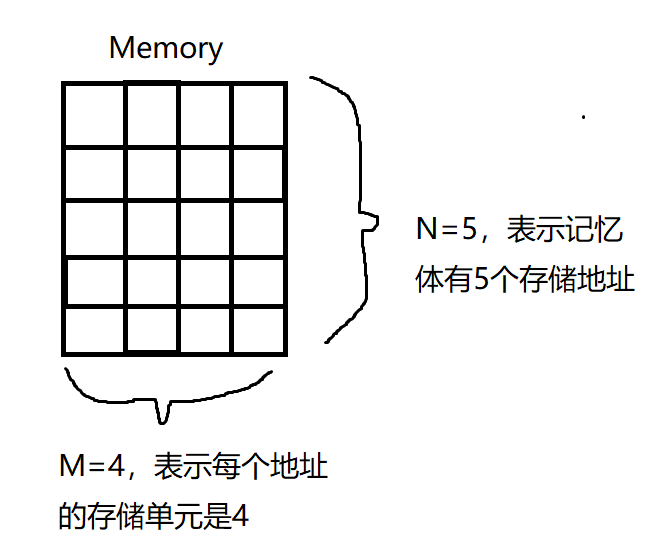
内存:记忆矩阵 M: (N,M),N行M列的二维矩阵
记忆矩阵Memory的N表示记忆体的地址范围,也叫做memory_size。
记忆矩阵Memory的M表示每个地址对应的存储容量,也叫做memory_vector_dim。
例如:
权重向量 wt: (N,), N行一列的一个列向量
权重向量Wt的是一个长度等于记忆矩阵的地址个数N的列向量。
即: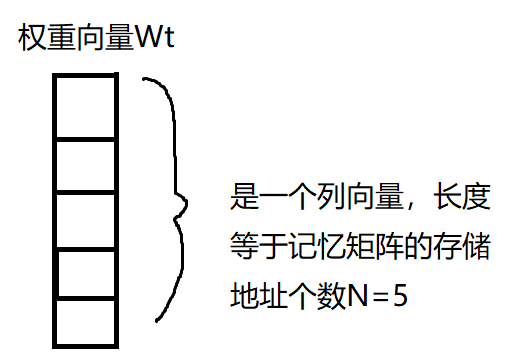
其每一个元素对应记忆矩阵的一个存储地址,例如:
wt(i)对应于记忆体的第i个存储地址的存储向量:M(i),亦即M[i, :]。
wt(i)要满足各元素的和等于1,且任意元素取值在[0,1]。即其元素对应的是概率。
所以权重向量的作用是定位记忆单元的存储地址。并且能够区分指定地址内数据的种要程度。
读操作&读向量 rt: (M,), 一行M列的行向量
读取操作对应的读取权重向量
rt表示t时刻read head从记忆体读取出来的内容。
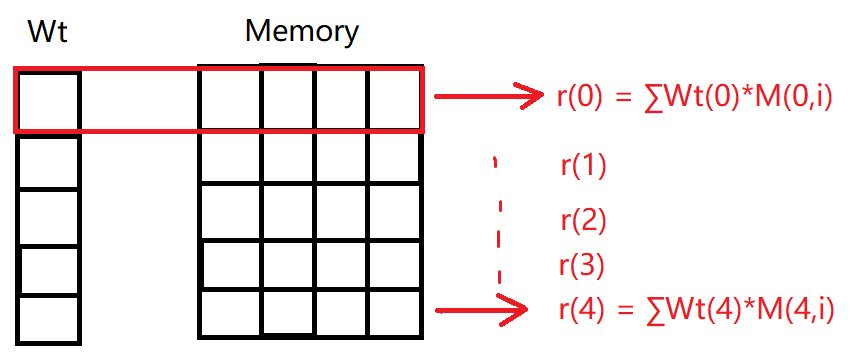
写操作&擦除权重向量et: (M,), 一行M列的行向量
erase 擦除
引入了一个擦除向量: et ,是M个元素的行向量。所有元素的分量都在0,1之间,表示地址内各个位置数据擦除的比重。
Mt(i) = Mt-1(i) ⊙ (1-wt(i)·et)
例如:

add 添加
记忆矩阵擦除之后得到的新记忆矩阵需要再附加上当前要往记忆中写入的数据。
写入操作也引入了一写入向量: at ,也是一个M元素的行向量。
所以writing可以对任意地址的元素值进行任意精度的修改。
controller 对 权重向量wt和其它参数的计算
controller根据当前的输入结合其自身的当前状态进行计算,得到权重向量wt的中间状态。
controller是一个LSTM或RNN神经网络。
例如:
-
构造输入当前输入是长度为9的一个序列x,上一个时刻的读取向量内容为长度为M=5的prev_read_vertor。将x和prev_read_vector拼接成一个9+5=14的一个序列X。
-
调用
controller_output, controller_state=controller.cell(X,prev_controller_state),进行计算,即可得到全部的所需参数:读取头、擦除和添加的头和引入的相关参数。
NTM的寻址策略
基于内容的寻址Content-base
例如当前时刻要查询的值为向量长度为M的kt,将其与记忆单元**Mt中所有N个地址的向量进行比较,最相近的那个Mt(i)即为待查询的值。
首先,需要进行寻址操作的Head(Read or Write)生成一个长度为M的key vector:kt,然后将kt与每个Mt(i)进行相似度比较(相似度计算函数为K[u,v]),最后将生成一个归一化的权重向量wtc,计算公式如下:
其中,βt满足βt>0是一个调节因子,用以调节寻址焦点的范围。βt越大,函数的曲线变得越发陡峭,焦点的范围也就越小。
似度函数这里取余弦相似度:
基于位置的寻址Location-base
直接使用内存地址进行寻址,跟传统的计算机系统类似,controller给出要访问的内存地址,Head直接定位到该地址所对应的内存位置。对于一些对内容不敏感的操作,比如乘法函数f(x,y)=x y,显然该操作并不局限于x,y的具体值,x,y的值是易变的,重要的是能够从指定的地址中把它们读出来。这类问题更适合采用Location-base的寻址方式。 基于地址的寻址方式可以同时提升简单顺序访问和随机地址访问的效率。我们通过对移位权值进行旋转操作来实现优化。例如,当前权值聚焦在一个位置,旋转操作1将把焦点移向下一个位置,而一个负的旋转操作将会把焦点移向上一个位置。 在旋转操作之前,将进行一个插入修改的操作(interpolation),每个head将会输出一个修改因子gt且gt∈[0,1],该值用来混合上一个时刻的wt-1和当前时刻由内容寻址模块产生的wtc,最后产生门限权值wtg:
显然,gt的大小决定了wtg所占的分量,gt越大,系统就越倾向于使用Content-base Addressing。当gt=1时,将完全按照Content-base方式进行寻址。 interpolation操作结束后,每个head将会产生一个长度为N的移位权值向量st,st是定义在所有可能的整形移位上的一个归一化分布。例如,假设移位的范围在-1到1之间(即最多可以前后移动一个位置),则移位值将有3种可能:-1,0,1,对应这3个值,st也将有3个权值。那该怎么求出这些权值呢?比较常见的做法是,把这个问题看做一个多分类问题,在Controller中使用一个softmax层来产生对应位移的权重值。
st生成之后,接下来就要使用st对wtg进行循环卷积操作,具体如下式:
由于卷积操作会使权值的分布趋于均匀化,这将导致本来集中于单个位置的焦点出现发散现象。为了解决这个问题,还需要对结果进行锐化操作。具体做法是Head产生一个因子γt≥1,并通过如下操作来进行锐化:
例如:

经过锐化处理后wt不同元素直接的差异变得更明显了(即变得“尖锐”了),内存操作焦点将更加突出。
整个寻址过程:
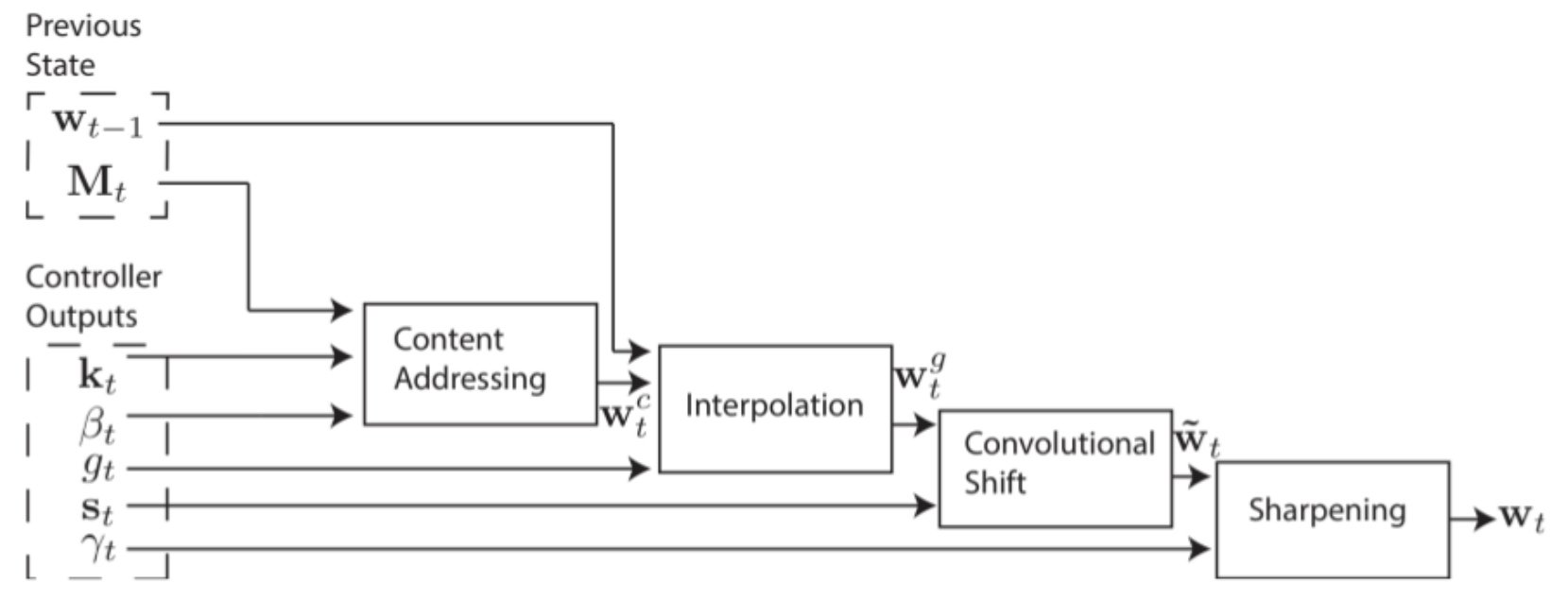
通过上图的内存寻址系统,我们能够实现三种方式的内存访问: 1.直接通过内容寻址,即前边提到的Content-base方式; 2.通过对Content-base产生的权值进行选择和移位而产生新的寻址权值,在这种模式下,运行内存操作焦点跳跃到基于Content-base的下一个位置,这将使操作Head能够读取位于一系列相邻的内存块中的数据; 3.仅仅通过上一时刻的权值来生成新的操作地址权值,而不依赖任何当前的Content-base值。这将允许Head进行顺序迭代读取(比如可以通过多个时刻的连续迭代,读取内存中一个连续的数组)
参考链接:https://blog.csdn.net/rtygbwwwerr/article/details/50548311