-
论文笔记《Decoupled Dynamic Filter Networks》
Decoupled Dynamic Filter Networks
Introduction
- 卷积缺点在于:内容不变,计算量高
- 动态filter可以根据内容自适应,但是会提高计算量。depth-wise卷积很轻量,但是会降低准确度
- 提出的DDF可以处理这两个缺点,受attention影响,将depth-wise的动态卷积核解耦成空间和channel上的动态filter
Method
- 其实目标很明确,就是要设计一个动态卷积的操作,要做到content-adaptive并且比标准卷积轻量,其核心在于将动态的卷积核分成spatial和channel两个维度上
- 高级的attention,但他并没有在feature map上再乘以某个attention,而是把attention乘在filter上,再像普通卷积一样乘在spatial上面,还挺有意思的,具体的操作可以如下所示,就是将3x3卷积替换成为下图中的计算方法
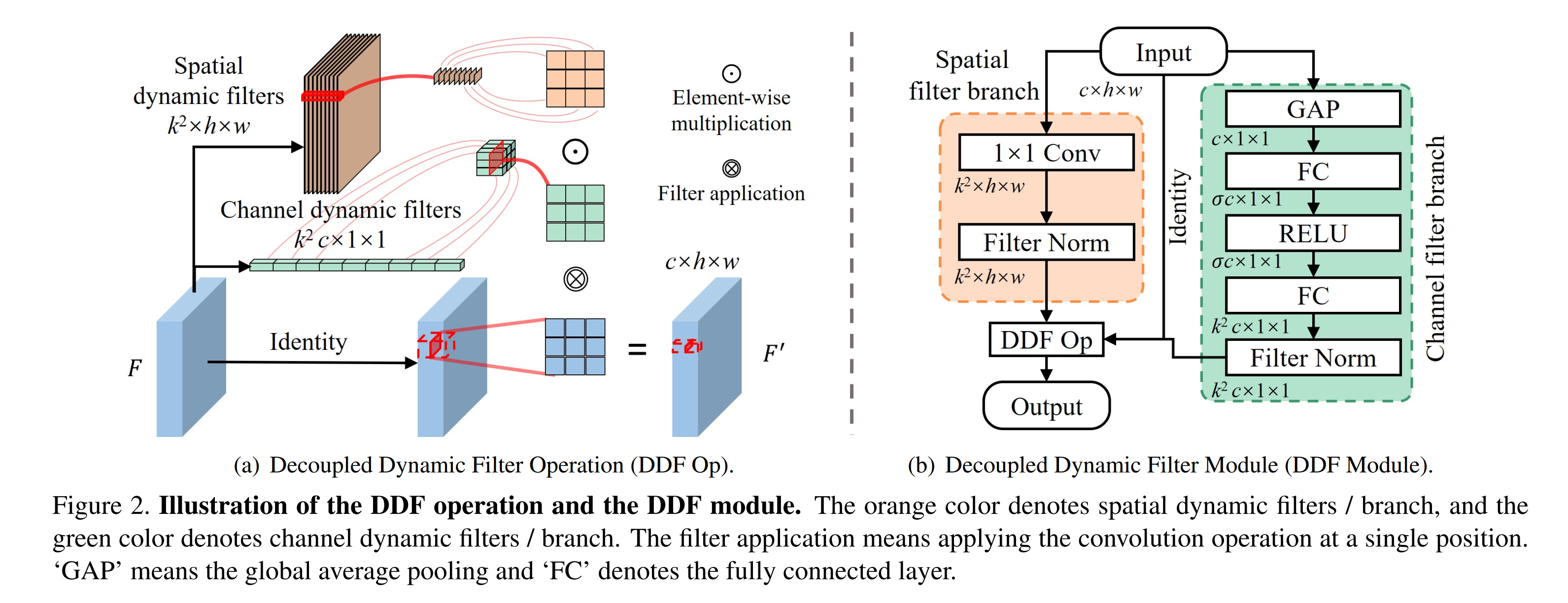
- 这个图介绍的还是非常清楚的,可以对两个分支做一个具体的介绍。在特征图上使用动态卷积核相当于在展开的特征上使用attention,所以我们将feature map展开来计算动态卷积核。
- 在spatial维度上,首先通过1x1的卷积将channel数变成(k^2),每个pixel所对应的(k^2)维向量就是我们所想要(k imes k)卷积的一部分值。
- 在channel维度上,通过GAP直接变成一维向量,通过一个SE block的squeeze过程,在实验中实际的squeeze ratio 设为0.2,也就是图中的(sigma),最后将tensor的channel数变成(k^2 imes c)个,相当于是不同channel的一个attention值。
- 对于上述两个过程计算的结果,通过BN进行归一化后,将两部分结果按位相乘,这样就可以对原来的特征图每一个pixel每一个channel都有一个通过attention后的卷积核,达到动态的效果,相当于每一步的卷积核都是通过feature map决定的,极大的减少了卷积核的参数
- 可以说对于原始的动态卷积来说,就是对不同的像素点采用不同的卷积核处理,所需要的filter参数量为(c^{'} imes c imes k imes k imes h imes w),现在的这个方法对此进行解耦后,将其简化为channel维度上的(c imes k imes k)和spatial维度上的(k imes k imes h imes w),减少了相当多的参数
- 这个DDF模块可以替换ResNet block中的3x3卷积
Result
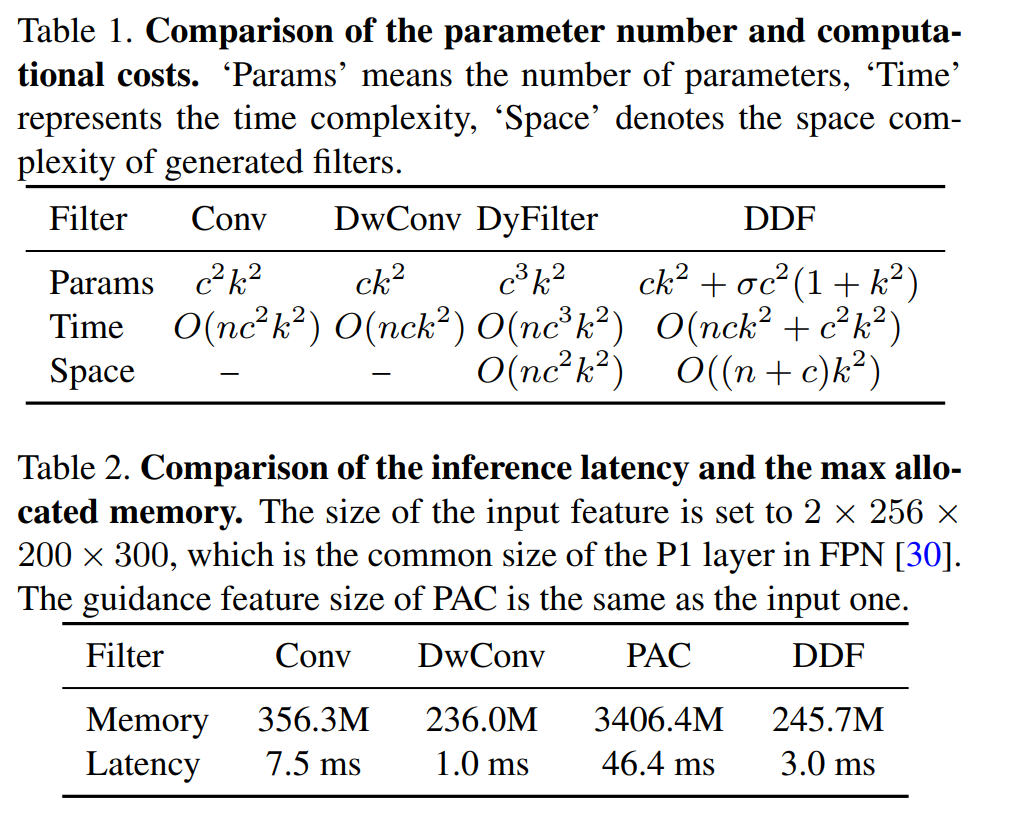
- 从数据上来,看其参数量比普通卷积小,时间复杂度上和Depth-wise Conv类似
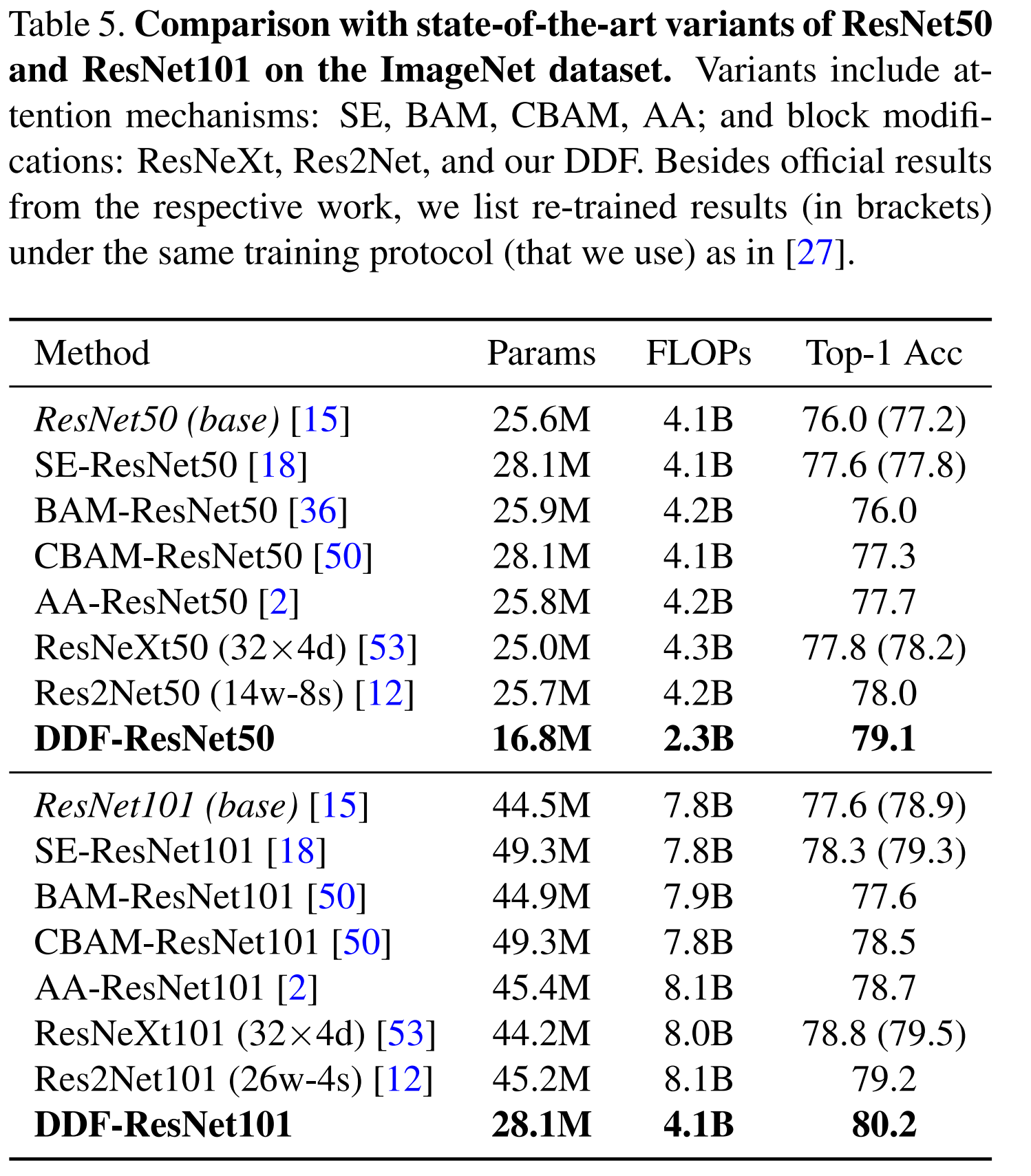
- 在分类任务上的结果也很好,和普通ResNet比参数量和计算量都减少了很多
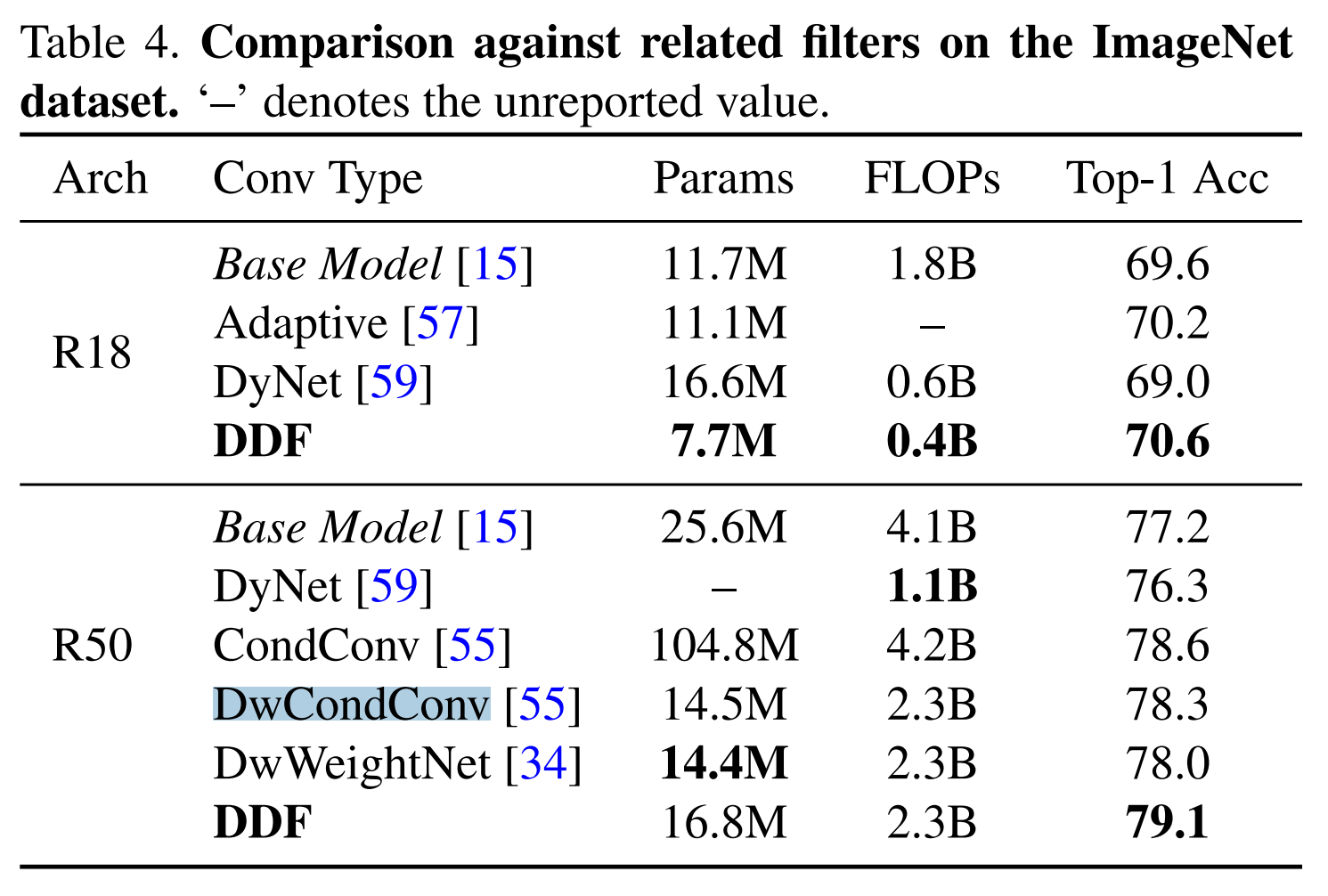
- 和相关工作Dynamic Filter等的相比,可以看出DwCondConv也是很nb的
Conclusion
- 提出了一种新的动态卷积方法,结构也很好懂,可以通过feature直接计算出卷积核还是挺不错的想法,还用在了上采样中,一些FPN等说不定也可以用。之前看过的一些CondConv,DyConv好像都不是这样的,这个计算方法也是建立在attention基础之上的吧,真的到处都是attention。相比于传统的ResNet还是节省了不少计算量的,参数量和计算方面都不错。值得一提的是,这是我看过的很少数的只需要一张图就可以完全理解这个内容怎么实现的文章,感谢作者的工作带来的启发。
-
相关阅读:
POJ 3694 Network (求桥,边双连通分支缩点,lca)
UVA 796
UVA 315 315
POJ 1236 Network of Schools (有向图的强连通分量)
【转】有向图强连通分量的Tarjan算法
HDU 3072 Intelligence System (强连通分量)
【转】强大的vim配置文件,让编程更随意
WORDPRESS登录后台半天都无法访问或者是访问慢的解决方法
phpstorm+Xdebug断点调试PHP
PHP性能调优---PHP调试工具Xdebug安装配置教程
-
原文地址:https://www.cnblogs.com/liuyangcode/p/14755924.html
Copyright © 2020-2023
润新知