
1.成百上千台服务器组成集群,需要时刻检测服务器是否故障
2.用流读取数据更加高效快速
3.存储节点具有运算功能,省略了服务器之间来回传数据的网络带宽限制
4.一次写入,多次访问,不修改数据
5.多平台
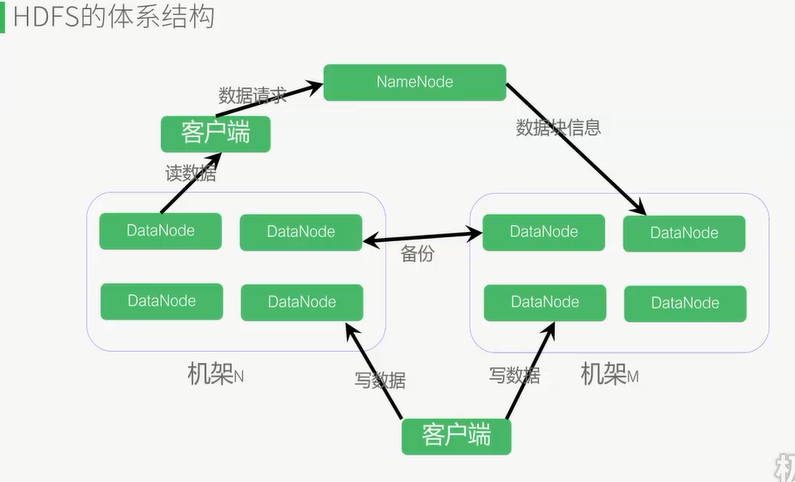
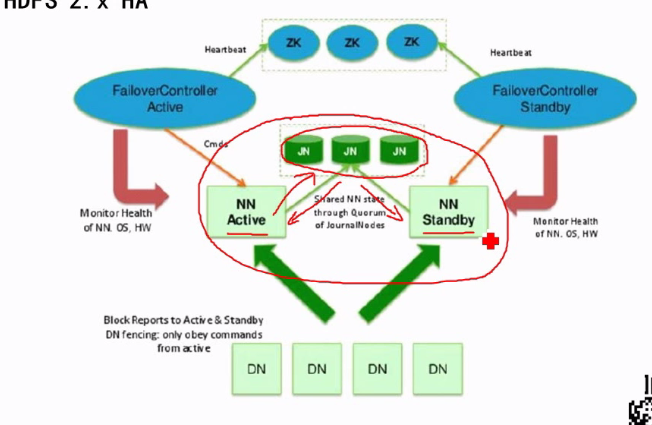
namenode:master,负责总体调度,处理协调请求等(一个集群只能有一个namenode,但是可以多个集群组成一个更大的集群
,这时就有多个namenode,这时的namenode有两种状态,一种叫active并且一个大集群只能有一个namenode处于该状态,
一种为standby)
namenode两大功能:接受客户端读写服务,存放元数据(DataNode存储的位置等基本信息,fsimage和edits文件)
fsimage是namenode格式化时产生的,edits是用户操作增删改查的时候生成的日志
datanode:slave,存储节点,会备份,一般本地2分,其他服务器一份
机架:多个DataNod节点组成,master通过机架感知技术得知所需数据的位置
数据块:存储单元,一般64M(hadoop2中是128M)
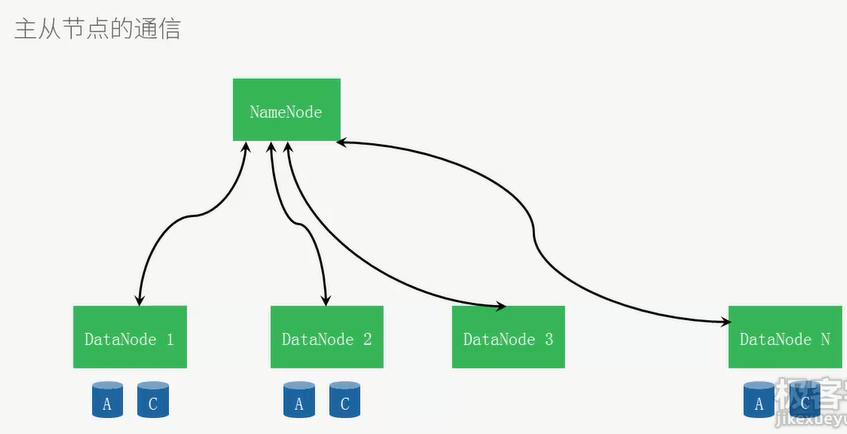
时刻保持心跳通讯,保证每个数据都备份于3个节点上
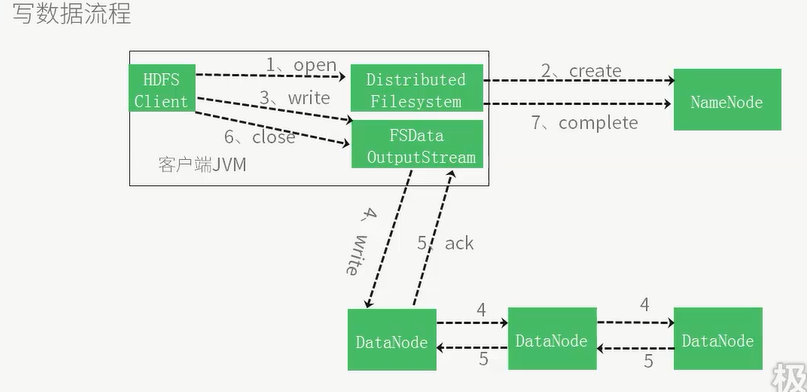
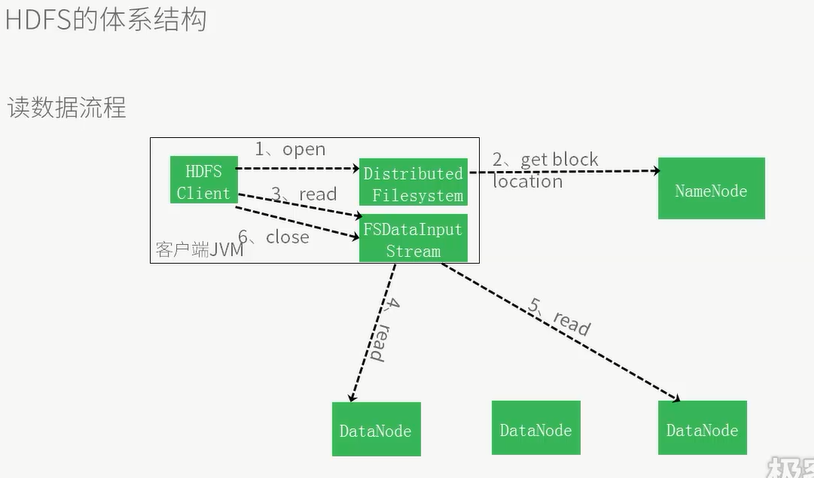
5的read为第一个数据块读完后,读下一个数据块,如果在读取过程中某一个数据块出问题,则会记录下来并且找其他的备份,并且以后不再读取错误数据块
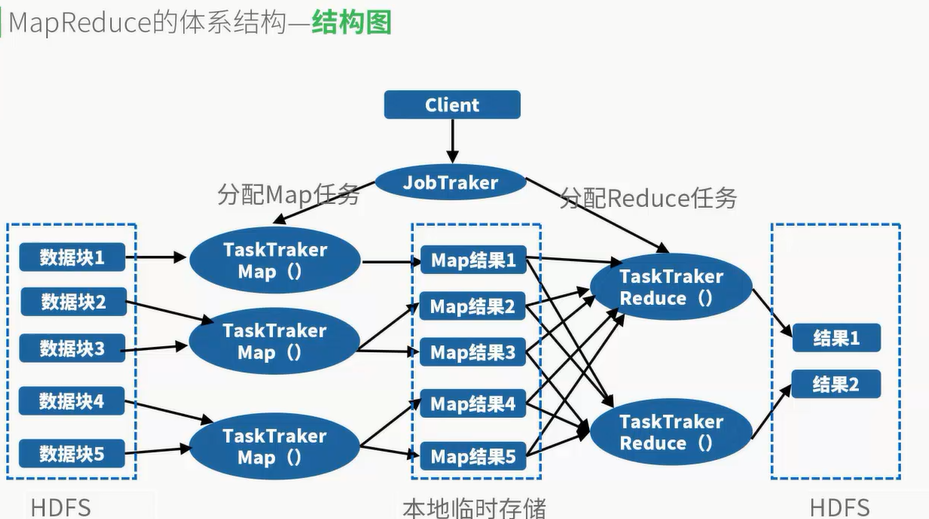
map负责分批运算,如果要统计1TB数据中my的出线次数,则可以启用100个map,每个map统计0.01TB数据,最终由reduce汇总

作业(Job):运行一个MapReduce所需要用到的所有jar组件
任务(Task):mapTask和ReduceTask
Key相同的结果进行reduce统计合并

作业提交一般提交jar包和配置文件
调度一般来说默认采取FIFO调度,即先考虑优先级,然后先进先出

TaskTracker会不断想JobTracker传达任务信息,如果空闲会主动申请作业




一般的生产环境都是完全分布式模式。