本文目的:输入单词给出翻译;得到翻译结果源代码。
本文使用firefox浏览器,参考众多博客总结步骤如下:
①打开https://fanyi.baidu.com/?aldtype=16047#auto/zh,这是最开始从百度搜索里进去的百度翻译的网址,首先空白处右键选择【查看元素】,【网络】,刷新,【XHR】:

xhr:XMLHttpRequest在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下,对网页某部分的内容进行更新。更新部分一般情况为json格式
②在页面处随意输入一个单词,查看页面元素里【XHR】的变化:
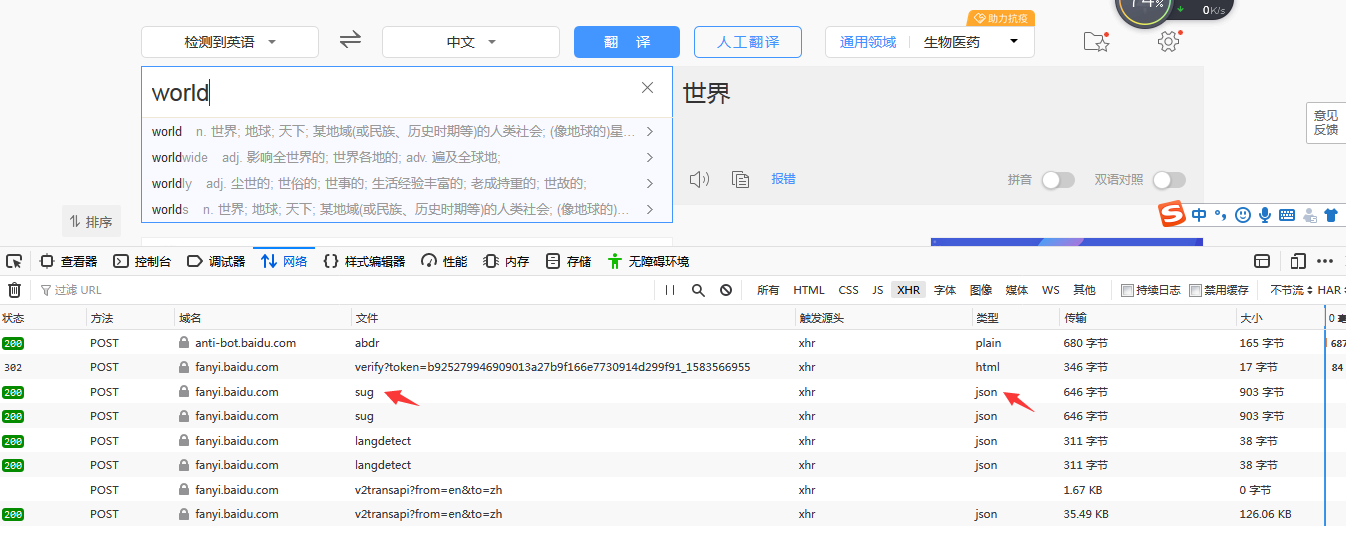
可以看见,增多了一些名为sug的文件,其类型是json,方法为post。
③双击打开任意一个sug,查看其中的数据信息:
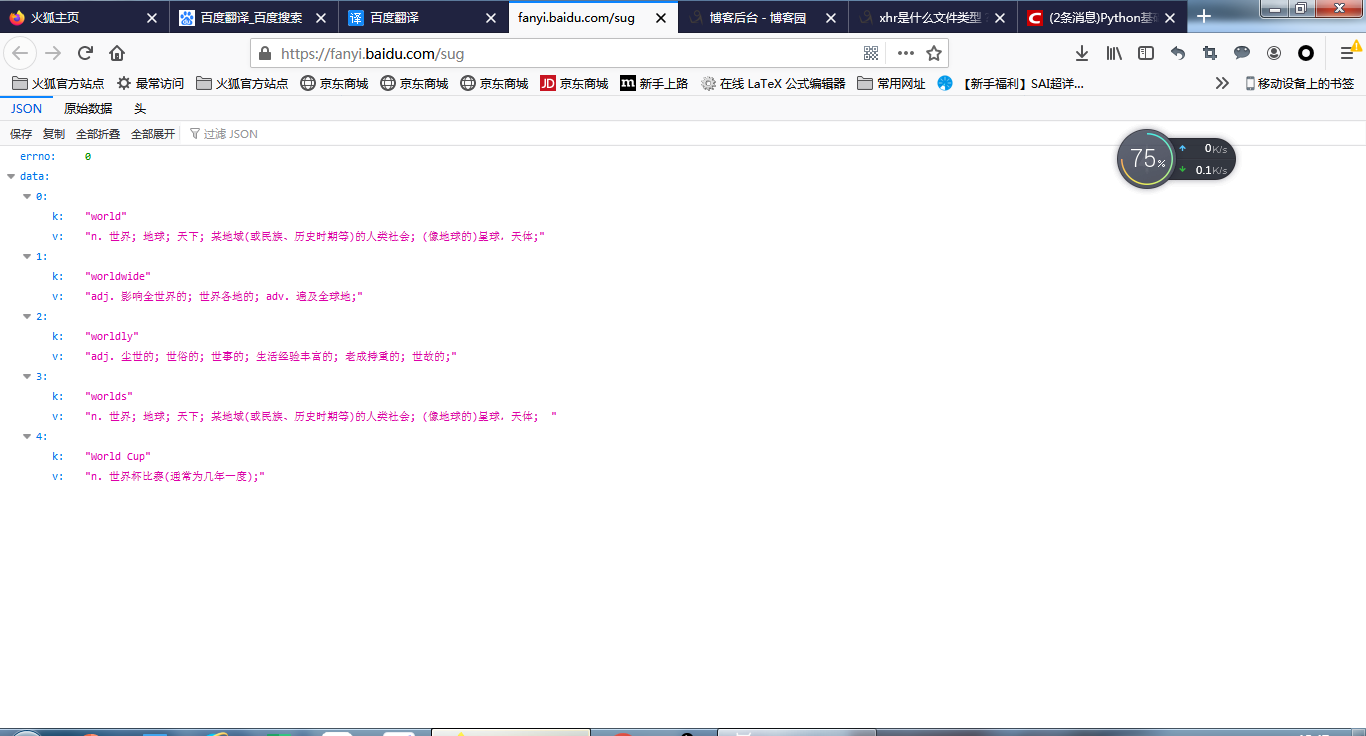
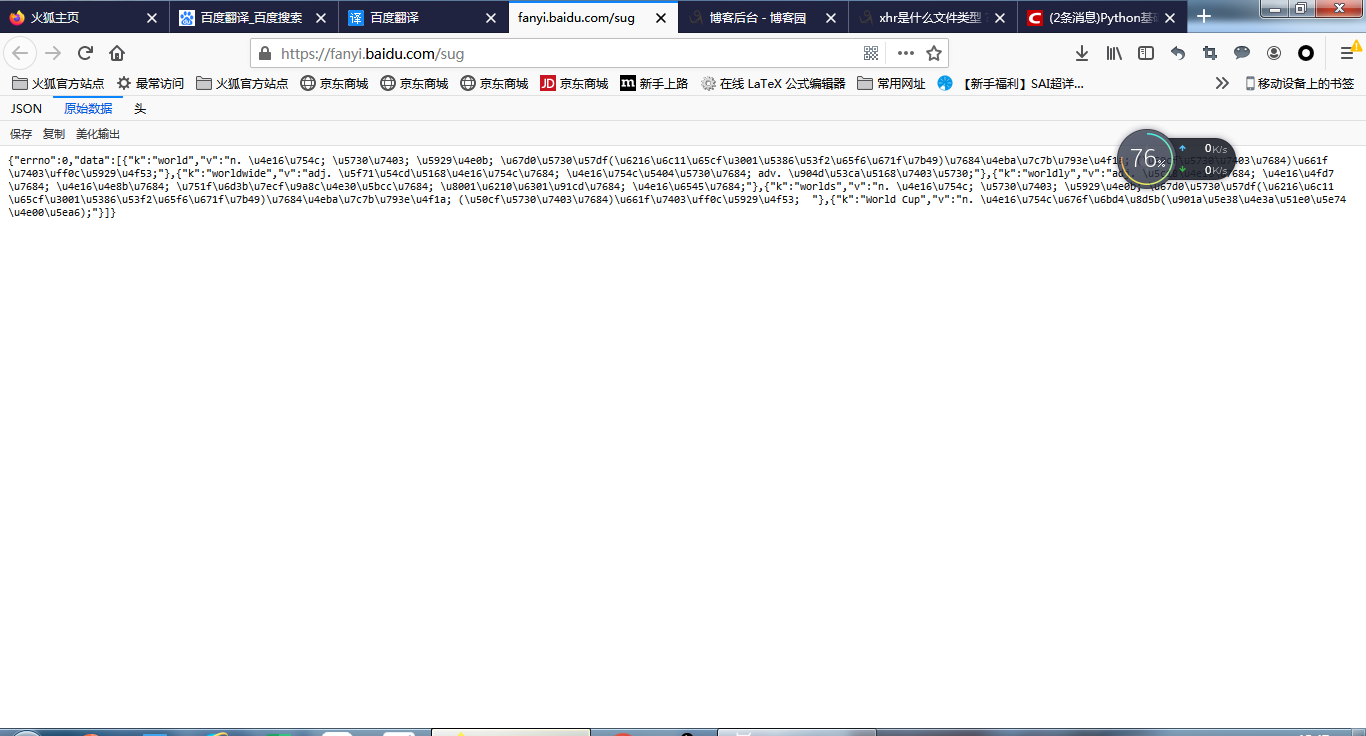
可以看见,sug文件中的数据信息是翻译结果,它是以utf编码存储的,而且是一个字典{"errno":0,"data":[{}]}的形式,最里面的字典就是我们得到的翻译结果,翻译结果的第一组kv就是我们需要的,其余为联想翻译结果。所以我们要做的事情就是,先把这个字典取出来,再["data"][0]["v"]就能够准确搜到我们需要的翻译结果。
④代码部分:
import requests import json url = "https://fanyi.baidu.com/sug" # 定义请求的参数 data = {'kw': 'world'} # 创建请求, 发送请求, 爬取信息 res = requests.post(url, data=data) # 解析结果 str_json = res.content.decode("utf-8") myjson = json.loads(str_json) print(myjson) print(myjson['data'][0]['v'])
代码结果为: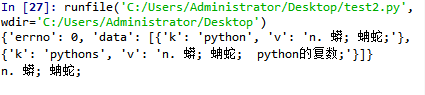
如果说想要实现在线翻译,修改如下:
import requests import json url = "https://fanyi.baidu.com/sug" # 定义请求的参数 word=input("give a word:") data = {'kw': word} # 创建请求, 发送请求, 爬取信息 res = requests.post(url, data=data) # 解析结果 str_json = res.content.decode("utf-8") myjson = json.loads(str_json) print(myjson) print(myjson['data'][0]['v'])
代码结果为: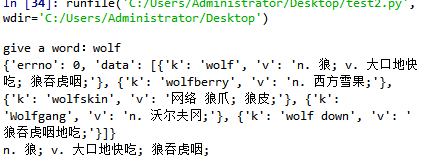
好,以上工作告一段落。上述可以实现单词的翻译
import requests import json url_post = "https://fanyi.baidu.com/sug" headers={ "user_agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0" } data={ "kw": "dog" } try: response=requests.post(url=url_post,data=data,headers=headers) if response.content: str_json=response.content.decode("utf-8") dic_obj = json.loads(str_json) fp = open("C:/Users/Administrator/Desktop/dog.json","w",encoding="utf-8") json.dump(dic_obj,fp=fp,ensure_ascii=False) except ConnectionError: print('error')