转自:https://www.cnblogs.com/wxgblogs/p/5616829.html
RED不是等到已经发生拥塞后才把所有队列尾部的分组全部丢弃,而是在检测到网络拥塞的早期征兆时(即路由器的平均队列长度超过一定门限值时),以概率p随机丢弃分组,让拥塞控制只在个别的TCP连接上执行,因而避免全局性的拥塞控制。
RED的关键就是选择三个参数最小门限、最大门限、丢弃概率和计算平均队列长度。最小门线必须足够大,以保证路由器的输出链路有较高的利用率。而最大门限和最小门限只差也应该足够大,是的在一个TCP往返时间RTT中队列的正常增长仍在最大门限之内。经验证明:使最大门限等于最小门限的二倍是合适的。
TCP的流量控制

TCP报文段发送时机的选择
TCP的拥塞控制
慢开始和拥塞避免
发送方维持一个叫做拥塞窗口cwnd(congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞窗口,另外考虑到接受方的接收能力,发送窗口可能小于拥塞窗口。发送方控制拥塞窗口的原则是:只要网络没有出现拥塞,拥塞窗口就增大一些,以便把更多的分组发送出去。但是只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络的分组数。
慢开始算法的思路就是:最初的TCP在连接建立成功后会向网络中发送大量的数据包,这样很容易导致网络中路由器缓存空间耗尽,从而发生拥塞。因此新建立的连接不能够一开始就大量发送数据包,而只能根据网络情况逐步增加每次发送的数据量,以避免上述现象的发生。具体来说,当新建连接时,cwnd初始化为1个最大报文段(MSS)大小,发送端开始按照拥塞窗口大小发送数据,每当有一个报文段被确认,cwnd就增加至多1个MSS大小。用这样的方法来逐步增大拥塞窗口CWND。
这里用报文段的个数的拥塞窗口大小举例说明慢开始算法,实时拥塞窗口大小是以字节为单位的。如下图:
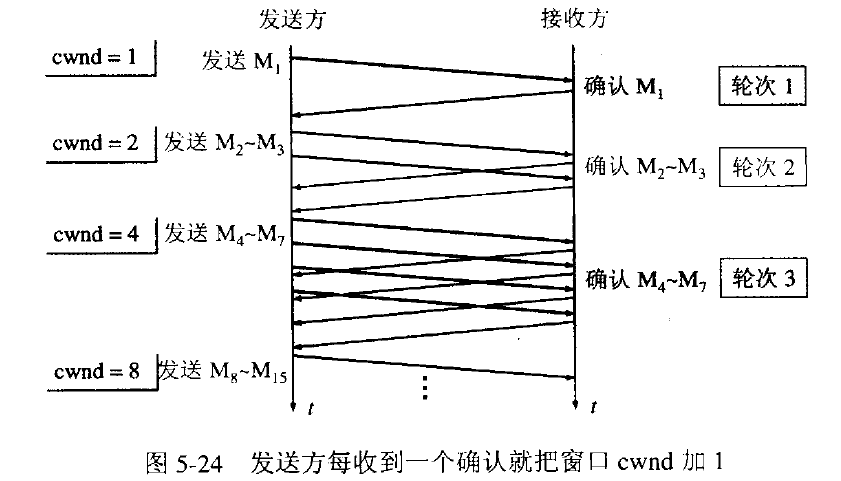
为了防止cwnd增长过大引起网络拥塞,还需设置一个慢开始门限ssthresh状态变量。ssthresh的用法如下:
当cwnd<ssthresh时,使用慢开始算法。
当cwnd>ssthresh时,改用拥塞避免算法。
当cwnd=ssthresh时,慢开始与拥塞避免算法任意。
拥塞避免算法思路:让拥塞窗口缓慢增长,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口按线性规律缓慢增长。
无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为无法判定,所以都当做拥塞来处理),就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为1,执行慢开始算法。这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
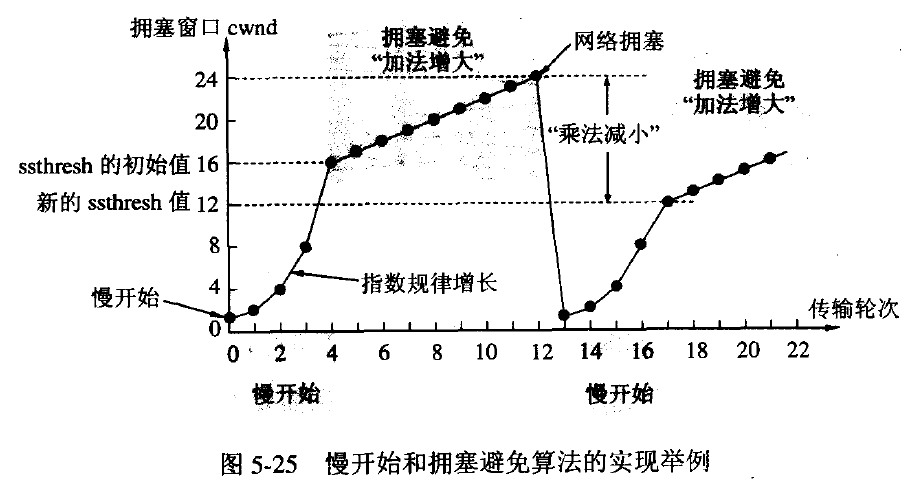
乘法减小和加法增大
乘法减小:是指不论在慢开始阶段还是拥塞避免阶段,只要出现超时,就把慢开始门限减半,即设置为当前的拥塞窗口的一半(于此同时,执行慢开始算法)。当网络出现频繁拥塞时,ssthresh值就下降的很快,以大大将小注入到网络中的分组数。
加法增大:是指执行拥塞避免算法后是拥塞窗口缓慢增大,以防止网络过早出现拥塞。
快重传和快恢复
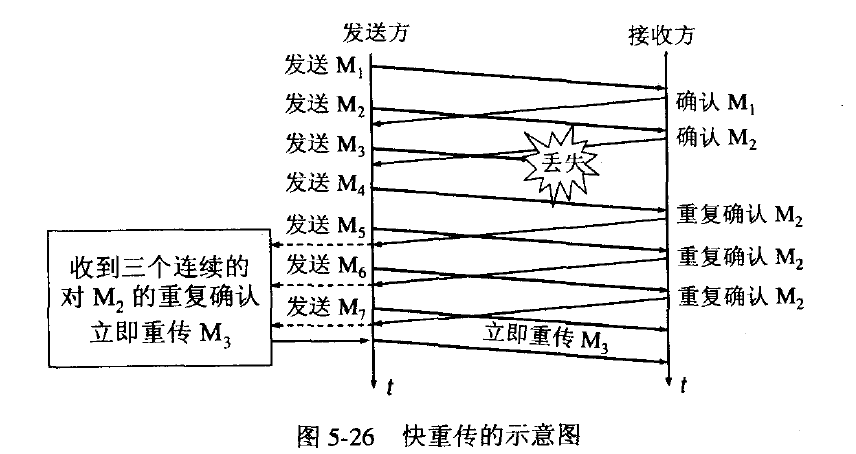
快重传配合使用的还有快恢复算法,有以下两个要点:
①当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半。但是接下去并不执行慢开始算法。
②考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh减半后的大小,然后执行拥塞避免算法。如下图:
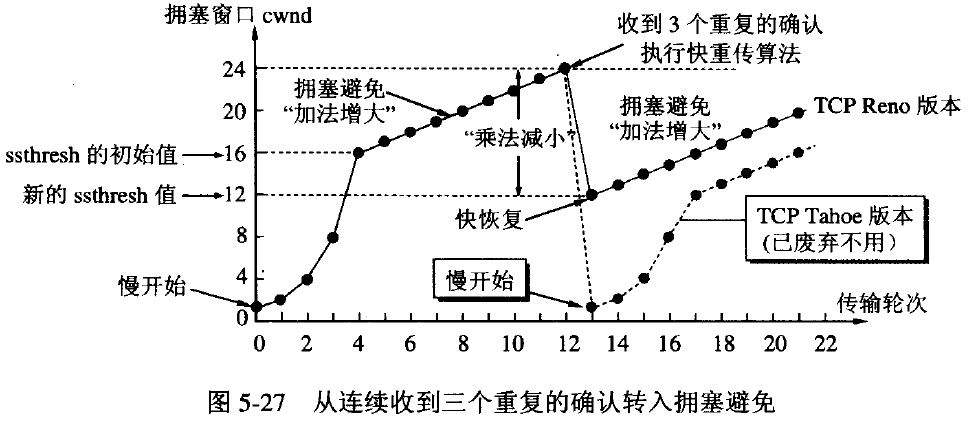
在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时时才使用。
接受窗口又称为通知窗口。因此从接收方对发送方的流量控制角度考虑,发送方的发送窗口一定不能超过对方给出的接受窗口的RWND。
也就是说:发送窗口的上限=Min[rwnd,cwnd].
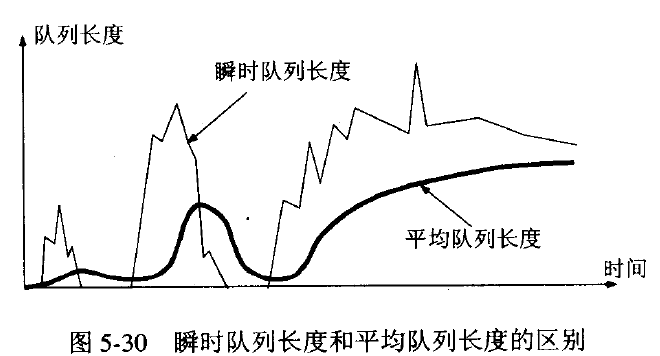
随机早期检测RED
以上的拥塞避免算法并没有和网络层联系起来,实际上网络层的策略对拥塞避免算法影响最大的就是路由器的丢弃策略。在简单的情况下路由器通常按照先进先出的策略处理到来的分组。当路由器的缓存装不下分组的时候就丢弃到来的分组,这叫做尾部丢弃策略。这样就会导致分组丢失,发送方认为网络产生拥塞。更为严重的是网络中存在很多的TCP连接,这些连接中的报文段通常是复用路由路径。若发生路由器的尾部丢弃,可能影响到很多条TCP连接,结果就是这许多的TCP连接在同一时间进入慢开始状态。这在术语中称为全局同步。全局同步会使得网络的通信量突然下降很多,而在网络恢复正常之后,其通信量又突然增大很多。
为避免发生网路中的全局同步现象,路由器采用随机早期检测(RED:randomearly detection)。该算法要点如下:
使路由器的队列维持两个参数,即队列长队最小门限min和最大门限max,每当一个分组到达的时候,RED就计算平均队列长度。然后分情况对待到来的分组:
①平均队列长度小于最小门限——把新到达的分组放入队列排队。
②平均队列长度在最小门限与最大门限之间——则按照某一概率将分组丢弃。
③平均队列长度大于最大门限——丢弃新到达的分组。
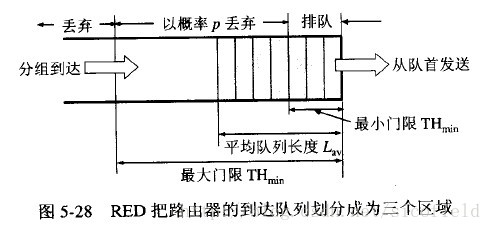
RED不是等到已经发生拥塞后才把所有队列尾部的分组全部丢弃,而是在检测到网络拥塞的早期征兆时(即路由器的平均队列长度超过一定门限值时),以概率p随机丢弃分组,让拥塞控制只在个别的TCP连接上执行,因而避免全局性的拥塞控制。
RED的关键就是选择三个参数最小门限、最大门限、丢弃概率和计算平均队列长度。最小门线必须足够大,以保证路由器的输出链路有较高的利用率。而最大门限和最小门限只差也应该足够大,是的在一个TCP往返时间RTT中队列的正常增长仍在最大门限之内。经验证明:使最大门限等于最小门限的二倍是合适的。
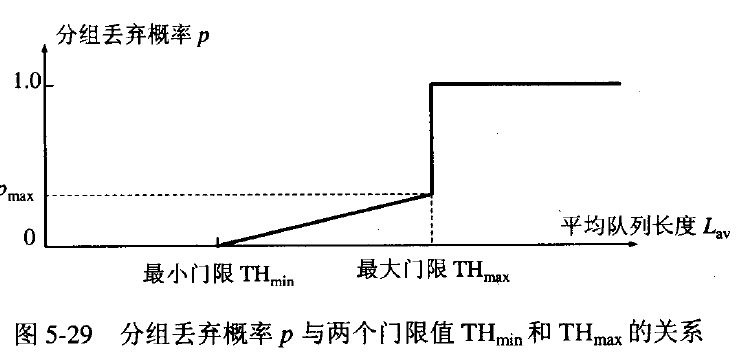
平均队列长度采用加权平均的方法计算平均队列长度,这和往返时间(RTT)的计算策略是一样的。