linux中并发无处不在,底层驱动需要考虑。
7.1 并发与竞争
7.1.1 概念
- 并发:Concurrency,多个执行单元同时、并行执行
- 竞争:Race Condistions,并发的执行单元对共享资源(硬件、软件全局变量和静态变量等)的访问很容易导致竞争
7.1.2 产生并发的情况
- SMP下多个CPU
- 单CPU内进程抢占
- 中断
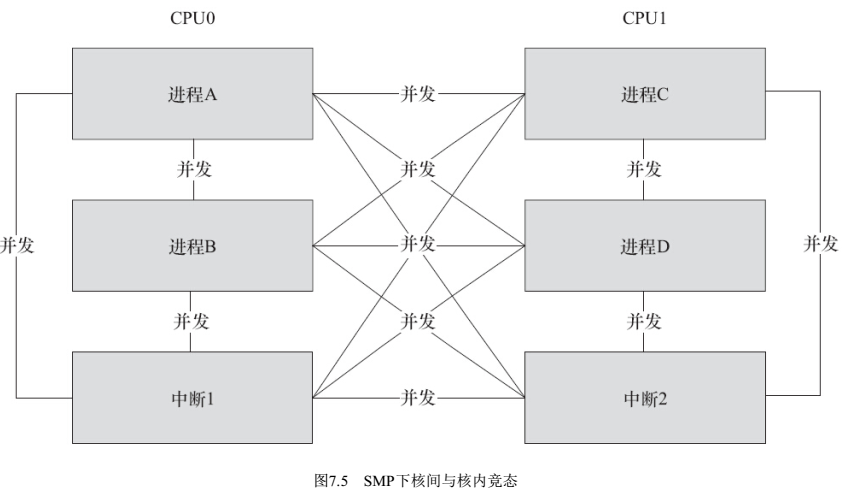
SMP是真正的并行,其他情况是“宏观并行、微观串行”引起的并发问题。解决竞争问题的办法是保证对共享资源的互斥访问,访问共享资源的代码区称为临界区,需要对临界区进行互斥保护。
7.2 编译乱序和执行乱序
7.2.1 编译乱序
- 编译器会自动对程序进行编译优化,例如-O2,优化后的汇编可能与C语言的顺序不一样;
- barrier()函数能禁止编译器乱序优化,能保证barrier前后不乱序。
7.2.2 执行乱序
内核在执行代码时,也可能进行乱序执行(out-of-order execution)。例如ARM cortex-A8不支持乱序,但是A9和A15支持乱序;A53不支持乱序,A57支持。乱序执行能提高CPU的利用率,提高效率。
ldr r0, [r1]
str r2, [r3]
例如上述程序,如果ldr执行时间较长(例如cache未命中),则CPU可以不等待ldr完成,继续执行后面的str指令,也许str指令都执行完了,但是ldr还没执行完。这就导致了乱序执行。
为什么我们感受不到乱序执行? 单核的CPU会进行“依赖点等待”,如果后面的指令依赖前面的结果,则后面指令会等待前面指令结束以后再执行,依赖点等待是硬件自动完成的,不用软件参与。
看似完美,but问题来了,双核怎么办? “依赖点等待”的作用范围是单核内部,另一各核不知道,所以多核的竞争要格外注意乱序执行。
ARM为解决乱序执行问题,支持如下操作:
dmb,DMB前面的“显示内存访问”完成后,才能进行后面的“显示内存访问”,但不影响DMB后面的其他指令执行
dsb,DSB前面“显示内存访问”完成后才执行后面的指令
isb,flush流水线,isb后面的指令都是从缓存或内存中获取的。

7.3 中断屏蔽
可避免中断和其他进程抢占导致的并发,对单核有效。 不太推荐单独使用。
- 中断屏蔽,就是关闭当前core的中断,实际是屏蔽CPSR的I位。也就保证了临界区不会受中断的影响。
- 只能停止当前core,对其他core无效
- 调度是依赖中断的,中断屏蔽以后,整个core的任务调度都不进行了,自然就不会有进程抢占了。 所以,被包含的临界区应该尽量短。
local_irq_enable() // 使能local_irq_disable() // 关闭 local_irq_save(flags) // 关闭中断,保存CPSRlocal_irq_restore(flags) // 使能中断,恢复CPSR
7.4 原子操作(对多核有作用)
保证对一个整型数据的修改是排他的。 ARM底层有指令保证,LDREX和STREX,EX是exclusive的缩写。
/* * ARMv6 UP and SMP safe atomic ops. We use load exclusive and * store exclusive to ensure that these are atomic. We may loop * to ensure that the update happens. */ static inline void atomic_add(int i, atomic_t *v) { unsigned long tmp; int result; prefetchw(&v->counter); __asm__ __volatile__("@ atomic_add " "1: ldrex %0, [%3] " " add %0, %0, %4 " " strex %1, %0, [%3] " " teq %1, #0 " " bne 1b" : "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) : "r" (&v->counter), "Ir" (i) : "cc"); }
以atomic_add()为例说明:
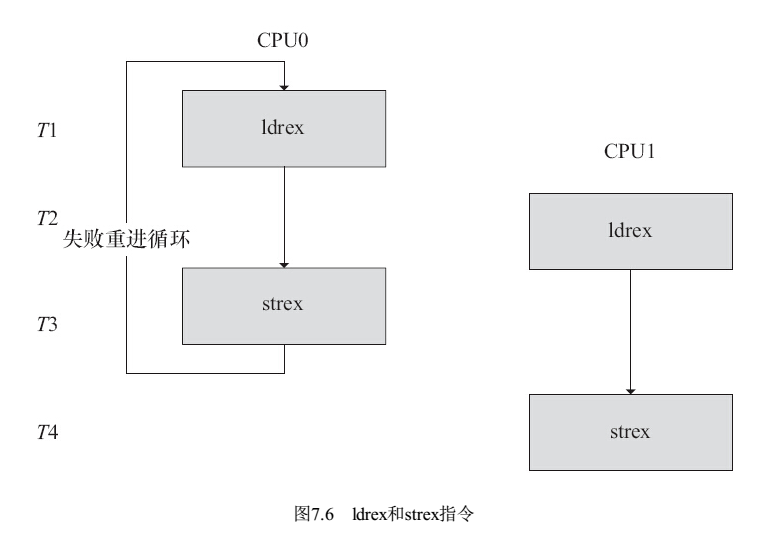
ldrex和strex配对使用,可以让总线监控ldrex和strex之间有无其他的实体存取该地址;多核或者同一个core都可以监测。
如果有并发的访问,执行strex指令时,第一个寄存器的值被设置为1(Non exclusive access),并且存储的行为也不成功;
下图中T3时刻,CPU0的strex不成功,会继续循环;
特别注意,T3时刻CPU0 strex不成功,没有实际访问外部地址,所以T4时刻CPU1的strex是成功的。
如果不成功,可能循环。
#include <linux/atomic.h>
/* * On ARM, ordinary assignment (str instruction) doesn't clear the local * strex/ldrex monitor on some implementations. The reason we can use it for * atomic_set() is the clrex or dummy strex done on every exception return. */ #define atomic_read(v) (*(volatile int *)&(v)->counter) #define atomic_set(v,i) (((v)->counter) = (i)) /* * ARMv6 UP and SMP safe atomic ops. We use load exclusive and * store exclusive to ensure that these are atomic. We may loop * to ensure that the update happens. */ static inline void atomic_add(int i, atomic_t *v) // *v+i
static inline int atomic_add_return(int i, atomic_t *v) // *v+i,并返回
static inline void atomic_sub(int i, atomic_t *v) // *v-i
static inline int atomic_sub_return(int i, atomic_t *v) // *v-i,并返回
#define atomic_inc(v) atomic_add(1, v)
#define atomic_dec(v) atomic_sub(1, v)
#define atomic_inc_and_test(v) (atomic_add_return(1, v) == 0)
#define atomic_dec_and_test(v) (atomic_sub_return(1, v) == 0)
#define atomic_inc_return(v) (atomic_add_return(1, v))
#define atomic_dec_return(v) (atomic_sub_return(1, v))
#define atomic_sub_and_test(i, v) (atomic_sub_return(i, v) == 0)
#include <asm/bitops.h>
#define set_bit(nr,p) ATOMIC_BITOP(set_bit,nr,p)
#define clear_bit(nr,p) ATOMIC_BITOP(clear_bit,nr,p)
#define change_bit(nr,p) ATOMIC_BITOP(change_bit,nr,p)
#define test_and_set_bit(nr,p) ATOMIC_BITOP(test_and_set_bit,nr,p)
#define test_and_clear_bit(nr,p) ATOMIC_BITOP(test_and_clear_bit,nr,p)
#define test_and_change_bit(nr,p) ATOMIC_BITOP(test_and_change_bit,nr,p)
注:nr是第几位,p是指针
若为单核,即使中断中不调用spin_lock也没关系,因为进程里spin_lock_irqsave已经把中断关闭了。但是考虑到双核,如果CPU0的中断不用spin_lock,中断中访问了临界区,此时CPU1也能获取自旋锁,继而访问临界区,导致临界区保护失败。
7.5 自旋锁
7.5.1 本质
执行一个原子操作test_and_set,如果不成功,则一直循环,即“自旋”,在原地打转。
【注意】
1.原地打转跟阻塞不一样。原地打转一直在转,一直占用CPU;而阻塞是释放CPU的使用权,往往意味着睡眠。
2. 持有自旋锁期间,内核抢占机制将被禁止。另一个core的抢占不受影响
7.5.2 函数
#include <linux/spinlock.h>
spinlock_t lock; // 定义自旋锁
spin_lock_init(lock); // 初始化自旋锁
spin_lock(lock); // 上锁,不成功则原地打转
spin_trylock(lock); // 上锁,不成功立即返回
spin_unlock(lock); // 释放自旋锁
自旋锁针对SMP下的多核以及单核的进程抢占,对这两种情况是有效的。
7.5.3 进程和中断访问同一临界资源
上锁以后,能保证另一个core以及本core的其他进程不打扰临界区,但是本core中断还可能影响临界区(打断),如果想杜绝这种影响,需要使用“lock+关中断”的方式。
spin_lock_irq() = spin_lock() + local_irq_disable() spin_unlock_irq() = spin_unlock() + local_irq_enable() spin_lock_irqsave() = spin_lock() + local_irq_save() spin_unlock_irqrestore() = spin_unlock() + local_irq_restore() spin_lock_bh() = spin_lock() + local_bh_disable() spin_unlock_bh() = spin_unlock() + local_bh_enable()
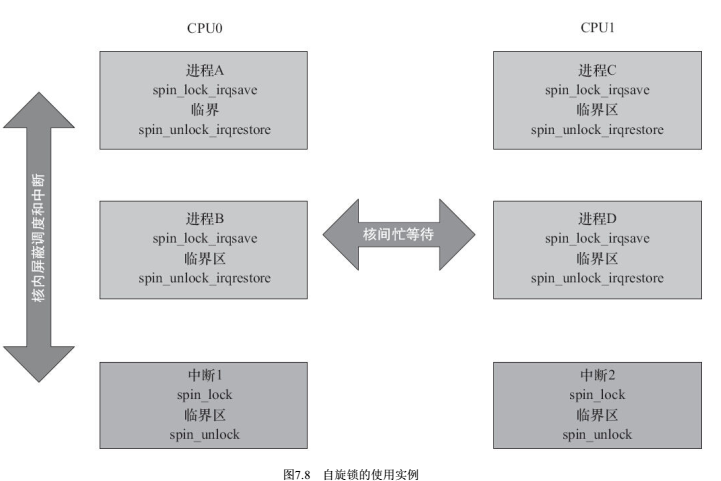
7.5.3 使用原则
- 临界区尽量短,因为自旋锁是忙等待,临界区太长会降低系统性能
- 防止死锁,例如一个已经拥有自旋锁的CPU想第二次获得这个自旋锁
- 拥有自旋锁期间,不能调用引起调度的函数,例如copy_from_user(),copy_to_user(),kmalloc(),msleep等函数,可能导致内核的崩溃
- 考虑可移植性,单核编程也要按多核考虑。例如中断中也要用spin_lock
7.6 信号量
- 信号量是同步和互斥的手段;
- 取值0/1/n,一般0/1二值信号量居多
- sem>=0,进程可以继续执行
- sem<0,则进程进入等待队列,被设置成等待状态
- P(S),P操作,S-=1,可能导致进入等待队列
- V(S),V操作,S+=1,唤醒等待队列中等待该信号量的进程
#include <linux/semaphore.h> /* Please don't access any members of this structure directly */ struct semaphore { raw_spinlock_t lock; unsigned int count; struct list_head wait_list; }; #define __SEMAPHORE_INITIALIZER(name, n) { .lock = __RAW_SPIN_LOCK_UNLOCKED((name).lock), .count = n, .wait_list = LIST_HEAD_INIT((name).wait_list), } #define DEFINE_SEMAPHORE(name) struct semaphore name = __SEMAPHORE_INITIALIZER(name, 1) static inline void sema_init(struct semaphore *sem, int val) { static struct lock_class_key __key; *sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val); lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0); } extern void down(struct semaphore *sem); // P操作,休眠的进程不能被信号唤醒 extern int __must_check down_interruptible(struct semaphore *sem); // P操作,休眠的进程可以被信号唤醒,睡眠的进程被信号打断时,down_interruptibal()函数会返回非0值 extern int __must_check down_killable(struct semaphore *sem); extern int __must_check down_trylock(struct semaphore *sem); // 不成功也不进入等待队列,而是立即返回 extern int __must_check down_timeout(struct semaphore *sem, long jiffies); extern void up(struct semaphore *sem); // V操作
7.6.1 使用信号量完成互斥
一般不用了,改用linux新的互斥机制mutex。

7.6.2 使用信号量完成同步
同步等待。

7.7 互斥体
#include <linux/mutex.h>
struct mutex my_mutex;
mutex_init(&my_mutex);
void mutex_lock( struct mutex * lock );
int mutex_lock_interruptibal( struct mutex * lock ); // 睡眠后可被信号打断
int mutex_trylock( struct mutex * lock ); // 不睡眠
void mutex_unlock( struct mutex * lock);
使用方法与信号量互斥的情况相同
mutex_lock( &my_mutex);
...... // 临界资源
mutex_unlock(&my_mutex);
【自旋锁与互斥体区别】
- 级别不同,mutex是进程级,实现上依赖spin_lock;spin_lock属于更底层的手段;
- mutex是进程级,代表进程争夺资源。如果失败,则当前进程进入睡眠,发生进程上下文切换,CPU会运行其他进程。进程切换的开销比较大,so,只有进程占用资源时间较长时,用互斥体是较好的选择;
- spin_lock得不到时会原地打转,不会进行进程切换,so,临界区较短时,用起来比较划算;
【自旋锁与互斥体的选择】
- 临界区大小:大选mutex,小选spin_lock
- 临界区是否可以阻塞:mutex的临界区可以包含引起阻塞的代码;spin_lock不可以,若包含阻塞代码,则会发生进程切换,在另一个进程里如果获取本spin_lock,就会发生死锁
- 中断中的互斥选择:mutex会引起进程切换,所以中断中不能使用,只能用spin_lock
7.8 完成量
用于一个执行单元等待另一个执行单元执行完某事。实质就是1个执行单元主动进入等待队列,另一个执行单元从等待队列中唤醒别的执行单元。

#include <linux/completion.h>
struct completion my_completion;
init_completion( &my_completion );
reinit_completion( &my_completion );
void wait_for_completion( struct completion *c ); //等待一个完成量被唤醒
void completion( struct completion *c ); // 唤醒一个等待该完成量的执行单元
void completion_all( struct completion *c ) // 唤醒所有等待该完成量的执行单元
7.9 增加互斥控制后的globalmem驱动
7.10 总结
自旋锁和互斥体相对更常用一些,注意两者的选用原则!