网络编程
网络编程顾名思义就是如何在程序中实现两台计算机的通信,它对所有开发语言都是一样的,Python也不例外。用Python进行网络编程,就是在Python程序本身这个进程内,连接别的服务器进程的通信端口进行通信。
网络中进程之间如何通信?
首要解决的问题是如何唯一标识一个进程,否则通信无从谈起!在本地可以通过进程PID来唯一标识一个进程,但是在网络中这是行不通的。其实TCP/IP协议族已经帮我们解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机,而传输层的“协议+端口”可以唯一标识主机中的应用程序(进程)。这样利用三元组(ip地址,协议,端口)就可以标识网络的进程了,网络中的进程通信就可以利用这个标志与其它进程进行交互。
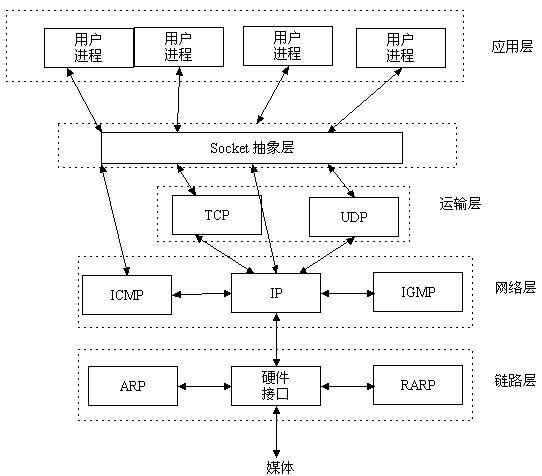
====================人工互联网协议分层========================
应用层: 它只负责产生相应格式的数据 ssh ftp nfs cifs dns http smtp pop3
-----------------------------------
传输层: 定义数据传输的两种模式:
TCP(传输控制协议:面向连接,可靠的,效率相对不高)
UDP(用户数据报协议:非面向连接,不可靠的,但效率高)
-----------------------------------
网络层: 连接不同的网络如以太网、令牌环网
IP (路由,分片) 、ICMP、 IGMP
ARP ( 地址解析协议,作用是将IP解析成MAC ):例如A寻找B,首先A发信息给交换机,然后交换机进行广播,当B接收到并返回给交换机,交换机以单播的形式将信息返回给A。
-----------------------------------
数据链路层: 以太网传输 mac地址
-----------------------------------
物理层: 主要任务是规定各种传输介质和接口与传输信号相关的一些特性 比如网卡等硬件连接
1.TCP和UDP
当您编写socket应用程序的时候,您可以在使用TCP还是使用UDP之间做出选择。它们都有各自的优点和缺点。
TCP是流协议,而UDP是数据报协议。换句话说,TCP在客户机和服务器之间建立持续的开放连接,在该连接的生命期内,字节可以通过该连接写出(并且保证顺序正确)。然而,通过 TCP 写出的字节没有内置的结构,所以需要高层协议在被传输的字节流内部分隔数据记录和字段。
另一方面,UDP不需要在客户机和服务器之间建立连接,它只是在地址之间传输报文。UDP的一个很好特性在于它的包是自分隔的(self-delimiting),也就是一个数据报都准确地指出它的开始和结束位置。然而,UDP的一个可能的缺点在于,它不保证包将会按顺序到达,甚至根本就不保证。当然,建立在UDP之上的高层协议可能会提供握手和确认功能。
对于理解TCP和UDP之间的区别来说,一个有用的类比就是电话呼叫和邮寄信件之间的区别。在呼叫者用铃声通知接收者,并且接收者拿起听筒之前,电话呼叫不是活动的。只要没有一方挂断,该电话信道就保持活动,但是在通话期间,他们可以自由地想说多少就说多少。来自任何一方的谈话都按临时的顺序发生。另一方面,当你发一封信的时候,邮局在投递时既不对接收方是否存在作任何保证,也不对信件投递将花多长时间做出有力保证。接收方可能按与信件的发送顺序不同的顺序接收不同的信件,并且发送方也可能在他们发送信件是交替地接收邮件。与(理想的)邮政服务不同,无法送达的信件总是被送到死信办公室处理,而不再返回给发送。
2.IP和Port
除了TCP和UDP协议以外,通信一方(客户机或者服务器)还需要知道的关于与之通信的对方机器的两件事情:IP地址或者端口。IP地址是一个32位的数据值,为了人们好记,一般用圆点分开的4组数字的形式来表示,比如:64.41.64.172。端口是一个16位的数据值,通常被简单地表示为一个小于65536的数字。一个IP地址获取送到某台机器的一个数据包,而一个端口让机器决定将该数据包交给哪个进程/服务(如果有的话)。
Socket是什么
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。Socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭).
说白了Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。简单来说socket就是一个模块,ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序。 所以我们只要确立了ip和port就能找到一个应用程序,并且使用socket模块来与之通信。
Socket()函数
Python 中,我们用 socket()函数来创建套接字,语法格式如下:
socket.socket([family[, type[, proto]]])
参数
- family: 套接字家族可以使AF_UNIX或者AF_INET
- type: 套接字类型可以根据是面向连接的还是非连接分为
SOCK_STREAM或SOCK_DGRAM - protocol: 一般不填默认为0
TCP编程(tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端)
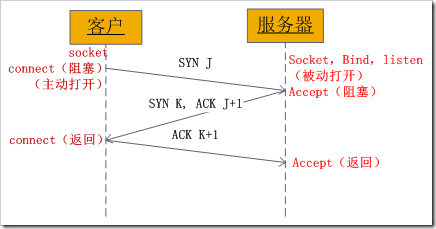
数据传输
在此期间形成一个双向的通道进行数据交互
四次挥手
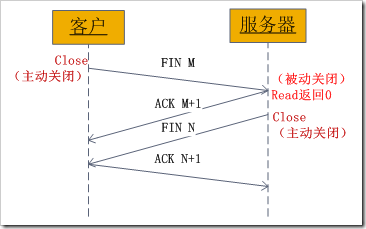
TCP流程图:
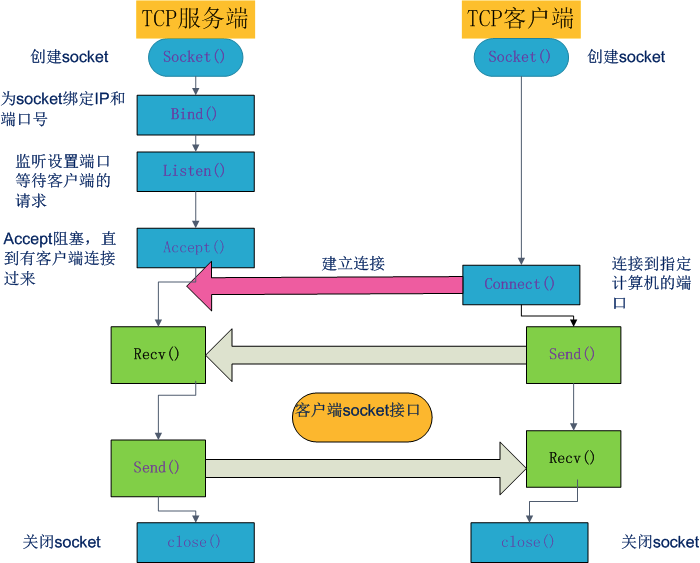
简单实例:
服务端
# import socket # sk=socket.socket(AF_INET,SOCK_STREAM) # sk.bind(('127.0.0.1',8080)) #绑定ip和端口 # sk.listen() #监听,等待网络中某一客户机的连接请求。如果客户端有连接请求,端口就会接受这个连接 # conn,addr=sk.accept() #阻塞,直到收到发来的信息。 如果没有收到,后面的不会执行。 # print(addr) # while True: # ret=conn.recv(1024).decode('utf-8') #切记,连接后是通过连接端进行操作,不再是sk对象 # if ret=='886': # break # ret=(bytes(ret,encoding='utf-8')) # print(ret) # content=input('<<<') # conn.send(bytes(content,encoding='utf-8')) # conn.close() #断开连接 # sk.close() #断开对象
客户端
# import socket
# sk=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
# sk.connect(('127.0.0.1',8080)) #连接
# while True:
# content=input('<<')
# if content=='886':
# break
# sk.send(bytes(content,encoding='utf-8'))
# ret=sk.recv(1024).decode('utf-8')
# print(ret)
# sk.close()
UDP编程(udp不基于连接,服务端和客户端哪个先启动都可以)
使用UDP协议时,不需要建立连接,只需要知道对方的IP地址和端口号,就可以直接发数据包。但是,能不能到达就不知道了。
UDP流程图:
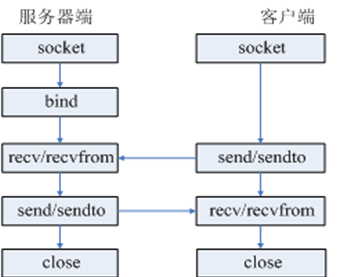
服务端: # udp的server 不需要进行监听也不需要建立连接
import socket # 在启动服务之后只能被动的等待客户端发送消息过来 s=socket.socket(type=socket.SOCK.DGRAM) s.bind(('127.0.0.1',8080)) msg,addr=s.recvfrom(1024) #recvfrom()方法返回数据和客户端的地址与端口,这样,服务器收到数据后,直接调用sendto()就可以把数据用UDP发给客户端。
print(msg.decode('utf-8'))
s.sendto(b'hi',addr)
s.close(s)
客户端:
import socket # client端不需要connect 因为UDP协议是不需要建立连接的 s=socket.socket(type=socket.SOCK.DGRAM)
ip_port('127.0.0.1',8080) #要发往的地址
s.sendto('hello',ip_port)
msg,addr=s.recvfrom(1024)
print(msg.decode('utf-8'))
s.close()
黏包问题
黏包现象只发生在tcp协议中:
Tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。TCP是面向连接的,面向流的,收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。当用TCP协议发送时无论数据再大都可以分批次的发送,不会报错。
黏包现象不会发生在udp协议中:
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y;x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠。当用UDP协议发送时,用sendto函数最大能发送数据的长度为:65507字节。用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。(丢弃这个包,不进行发送)
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。
2.实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
黏包问题解决
黏包问题对于数据传输是致命,要解决这个问题就是要想办法让接收方知道该提取多少数据,这里就需要引入struct模块,在此之前同样也需要定义一个协议
协议:网络传输中在传输过程中都是依照协议进行的,例如TCP协议和UDP协议。当然我们也可以自己写一个协议
struct模块:长度数字可以被转换成一个标准大小的bytes类型的4字节数字。因此可以利用这个特点来预先发送数据长度。struct.pack()封包 struct.unpack()解包
#服务端
import os import socket import struct import json # sk=socket.socket() # sk.bind(('127.0.0.1',8080)) # sk.listen() # conn,addr=sk.accept() # buffer=1024 # head_bytes_len=conn.recv(4) # num=struct.unpack('i',head_bytes_len)[0] # num1=conn.recv(num).decode('utf-8') # header=json.loads(num1) #报头 得到的是一个字典 # filesize=header['filesize'] #文件的大小 # print(header['filepath']) # with open(os.path.join(header['filepath'],"YY.png"),'wb')as f: # while filesize: # if filesize>=buffer: # content=conn.recv(buffer) # else: # content=conn.recv(filesize) # break
# filesize-=len(content)
# f.write(content) # conn.close() # sk.close()
#客户端
import socket
import struct
import os
import json
# sk=socket.socket()
# sk.connect(('127.0.0.1',8080))
# buffer=1024
# header={'filesize':None,'filename':r'tt.png','filepath':r'C:....'}
# filepath=os.path.join(header['filepath'],header['filename']) #文件路径
# filesize=os.path.getsize(filepath) #文件大小
# header['filesize']=filesize
# head_bytes=bytes(json.dumps(header),encoding=('utf-8'))
# head_bytes_len=struct.pack('i',len(head_bytes))
# sk.send(head_bytes_len) #先发送了报头的长度
# sk.send(head_bytes) #再发送报头
# with open (filepath,'rb')as f:
# while filesize:
# if filesize>=buffer:
# content=f.read(buffer)
# sk.send(content)
# filesize-=buffer
# else:
# content=f.read(filesize)
# sk.send(content)
# break
# sk.close()
SocketServer
SocketServer内部使用 IO多路复用 以及 “多线程” 和 “多进程” ,从而实现并发处理多个客户端请求的Socket服务端。
ThreadingTCPServer
ThreadingTCPServer实现的Soket服务器内部会为每个client创建一个 “线程”,该线程用来和客户端进行交互。
使用ThreadingTCPServer:
- 创建一个继承自 SocketServer.BaseRequestHandler 的类
- 类中必须定义一个名称为 handle 的方法
- 启动ThreadingTCPServer
import SocketServer class MyServer(SocketServer.BaseRequestHandler): def handle(self): pass if __name__ == '__main__': server = SocketServer.ThreadingTCPServer(('127.0.0.1',8080), MyServer) server.serve_forever()
ThreadingTCPServer的类图关系如下:
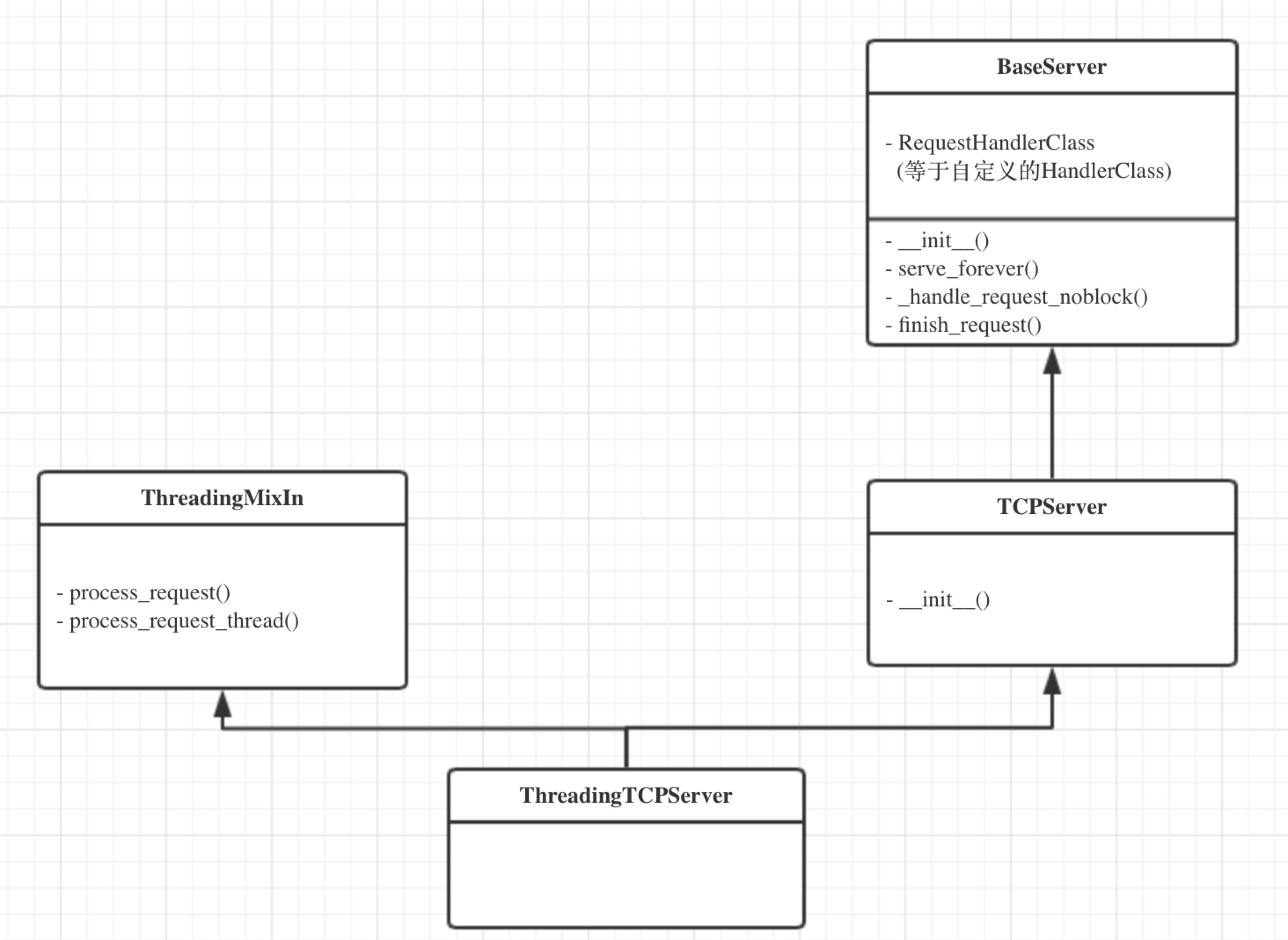
内部调用流程为:
- 启动服务端程序
- 执行 TCPServer.__init__ 方法,创建服务端Socket对象并绑定 IP 和 端口
- 执行 BaseServer.__init__ 方法,将自定义的继承自SocketServer.BaseRequestHandler 的类 MyRequestHandle赋值给self.RequestHandlerClass
- 执行 BaseServer.server_forever 方法,While 循环一直监听是否有客户端请求到达 ...
- 当客户端连接到达服务器
- 执行 ThreadingMixIn.process_request 方法,创建一个 “线程” 用来处理请求
- 执行 ThreadingMixIn.process_request_thread 方法
- 执行 BaseServer.finish_request 方法,执行 self.RequestHandlerClass() 即:执行 自定义 MyRequestHandler 的构造方法(自动调用基类BaseRequestHandler的构造方法,在该构造方法中又会调用 MyRequestHandler的handle方法)
SocketServer的ThreadingTCPServer之所以可以同时处理请求得益于 select 和 Threading 两个东西,其实本质上就是在服务器端为每一个客户端创建一个线程,当前线程用来处理对应客户端的请求,所以,可以支持同时n个客户端链接(长连接)。
ForkingTCPServer
ForkingTCPServer和ThreadingTCPServer的使用和执行流程基本一致,只不过在内部分别为请求者建立 “线程” 和 “进程”。
基本使用:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
pass
if __name__ == '__main__':
server = SocketServer.ForkingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever()