一 概述
要实际的应用微服务,需要解决以下问题:
- 客户端如何访问这些服务
- 每个服务之间如何通信
- 如此多的服务,如何实现?
- 服务挂了,如何解决?(备份方案,应急处理机制)
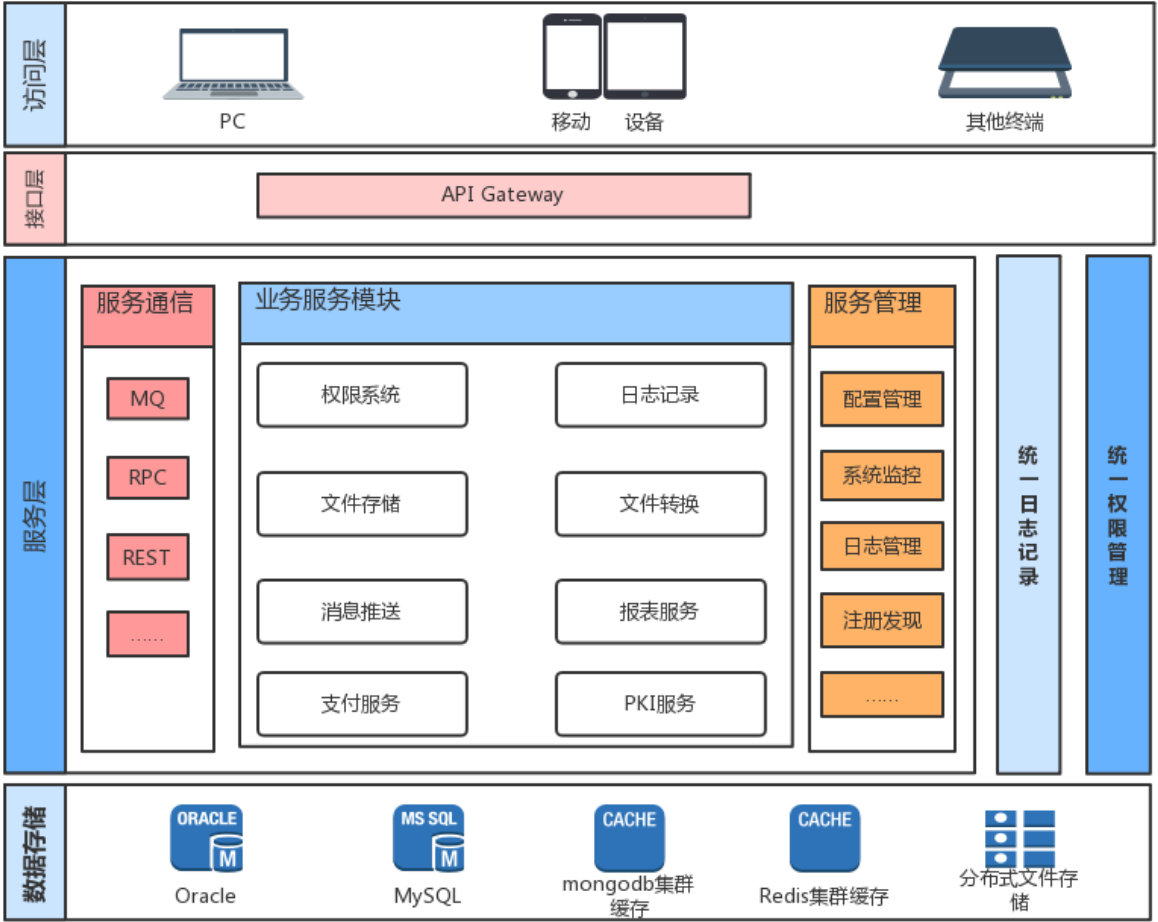
二 主流分布式服务架构的组成
服务注册与发现(consule,ZooKeeper,etcd)
服务分布式配置(nacos,Eureka,apollo)
服务负载均衡(自定义,ribbon,,eign)
服务网关(kong)
链路追踪(opentracing + jaeger )
服务熔断降级(sentinel,hystrix)
服务开发(gRPC,go-zero)
三 客户端如何访问这些服务
原来的 单体 方式开发,所有的服务都是本地的,UI 可以直接调用,现在按功能拆分成独立的服务,跑在独立的一般都在独立的虚拟机上的 Java 进程了。客户端 UI 如何访问他?
后台有 N 个服务,前台就需要记住管理 N 个服务,一个服务 下线、更新、升级,前台就要重新部署,这明显不服务我们拆分的理念,特别当前台是移动应用的时候,通常业务变化的节奏更快。
另外,N 个小服务的调用也是一个不小的网络开销。还有一般微服务在系统内部,通常是无状态的,用户登录信息和权限管理最好有一个统一的地方维护管理(OAuth)。
所以,一般在后台 N 个服务和 UI 之间一般会一个代理或者叫 API Gateway,他的作用包括:
- 提供统一服务入口,让微服务对前台透明
- 聚合后台的服务,节省流量,提升性能
- 提供安全,过滤,流控等API管理功能
其实这个 API Gateway 可以有很多广义的实现办法,可以是一个软硬一体的盒子,也可以是一个简单的 MVC 框架,甚至是一个 Node.js 的服务端。他们最重要的作用是为前台(通常是移动应用)提供后台服务的聚合,提供一个统一的服务出口,解除他们之间的耦合,不过 API Gateway 也有可能成为 单点故障 点或者性能的瓶颈。

四 每个服务之间如何通信
所有的微服务都是独立的 Java 进程跑在独立的虚拟机上,所以服务间的通信就是 IPC(Inter Process Communication),已经有很多成熟的方案。现在基本最通用的有两种方式:
同步调用
- REST
- RPC
同步调用比较简单,一致性强,但是容易出调用问题,性能体验上也会差些,特别是调用层次多的时候。一般 REST 基于 HTTP,更容易实现,更容易被接受,服务端实现技术也更灵活些,各个语言都能支持,同时能跨客户端,对客户端没有特殊的要求,只要封装了 HTTP 的 SDK 就能调用,所以相对使用的广一些。RPC 也有自己的优点,传输协议更高效,安全更可控,特别在一个公司内部,如果有统一个的开发规范和统一的服务框架时,他的开发效率优势更明显些。就看各自的技术积累实际条件,自己的选择了。
异步消息调用
- Kafka
- RocketMQ
- Rabbitmq

异步消息的方式在分布式系统中有特别广泛的应用,他既能减低调用服务之间的耦合,又能成为调用之间的缓冲,确保消息积压不会冲垮被调用方,同时能保证调用方的服务体验,继续干自己该干的活,不至于被后台性能拖慢。不过需要付出的代价是一致性的减弱,需要接受数据 最终一致性;还有就是后台服务一般要实现 幂等性,因为消息送出于性能的考虑一般会有重复(保证消息的被收到且仅收到一次对性能是很大的考验);最后就是必须引入一个独立的 Broker
五 如此多的服务,如何实现?
在微服务架构中,一般每一个服务都是有多个拷贝,来做负载均衡。一个服务随时可能下线,也可能应对临时访问压力增加新的服务节点。服务之间如何相互感知?服务如何管理?
这就是服务发现的问题了。一般有两类做法,也各有优缺点。基本都是通过 Zookeeper 等类似技术做服务注册信息的分布式管理。当服务上线时,服务提供者将自己的服务信息注册到 ZK(或类似框架),并通过心跳维持长链接,实时更新链接信息。服务调用者通过 ZK 寻址,根据可定制算法,找到一个服务,还可以将服务信息缓存在本地以提高性能。当服务下线时,ZK 会发通知给服务客户端。
基于客户端的服务注册与发现
优点是架构简单,扩展灵活,只对服务注册器依赖。缺点是客户端要维护所有调用服务的地址,有技术难度,一般大公司都有成熟的内部框架支持,比如 Dubbo。
基于服务端的服务注册与发现
优点是简单,所有服务对于前台调用方透明,一般在小公司在云服务上部署的应用采用的比较多。

六 服务挂了,如何解决?
前面提到, 单体 方式开发一个很大的风险是,把所有鸡蛋放在一个篮子里,一荣俱荣,一损俱损。而分布式最大的特性就是网络是不可靠的。通过微服务拆分能降低这个风险,不过如果没有特别的保障,结局肯定是噩梦。所以当我们的系统是由一系列的服务调用链组成的时候,我们必须确保任一环节出问题都不至于影响整体链路。相应的手段有很多:
- 重试机制
- 限流
- 熔断机制
- 负载均衡
- 降级(本地缓存)
# 重试
超时时间的配置是为了保护服务,避免consumer服务因为provider 响应慢而也变得响应很慢,这样consumer可以尽量保持原有的性能。
但是也有可能provider只是偶尔抖动,那么超时后直接放弃,不做后续处理,就会导致当前请求错误,也会带来业务方面的损失。
那么,对于这种偶尔抖动,可以在超时后重试一下,重试如果正常返回了,那么这次请求就被挽救了,能够正常给前端返回数据,只不过比原来响应慢一点。
重试时的一些细化策略:
重试可以考虑切换一台机器来进行调用,因为原来机器可能由于临时负载高而性能下降,重试会更加剧其性能问题,而换一台机器,得到更快返回的概率也更大一些
# 限流
只允许系统能够承受的访问量进来,超出的会被丢弃。降级从系统功能优先级角度考虑如何应对故障,而限流则从用户访问压力的角度来考虑如何应对故障。
算法:
漏桶算法:漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
令牌桶算法:对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
# 熔断机制:
当这个接口不可用了,然后下次掉服务的时候就不会再访问到这个节点了,然后后台还有一个程序,去实时监控这个服务节点,等他好了,你又可以访问了。简单理解就是——比方说排队买票,有3个窗口,其中一个窗口与排了很多人,然后那个售票员有事走开了,那群人不可能一直等,就去别的窗口买了,然后那个售票员回来了,会通知买票的人,这里可以买票了。
# 降级:
简单理解就是——比方说返回很多人再买票,还有人在问路,或者在咨询问题,那些问路的,咨询问题的就不处理了,只处理买票