今天准备用scrapy来爬取拉钩招聘信息,拉钩要等录后才能爬取,所以先写了一个模拟登录的程序,代码如下:
# -*- coding: utf-8 -*- import scrapy import json import urllib class Lagou2Spider(scrapy.Spider): name = 'lagou2' allowed_domains = ['lagou.com'] start_urls = ['https://lagou.com/'] headers = { "HOST": "passport.lagou.com", "Referer": "https://passport.lagou.com/login/login.html", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36", } custom_settings = { "COOKIES_ENABLED": True } post_data = { "isValidate": "true", "username": "18228xxxxxx", "password": "74ec58b525b02d0228037d6b1f50f50a", "request_form_verifyCode": "", "submit": "", } def start_requests(self): return [scrapy.Request(url='https://passport.lagou.com/login/login.html', headers=self.headers,dont_filter=True,callback=self.login)] def login(self, response): city = urllib.request.quote("成都") postUrl = "https://passport.lagou.com/login/login.json" return [scrapy.FormRequest(url=postUrl, formdata=self.post_data, headers=self.headers, callback=self.checkLogin)] def checkLogin(self, response): # 验证服务器的返回数据判断是否成功 text_json = json.loads(response.text) if "msg" in text_json and text_json["msg"] == "登录成功": for url in self.start_urls: yield scrapy.Request(url, headers=self.headers, callback=self.parse)
断点打在checkLogin,经过调试总是出现,请勿重复提交,请刷新页面重试这样的的提示
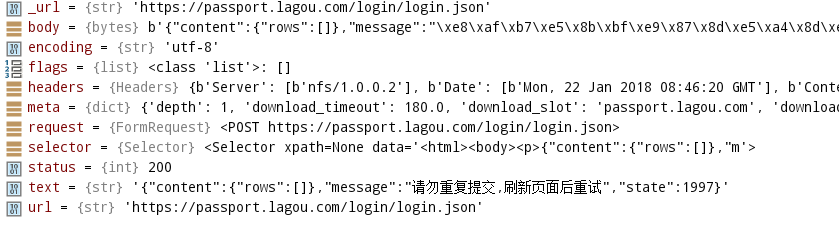
这样的提示,说明登录没有成功,我排查原因,debug了几十次,还是不行,一直提示这样的错误,我也是没有办法,这种方法不行,咱想另一种办法呗,用浏览器模拟登录,然后得到cookie后再去爬去,
这一次我用crawlSpider这个类来实现,
第一次,在middleware 中写中间件,这样当url是登录的url时就用这个中间件,
代码如下:
class JSMiddleware(object): # def __init__(self, ): # self.browser = spider.browser # super(JSMiddleware, self).__init__() #这里怎么在类中把browser 初始化好,还不知道怎么写 # @classmethod # def from_spider(cls, spider): # return cls(spider) def process_request(self, request, spider): # def login(browser,requset,spider): if spider.name == "lagoujob2": login_url = "https://passport.lagou.com/login/login.html" if "passport" in request.url: browser=spider.browser response = browser.get(login_url) time.sleep(3) username = browser.find_element_by_xpath("//div[@data-view='passwordLogin']//input[@type='text']") password = browser.find_element_by_xpath( "//div[@data-view='passwordLogin']//input[@type='password']") submit = browser.find_element_by_xpath("//div[@data-view='passwordLogin']//input[@type='submit']") username.send_keys("18228086397") password.send_keys("lq132435") submit.click() time.sleep(5) if "passport.lagou.com" not in browser.current_url: print(" login success") cookie_list = [item["name"] + "=" + item["value"] for item in browser.get_cookies()] cookie_dict=browser.get_cookies()[0] print(cookie_dict) # 获得的cookie是一个只有一个元素列表, request.cookies=cookie_dict cookiestr = ';'.join(item for item in cookie_list) request.meta["cookiejar"]=cookiestr # with codecs.open("cookiejar.txt",w) as f : # f.write(cookiestr) return HtmlResponse(url=browser.current_url,body=browser.page_source,encoding="utf-8",request=request)
我把browser 的初始化工作放在了spider 中因为这样每个spider只开启一次浏览器,且当爬虫关闭时可可浏览器,方便管理.这一次又是我想太简单了,这样做之后也还是不行,调试了十多次,还是会出现302的错误,也就说还是会跳转到登录页面,功力不够啊,
没事,这样不行,咱再想想办法啊,这一次我准备把获取cookie的代码放在一个单独的类中,这个类放在tools文件夹下,每次调用爬虫时就先执行这个类来获得cookie..tools 文件结构如下,其中 get_cookie.py 就是获取cookie的类,cookie.txt. 是把得到的cookie写入的文件,写入文件后方便下次爬取,
get_cookie.py 的代码如下 :
import time from selenium import webdriver import os import codecs class GetCookie(object): """获取拉钩的cookie""" def __init__(self): self.browser = webdriver.Chrome(executable_path="C:/codeapp/seleniumDriver/chrome/chromedriver.exe") # cookie_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__))) self.cookie_file=codecs.open("cookie.txt","w") super(GetCookie, self).__init__() def get_cookie(self, login_url): # def login(browser,requset,spider): browser=self.browser response = browser.get(login_url) time.sleep(3) username = browser.find_element_by_xpath("//div[@data-view='passwordLogin']//input[@type='text']") password = browser.find_element_by_xpath( "//div[@data-view='passwordLogin']//input[@type='password']") submit = browser.find_element_by_xpath("//div[@data-view='passwordLogin']//input[@type='submit']") username.send_keys("18228086397") password.send_keys("lq132435") submit.click() time.sleep(10) if self.browser.current_url!=login_url: print(" login success") cookie_list = [item["name"] + "=" + item["value"] for item in browser.get_cookies()] cookie_dict=browser.get_cookies()[0] print(cookie_dict) cookiestr = ';'.join(item for item in cookie_list) self.cookie_file.write(cookiestr) self.cookie_file.close() return cookie_dict
这里我开始是返回的是cookiestr ,也就是返回一个字符串,在爬虫中出错,提示说要返回一个dict ,我又返回一个dict,但是还是出错,
spider.py 中代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import urllib.request
import json
import time
import codecs
from selenium import webdriver
from lagou.items import LagouJobItem
from scrapy.http import Request, HtmlResponse
from scrapy.utils.spider import iterate_spider_output
from scrapy.spiders import Spider
from lagou.tools.get_cookie import GetCookie
# from scrapy.contrib.downloadermiddleware.cookies import CookiesMiddleware
class Lagoujob2Spider(CrawlSpider):
name = 'lagoujob2'
allowed_domains = ['www.lagou.com', "passport.lagou.com"]
start_urls = ["https://www.lagou.com/"]
rules = (
Rule(LinkExtractor(allow=("zhaopin/.*",)), follow=True),
Rule(LinkExtractor(allow=("gongsi/jd+.html",)), follow=True),
Rule(LinkExtractor(allow=(".*passport.lagou.com/.*",)),callback='login', follow=False),
Rule(LinkExtractor(allow=r'jobs/d+.html'), callback='parse_job', follow=True),
)
custom_settings = { "COOKIES_ENABLED": True,}
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.15 Safari/537.36",
}
get_cookie = GetCookie()
cookiejar = get_cookie.get_cookie("https://passport.lagou.com/login/login.html")
def login(self,response):
get_cookie = GetCookie()
cookiejar=get_cookie.get_cookie()
self.cookiejar=cookiejar
yield scrapy.Request(url='https://www.lagou.com/', callback=self.parse_job,
cookies=self.cookiejar, headers=self.headers,
meta={"cookiejar": self.cookiejar, "headers": self.headers})
def _build_request(self, rule, link, response):
#重写这个函数 添加UA
r = Request(url=link.url, headers=response.meta["headers"],callback=self._response_downloaded)
#重写这个函数 更新cookie
r.meta.update(rule=rule, link_text=link.text, cookiejar=response.meta['cookiejar'])
return r
def _requests_to_follow(self, response):
# 重写这个函数
if not isinstance(response, HtmlResponse):
return
seen = set()
for n, rule in enumerate(self._rules):
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
if links and rule.process_links:
links = rule.process_links(links)
for link in links:
seen.add(link)
r = self._build_request(n, link,response)
yield rule.process_request(r)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse_job,cookies=self.cookiejar,headers=self.headers, meta={"cookiejar": self.cookiejar,"headers":self.headers})
def parse_job(self, response):
item = LagouJobItem()
item["tilte"] = response.css(".position-head span.name ::text").extract()
yield item
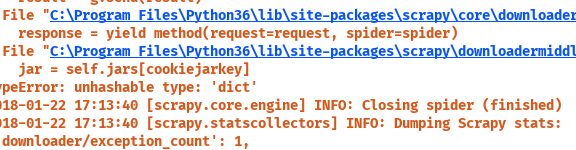
错误如下
:
这样,想了三个办法,还是没有能完成lagou的爬取,先把出现的问题和错误记在这里,接着再想办法,继续学习.