Hive是构建在hadoop之上的数据仓库。不是用来增删改查的那种数据库,那是数据库。
1)数据计算是MapReduce
2)数据存储是HDFS
认识 Hive
Hive 是基于 Hadoop 构建的一套数据仓库分析系统,它提供了丰富的 SQL 查询方式来分析存储在 Hadoop 分布式文件系统中的数据, 可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行,通过自己的 SQL 去 查询分析需要的内容,这套 SQL 简称 Hive SQL,使不熟悉 MapReduce 的用户很方便地利用 SQL 语言查询、汇总、分析。核心仍然是mapreduce作业。

Hive常见的应用场景
1、日志分析
1)统计网站一个时间段内的pv、uv
2)从不同维度进行数据分析
2、海量结构化数据离线分析
Hive的优点
1、简单容易入手
2、它是为超大数据集而设计的计算和扩展能力
3、提供统一的元数据管理
Hive的缺点
1、Hive的HQL的表达能力有限
1)迭代式算法无法表达,比如pagerank。
2)数据挖掘方面,比如kmeans。
2、Hive的效率比较低
1)hive自动生成的MapReduce作业,通常情况下不够智能化。
2)hive调优比较困难
3)hive可控性比较差
Hive的基本框架
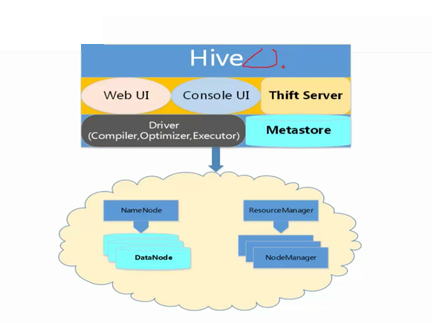
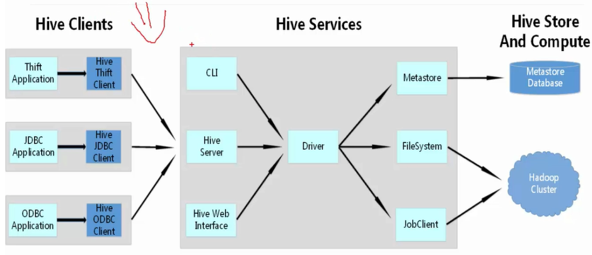
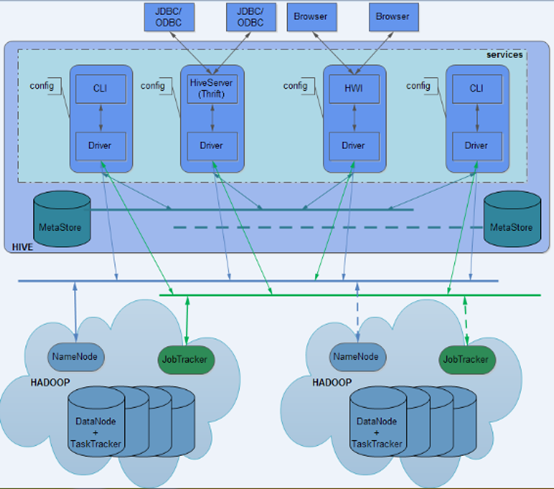
Hive的组成部分
1、用户接口
CLI、JDBC/ODBC、WebUI
2、元数据存储(MetaStore)
默认derby数据库,真实环境一般使用mysql数据库
3、驱动器(Driver)
解释器、编译器、优化器、执行器
4、hadoop分布式集群
利用MapReducer分布式计算,利用HDFS分布式存储
Hive工作原理
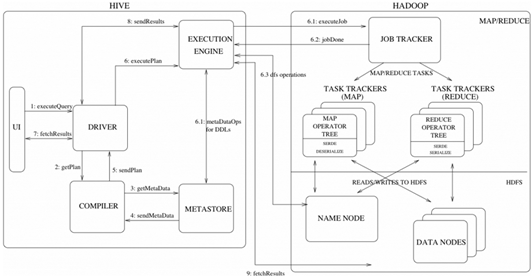
MapReduce 开发人员可以把自己写的 Mapper 和 Reducer 作为插件支持 Hive 做更复杂的数据分析。 它与关系型数据库的 SQL 略有不同,但支持了绝大多数的语句(如 DDL、DML)以及常见的聚合函数、连接查询、条件查询等操作。
具体见
Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)(非常好)
Hive 不适合用于联机(online) 事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。Hive 的特点是可 伸缩(在Hadoop 的集群上动态的添加设备),可扩展、容错、输入格式的松散耦合。Hive 的入口是DRIVER ,执行的 SQL 语句首先提交到 DRIVER 驱动,然后调用 COMPILER 解释驱动, 最终解释成 MapReduce 任务执行,最后将结果返回。
Hive 数据类型
Hive 提供了基本数据类型和复杂数据类型,复杂数据类型是 Java 语言所不具有的。下面介绍 Hive 的两种数据类型以及数据类型之间的转换。
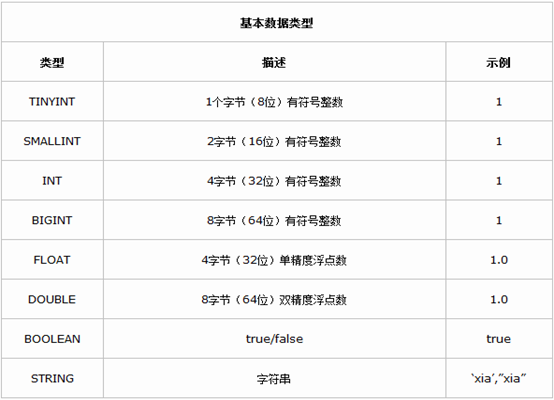
由上表我们看到Hive不支持日期类型,在Hive里日期都是用字符串来表示的,而常用的日期格式转化操作则是通过自定义函数进行操作。
Hive是用java开发的,Hive里的基本数据类型和java的基本数据类型也是一一对应的,除了string类型。有符号的整数类型:TINYINT、SMALLINT、INT和BIGINT分别等价于java的byte、short、int和long原子类型,它们分别为1字节、2字节、4字节和8字节有符号整数。Hive的浮点数据类型FLOAT和DOUBLE,对应于java的基本类型float和double类型。而Hive的BOOLEAN类型相当于java的基本数据类型boolean。
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
复杂数据类型
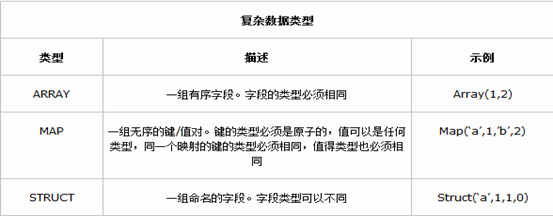
Hive 有三种复杂数据类型 ARRAY、MAP 和 STRUCT。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而STRUCT 与 C语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
复杂数据类型的声明必须使用尖括号指明其中数据字段的类型。定义三列,每列对应一种复杂的数据类型,如下所示。
CREATE TABLE complex(
col1 ARRAY< INT>,
col2 MAP< STRING,INT>,
col3 STRUCT< a:STRING,b:INT,c:DOUBLE>
)
类型转化
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式使用 INT 类型,TINYINT 会自动转换为 INT 类型, 但是 Hive 不会进行反向转化,例如,某表达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST 操作。
隐式类型转换规则如下。
1、任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成 INT,INT 可以转换成 BIGINT。
2、所有整数类型、FLOAT 和 String 类型都可以隐式地转换成 DOUBLE。
3、TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
4、BOOLEAN 类型不可以转换为任何其它的类型。
可以使用 CAST 操作显示进行数据类型转换,例如 CAST('1' AS INT) 将把字符串'1' 转换成整数 1;如果强制类型转换失败,如执行 CAST('X' AS INT),表达式返回空值 NULL。
Hve安装部署-实验环境
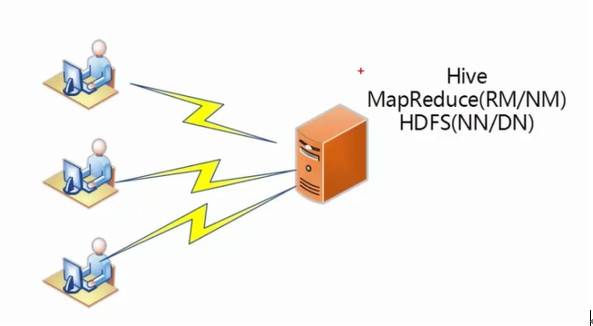
Hive其实很简单,它只有一个server,并不是分布式系统。就是单节点,我们部署在一个节点上就可以了。上述的是在测试环境中。
Hve安装部署-真实环境
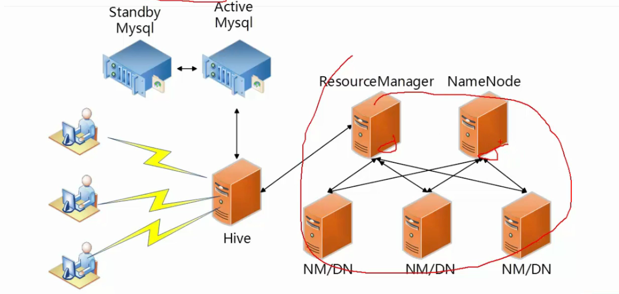
用户接口
Hive 对外提供了三种服务模式,即 Hive 命令行模式(CLI),Hive 的 Web 模式(WUI),Hive 的远程服务(Client)。下面介绍这些服务的用法。
1、 Hive 命令行模式
Hive 命令行模式启动有两种方式。执行这条命令的前提是要配置 Hive 的环境变量。
1) 进入 /home/hadoop/app/Hive 目录,执行如下命令。
./Hive
2) 直接执行命令。
Hive --service cli
Hive 命令行模式用于 Linux 平台命令行查询,查询语句基本跟 MySQL 查询语句类似,运行结果如下所示。

[hadoop@zhouls Hive]$ Hive Hive> show tables; OK stock stock_partition tst Time taken: 1.088 seconds, Fetched: 3 row(s) Hive> select * from tst; OK Time taken: 0.934 seconds Hive> exit; [hadoop@zhouls Hive]$
2、Hive Web 模式
Hive Web 界面的启动命令如下。
Hive --service hwi
通过浏览器访问 Hive,默认端口为 9999。
3、 Hive 的远程服务
远程服务(默认端口号 10000)启动方式命令如下,“nohup...&” 是 Linux 命令,表示命令在后台运行。
nohup Hive --service Hiveserver & //在Hive 0.11.0版本之前,只有HiveServer服务可用 nohup Hive --service Hiveserver2 & //在Hive 0.11.0版本之后,提供了HiveServer2服务
Hive 远程服务通过 JDBC 等访问来连接 Hive ,这是程序员最需要的方式。
这里,我是安装的是Hive1.0版本,所以启动 Hive service 命令如下。
Hive --service Hiveserver2 & //默认端口10000 Hive --service Hiveserver2 --Hiveconf Hive.server2.thrift.port 10002 & //可以通过命令行直接将端口号改为10002
Hive的远程服务端口号也可以在Hive-default.xml文件中配置,修改Hive.server2.thrift.port对应的值即可。
< property>
< name>Hive.server2.thrift.port< /name>
< value>10000< /value>
< description>Port number of HiveServer2 Thrift interface when Hive.server2.transport.mode is 'binary'.< /description>
< /property>
Hive 的 JDBC 连接和 MySQL 类似,如下所示。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class HiveJdbcClient {
private static String driverName = "org.apache.Hive.jdbc.HiveDriver";//Hive驱动名称 Hive0.11.0之后的版本
//private static String driverName = "org.apache.hadoop.Hive.jdbc.HiveDriver";//Hive驱动名称 Hive0.11.0之前的版本
public static void main(String[] args) throws SQLException {
try{
Class.forName(driverName);
}catch(ClassNotFoundException e){
e.printStackTrace();
System.exit(1);
}
//第一个参数:jdbc:Hive://zhouls:10000/default 连接Hive2服务的连接地址
//第二个参数:hadoop 对HDFS有操作权限的用户
//第三个参数:Hive 用户密码 在非安全模式下,指定一个用户运行查询,忽略密码
Connection con = DriverManager.getConnection("jdbc:Hive://zhouls:10000/default", "hadoop", "");
System.out.print(con.getClientInfo());
}
}
解释器、编译器、优化器
Driver 调用解释器(Compiler)处理 HiveQL 字串,这些字串可能是一条 DDL、DML或查询语句。编译器将字符串转化为策略(plan)。策略仅由元数据操作 和 HDFS 操作组成,元数据操作只包含 DDL 语句,HDFS 操作只包含 LOAD 语句。对插入和查询而言,策略由 MapReduce 任务中的具有方向的非循环图(directedacyclic graph,DAG)组成,具体流程如下。
1)解析器(parser):将查询字符串转化为解析树表达式。
2)语义分析器(semantic analyzer):将解析树表达式转换为基于块(block-based)的内部查询表达式,将输入表的模式(schema)信息从 metastore 中进行恢复。用这些信息验证列名, 展开 SELECT * 以及类型检查(固定类型转换也包含在此检查中)。
3)逻辑策略生成器(logical plan generator):将内部查询表达式转换为逻辑策略,这些策略由逻辑操作树组成。
4)优化器(optimizer):通过逻辑策略构造多途径并以不同方式重写。
优化器的功能如下:
将多 multiple join 合并为一个 multi-way join;
对join、group-by 和自定义的 map-reduce 操作重新进行划分;
消减不必要的列;
在表扫描操作中推行使用断言(predicate);
对于已分区的表,消减不必要的分区;
在抽样(sampling)查询中,消减不必要的桶。此外,优化器还能增加局部聚合操作用于处理大分组聚合(grouped aggregations)和 增加再分区操作用于处理不对称(skew)的分组聚合。
Hive的数据库与目录对应关系
hive> show databases; OK default
对应hdfd目录上是,/user/hive/metastore
若是自己新建一个数据库,如lesson1
hive> create database lesson1; hive> describe database extended lesson1;
对应hdfd目录上是,/user/hive/metastore/lesson1.db/
然后在这个数据库下,新建表。这里不多赘述啦
Hive中的数据组织形式

Hive的Metastore

Hive点滴 – 数据类型
http://debugo.com/hive-datatype/
7. 复合类型
复合类型在关系数据库中不曾提供,因为这些类型破坏了关系数据库的范式规则。
arrays: ARRAY<data_type> 定义数组需要指定数组的类型,数组中每一个元素都有相同的类型。访问数组中的元素使用下标访问。
maps: MAP<primitive_type, data_type> 一组键值对组成的元组,其中的值可以通过[‘KEY’]来访问。例如name的内容是map(‘first’, ‘John’, ‘last’, ‘Doe’) ,那么第一个元组是name[‘first’]。
structs: STRUCT<col_name : data_type [COMMENT col_comment], …> 类似于C语言的struct。struct内的元素可以通过”.”来访问。例如STRUCT {first STRING; last STRING}, first则可以用name.frist来访问。
union: UNIONTYPE<data_type, data_type, …> 从0.7.0开始提供。UNION类型可以如下定义,可以包含若干个任意其他类型:
CREATE TABLE union_test(foo UNIONTYPE<int, double, array<string>, struct<a:int,b:string>>);
8. 表的文本编码分割符
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
CREATE TABLE employees (
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '01'
COLLECTION ITEMS TERMINATED BY '02'
MAP KEYS TERMINATED BY '03'
LINES TERMINATED BY 'n'
STORED AS TEXTFILE;
|
Hive数据类型的文本编码:
hive的数据文件使用几种默认分割符来分割:
记录分割符“n” 分割记录,即每一行就是一个记录
域分割符 “^A”或八进制01 分割各个字段
集合元素类型分割符 “^B”或八进制02 分割struct、分割array和map中的key-value pairs
map键值分割符 “^C”或八进制03 分割map中的键和值
例如上面的表中的数据可能是:
|
1
|
Bill King^A60000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A300 Obscure Dr.^BObscuria^BIL^B60100
|
所以CSV文件的外部表定义可以是:ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,';
Hive服务
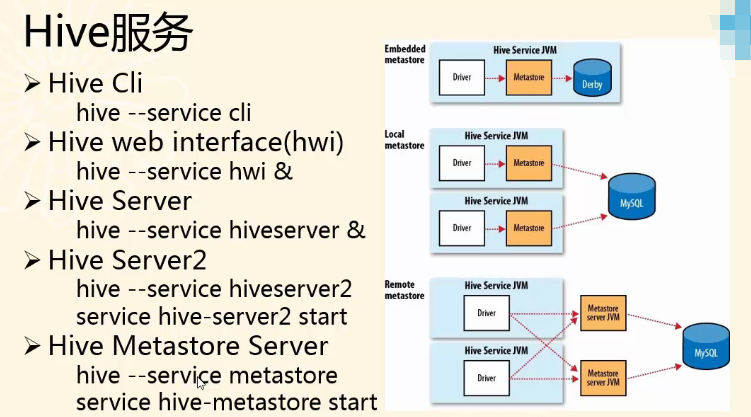
Hive Server和Hive server2都是一种远程服务。
前3项已经属于老的用法了,现在都用后2项。即,Hive Server2和Hive Metastore Server 。
更详细,见http://debugo.com/hive-cmd/ 。
Hive QL之DDL和DML



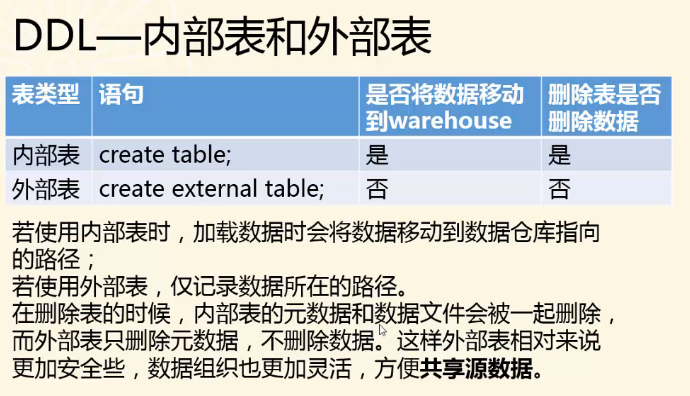
内部表和外部表
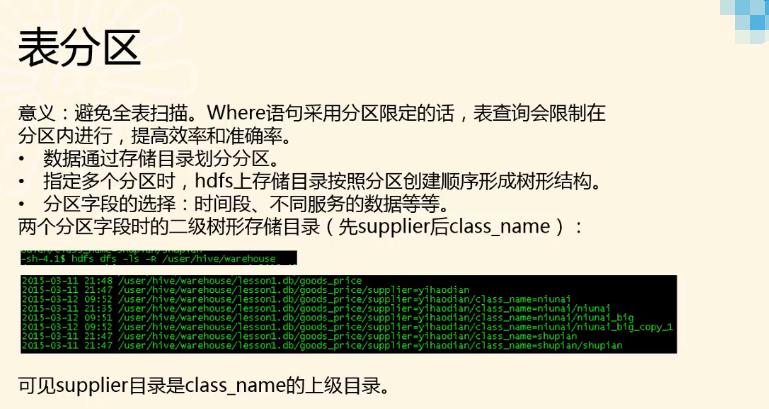
注意,指定多个分区时,hdfs上存储目录按照分区创建顺序形成树形结构。







文件数据导入表LOAD

