1. 为何不采用 one-hot 向量
假设词典中不同词的数量(词典大小)为 N,每个词可以和从 0 到 N−1的连续整数一一对应。这些与词对应的整数叫做词的索引。 假设一个词的索引为i,为了得到该词的 one-hot 向量表示,我们创建一个全 0 的长为 N的向量,并将其第 i位设成 1。这样一来,每个词就表示成了一个长度为 N的向量,可以直接被神经网络使用。
虽然 one-hot 词向量构造起来很容易,但通常并不是一个好选择。一个主要的原因是,one-hot 词向量无法准确表达不同词之间的相似度,例如我们常常使用的余弦相似度。对于向量$ x,y∈Rd$,它们的余弦相似度是它们之间夹角的余弦值。
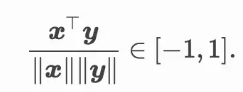
由于任何两个不同词的 one-hot 向量的余弦相似度都为 0,多个不同词之间的相似度难以通过 one-hot 向量准确地体现出来。
Word2vec 工具的提出正是为了解决上面这个问题 [1]。它将每个词表示成一个定长的向量,并使得这些向量能较好地表达不同词之间的相似和类比关系。Word2vec 工具包含了两个模型:跳字模型(skip-gram)[2] 和连续词袋模型(continuous bag of words,简称 CBOW)[3]。接下来让我们分别介绍这两个模型以及它们的训练方法。
2. 跳字模型(skip gram)
2.1 跳字模型介绍
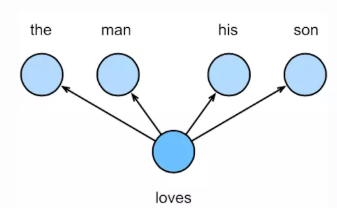
跳字模型假设基于某个词来生成它在文本序列周围的词。举个例子,假设文本序列是the、man、loves、his和son。以loves作为中心词,设背景窗口大小为 2。如图 10.1 所示,跳字模型所关心的是,给定中心词loves,生成与它距离不超过 2 个词的背景词the、man、his和son的条件概率,即:
(P(the,man,his,son∣loves))
假设给定中心词的情况下,背景词的生成是相互独立的,那么上式可以改写成
(P(the∣loves)⋅P(man∣loves)⋅P(his∣loves)⋅P(son∣loves))
在跳字模型中,每个词被表示成两个 d维向量用来计算条件概率。假设这个词在词典中索引为$ i$,当它为中心词时向量表示为 (v_i∈Rd),而为背景词时向量表示为 (u_i∈Rd)。设中心词 wc在词典中索引为 c,背景词 wo在词典中索引为 o,给定中心词生成背景词的条件概率可以通过对向量内积做 softmax 运算而得到:
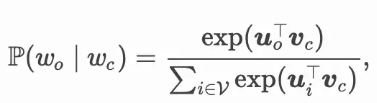
其中词典索引集$ V={0,1,…,|V|−1}$。假设给定一个长度为 (T)的文本序列,设时间步 (t)的词为 (w(t))。假设给定中心词的情况下背景词的生成相互独立,当背景窗口大小为 (m)时,跳字模型的似然函数即给定任一中心词生成所有背景词的概率
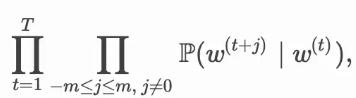
这里小于 (1) 和大于$ T$的时间步可以忽略。
2.2 跳字模型训练
跳字模型的参数是每个词所对应的中心词向量和背景词向量。训练中我们通过最大化似然函数来学习模型参数,即最大似然估计。这等价于最小化以下损失函数:
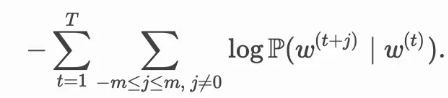
如果使用随机梯度下降,那么在每一次迭代里我们随机采样一个较短的子序列来计算有关该子序列的损失,然后计算梯度来更新模型参数。梯度计算的关键是对数条件概率有关中心词向量和背景词向量的梯度。根据定义,首先看到
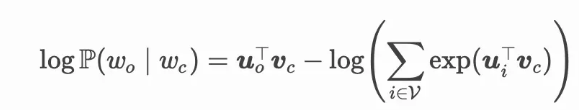
通过微分,我们可以得到上式中(v_c)的梯度
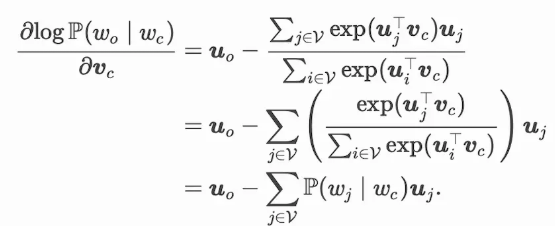
它的计算需要词典中所有词以 (wc)为中心词的条件概率。有关其他词向量的梯度同理可得。
训练结束后,对于词典中的任一索引为 (i)的词,我们均得到该词作为中心词和背景词的两组词向量$ v_i$和 (u_i)。在自然语言处理应用中,一般使用跳字模型的中心词向量作为词的表征向量。
3 连续词袋模型
3.1 连续词袋模型训练
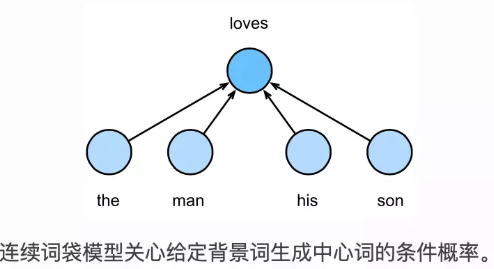
连续词袋模型与跳字模型类似。与跳字模型最大的不同在于,连续词袋模型假设基于某中心词在文本序列前后的背景词来生成该中心词。在同样的文本序列the、 man、loves、his和son里,以loves作为中心词,且背景窗口大小为 2 时,连续词袋模型关心的是,给定背景词the、man、his和son生成中心词loves的条件概率(如图 10.2 所示),也就是
(P(loves∣the,man,his,son))
因为连续词袋模型的背景词有多个,我们将这些背景词向量取平均,然后使用和跳字模型一样的方法来计算条件概率。设 (v_i∈Rd)和 (u_i∈Rd)分别表示词典中索引为 (i)的词作为背景词和中心词的向量(注意符号和跳字模型中是相反的)。设中心词 (w_c)在词典中索引为$ c$,背景词 (w_{o1},…,w_{o2m})在词典中索引为 (o_1,…,o_{2m}),那么给定背景词生成中心词的条件概率
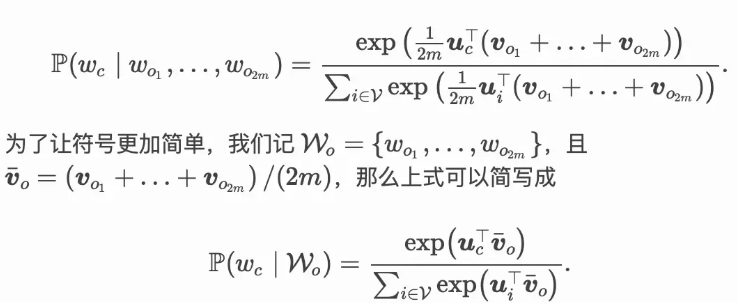
给定一个长度为(T)的文本序列,设时间步$ t(的词为) w(t)(,背景窗口大小为) m$。连续词袋模型的似然函数为由背景词生成任一中心词的概率
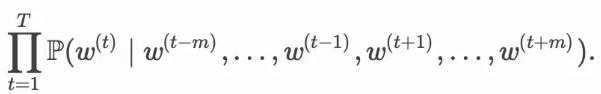
3.2 连续词袋模型训练
连续词袋模型训练同跳字模型训练基本一致。连续词袋模型的最大似然估计等价于最小化损失函数
!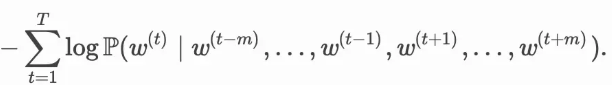
注意到
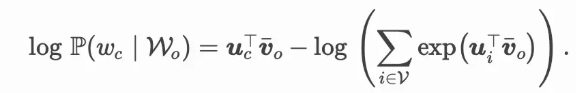
通过微分,我们可以计算出上式中条件概率的对数有关任一背景词向量 voi(i=1,…,2m)的梯度
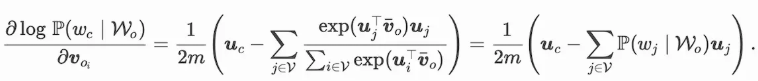
有关其他词向量的梯度同理可得。同跳字模型不一样的一点在于,我们一般使用连续词袋模型的背景词向量作为词的表征向量。
4. word2vec实现
4.1 python-gensim
from gensim.models import word2vec
sentences = word2vec.Text8Corpus("C:/traindataw2v.txt") # 加载语料
model = word2vec.Word2Vec(sentences, size=200) # 训练skip-gram模型; 默认window=5
#获取“学习”的词向量
print("学习:" + model["学习"])
# 计算两个词的相似度/相关程度
y1 = model.similarity("不错", "好")
# 计算某个词的相关词列表
y2 = model.most_similar("书", topn=20) # 20个最相关的
# 寻找对应关系
print("书-不错,质量-")
y3 = model.most_similar(['质量', '不错'], ['书'], topn=3)
# 寻找不合群的词
y4 = model.doesnt_match("书 书籍 教材 很".split())
# 保存模型,以便重用
model.save("db.model")
# 对应的加载方式
model = word2vec.Word2Vec.load("db.model")
默认参数如下:
sentences=None
size=100
alpha=0.025
window=5
min_count=5
max_vocab_size=None
sample=1e-3
seed=1
workers=3
min_alpha=0.0001
sg=0
hs=0
negative=5
cbow_mean=1
hashfxn=hash
iter=5
null_word=0
trim_rule=None
sorted_vocab=1
batch_words=MAX_WORDS_IN_BATCH
各个参数的意义:
sentences:就是每一行每一行的句子,但是句子长度不要过大,简单的说就是上图的样子
sg:这个是训练时用的算法,当为0时采用的是CBOW算法,当为1时会采用skip-gram
size:这个是定义训练的向量的长度
window:是在一个句子中,当前词和预测词的最大距离
alpha:是学习率,是控制梯度下降算法的下降速度的
seed:用于随机数发生器。与初始化词向量有关
min_count: 字典截断.,词频少于min_count次数的单词会被丢弃掉
max_vocab_size:词向量构建期间的RAM限制。如果所有不重复单词个数超过这个值,则就消除掉其中最不频繁的一个,None表示没有限制
sample:高频词汇的随机负采样的配置阈值,默认为1e-3,范围是((0,1e-5))
workers:设置多线程训练模型,机器的核数越多,训练越快
hs:如果为1则会采用hierarchica·softmax策略,Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。如果设置为0(默认值),则负采样策略会被使用
negative:如果大于0,那就会采用负采样,此时该值的大小就表示有多少个“noise words”会被使用,通常设置在(5-20),默认是5,如果该值设置成0,那就表示不采用负采样
cbow_mean:在采用cbow模型时,此值如果是0,就会使用上下文词向量的和,如果是1(默认值),就会采用均值
hashfxn:hash函数来初始化权重。默认使用python的hash函数
iter: 迭代次数,默认为5
trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受(word, count, min_count)并返回utils.RULE_DISCARD,tils.RULE_KEEP或者utils.RULE_DEFAULT,这个设置只会用在构建词典的时候,不会成为模型的一部分
sorted_vocab: 如果为1(default),则在分配word index 的时候会先对单词基于频率降序排序。
batch_words:每一批传递给每个线程单词的数量,默认为10000,如果超过该值,则会被截断
Reference:
[1] Word2vec 工具。https://code.google.com/archive/p/word2vec/
[2] Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
[3] Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[4] 词嵌入(word2vec)
[5] word2vec的几种实现