收录待用,修改转载已取得腾讯云授权
前言
前面总结的几篇spark踩坑博文中,我总结了自己在使用spark过程当中踩过的一些坑和经验。我们知道Spark是多机器集群部署的,分为Driver/Master/Worker,Master负责资源调度,Worker是不同的运算节点,由Master统一调度。
而Driver是我们提交Spark程序的节点,并且所有的reduce类型的操作都会汇总到Driver节点进行整合。节点之间会将map/reduce等操作函数传递一个独立副本到每一个节点,这些变量也会复制到每台机器上,而节点之间的运算是相互独立的,变量的更新并不会传递回Driver程序。
那么有个问题,如果我们想在节点之间共享一份变量,比如一份公共的配置项,该怎么办呢?Spark为我们提供了两种特定的共享变量,来完成节点间变量的共享。 本文首先简单的介绍spark以及spark streaming中累加器和广播变量的使用方式,然后重点介绍一下如何更新广播变量。
累加器
顾名思义,累加器是一种只能通过关联操作进行“加”操作的变量,因此它能够高效的应用于并行操作中。它们能够用来实现counters和sums。Spark原生支持数值类型的累加器,开发者可以自己添加支持的类型,在2.0.0之前的版本中,通过继承AccumulatorParam来实现,而2.0.0之后的版本需要继承AccumulatorV2来实现自定义类型的累加器。
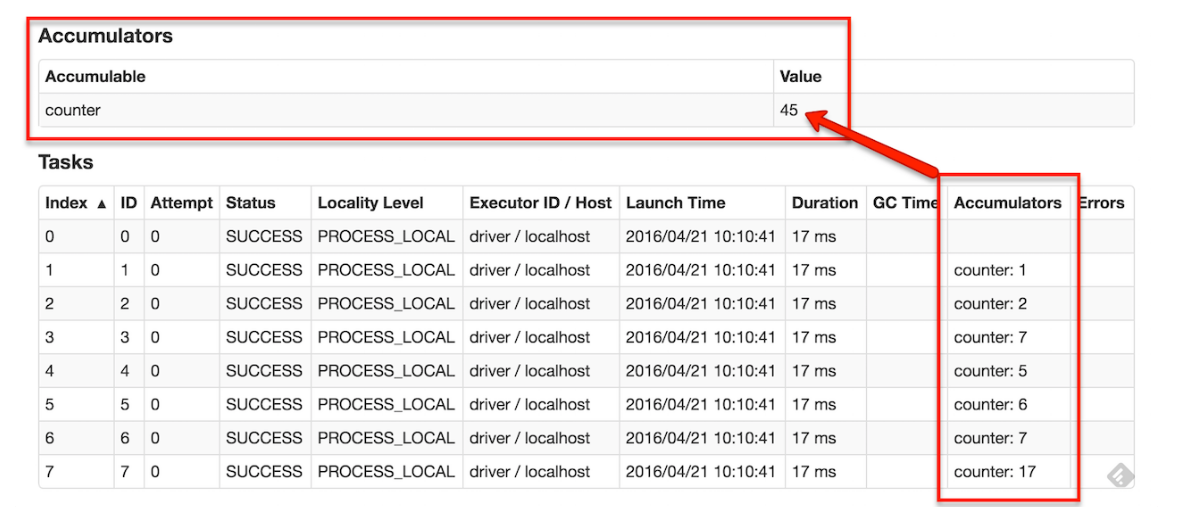
如果创建了一个具名的累加器,它可以在spark的UI中显示。这对于理解运行阶段(running stages)的过程有很重要的作用。如下图:
在2.0.0之前版本中,累加器的声明使用方式如下:
scala> val accum = sc.accumulator(0, "My Accumulator")
accum: spark.Accumulator[Int] = 0
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Int = 10
累加器的声明在2.0.0发生了变化,到2.1.0也有所变化,具体可以参考官方文档,我们这里以2.1.0为例将代码贴一下:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Long = 10
广播变量
累加器比较简单直观,如果我们需要在spark中进行一些全局统计就可以使用它。但是有时候仅仅一个累加器并不能满足我们的需求,比如数据库中一份公共配置表格,需要同步给各个节点进行查询。OK先来简单介绍下spark中的广播变量:
广播变量允许程序员缓存一个只读的变量在每台机器上面,而不是每个任务保存一份拷贝。例如,利用广播变量,我们能够以一种更有效率的方式将一个大数据量输入集合的副本分配给每个节点。Spark也尝试着利用有效的广播算法去分配广播变量,以减少通信的成本。
一个广播变量可以通过调用SparkContext.broadcast(v)方法从一个初始变量v中创建。广播变量是v的一个包装变量,它的值可以通过value方法访问,下面的代码说明了这个过程:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
从上文我们可以看出广播变量的声明很简单,调用broadcast就能搞定,并且scala中一切可序列化的对象都是可以进行广播的,这就给了我们很大的想象空间,可以利用广播变量将一些经常访问的大变量进行广播,而不是每个任务保存一份,这样可以减少资源上的浪费。
更新广播变量(rebroadcast)
广播变量可以用来更新一些大的配置变量,比如数据库中的一张表格,那么有这样一个问题,如果数据库当中的配置表格进行了更新,我们需要重新广播变量该怎么做呢。上文对广播变量的说明中,我们知道广播变量是只读的,也就是说广播出去的变量没法再修改,那么我们应该怎么解决这个问题呢?
答案是利用spark中的unpersist函数
Spark automatically monitors cache usage on each node and drops out old data partitions in a least-recently-used (LRU) fashion. If you would like to manually remove an RDD instead of waiting for it to fall out of the cache, use the RDD.unpersist() method.
上文是从spark官方文档摘抄出来的,我们可以看出,正常来说每个节点的数据是不需要我们操心的,spark会自动按照LRU规则将老数据删除,如果需要手动删除可以调用unpersist函数。
那么更新广播变量的基本思路:将老的广播变量删除(unpersist),然后重新广播一遍新的广播变量,为此简单包装了一个用于广播和更新广播变量的wraper类,如下:
import java.io.{ ObjectInputStream, ObjectOutputStream }
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.StreamingContext
import scala.reflect.ClassTag
// This wrapper lets us update brodcast variables within DStreams' foreachRDD
// without running into serialization issues
case class BroadcastWrapper[T: ClassTag](
@transient private val ssc: StreamingContext,
@transient private val _v: T) {
@transient private var v = ssc.sparkContext.broadcast(_v)
def update(newValue: T, blocking: Boolean = false): Unit = {
// 删除RDD是否需要锁定
v.unpersist(blocking)
v = ssc.sparkContext.broadcast(newValue)
}
def value: T = v.value
private def writeObject(out: ObjectOutputStream): Unit = {
out.writeObject(v)
}
private def readObject(in: ObjectInputStream): Unit = {
v = in.readObject().asInstanceOf[Broadcast[T]]
}
}
利用该wrapper更新广播变量,大致的处理逻辑如下:
// 定义
val yourBroadcast = BroadcastWrapper[yourType](ssc, yourValue)
yourStream.transform(rdd => {
//定期更新广播变量
if (System.currentTimeMillis - someTime > Conf.updateFreq) {
yourBroadcast.update(newValue, true)
}
// do something else
})
总结
spark中的共享变量是我们能够在全局做出一些操作,比如record总数的统计更新,一些大变量配置项的广播等等。而对于广播变量,我们也可以监控数据库中的变化,做到定时的重新广播新的数据表配置情况,另外我使用上述方式,在每天千万级的数据实时流统计中表现稳定,所以有相似问题的同学也可以进行尝试,有任何问题,欢迎随时骚扰沟通v
广告下我们项目:专注于游戏舆情的挖掘分析,欢迎大家来踩踩
参考文献
Spark Programming Guide2.1.0
Spark Programming Guide1.6.3
共享变量
How can I update a broadcast variable in spark streaming?