===============================
(接上文《架构设计:系统存储(29)——分布式文件系统Ceph(管理)》)
4. Ceph顶层架构总览
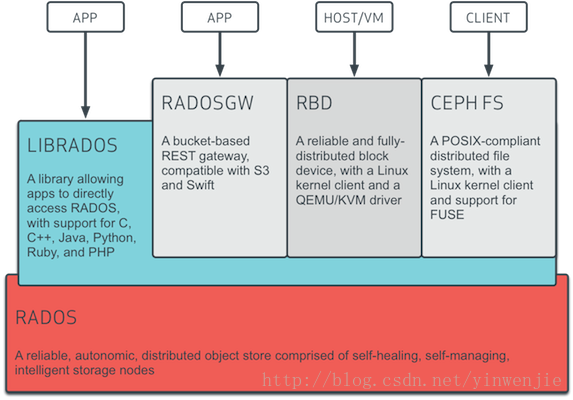
此图来源于官网,很多网络上的资料也引用了这张图,但是并没有讲清楚出现在图中的和没有出现在图中的(但同样重要的)几个名词到底是什么含义,例如,RADOS、LIBRADOS、RADOSGW、RDB、CEPH FS、MON、OSD、MDS等等。读者要搞清楚Ceph的顶层架构,就首先要搞清楚这些名词代表的技术意义,以及这些技术的在Ceph顶层架构中所占据的地位。
4-1. 名词解释
请看以下这张图对Ceph顶层架构抽象名词的功能细化:
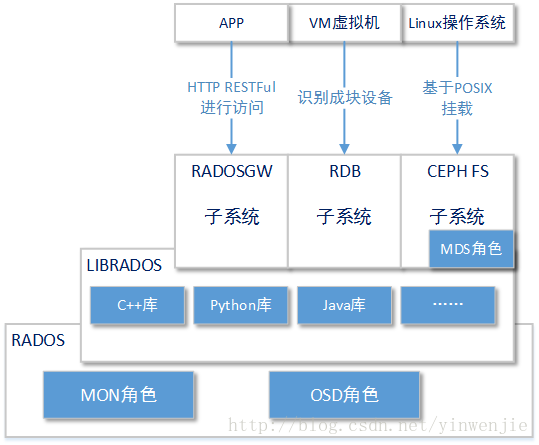
是不是这样看就要亲切多了。实际上我们一直讲的Ceph分布式对象存储系统只是上图中的RADOS部分(Reliable Autonomic Distributed Object Store),其中就包括了MON和OSD两大角色。至于MON和OSD中又包括了什么,本文后续将进行介绍。
这里要特别说明以下,请注意上图中MDS角色所在位置。我们先来回想一下在前文介绍Ceph文件系统安装的时候,当我们还没有创建MDS角色时,查看Ceph的状态同样可以看到“HEALTH_OK”的提示信息,如下所示:
[ceph@vmnode1 ~]$ sudo ceph -w
cluster d05f71b6-0d52-4cde-a010-582f410eb84d
health HEALTH_OK
monmap e1: 3 mons at {......}
election epoch 6, quorum 0,1,2 vmnode1,vmnode2,vmnode3
osdmap e13: 3 osds: 3 up, 3 in
pgmap v19: 64 pgs, 1 pools, 0 bytes data, 0 objects
15458 MB used, 584 GB / 599 GB avail
64 active+clean只是这时我们还看不到mdsmap的信息,也就是说MDS角色并不是Ceph文件系统RADOS核心部分的必备元素。实际上MDS角色是专门为Ceph FS子系统服务的角色,其上记录了元数据信息说明了Ceph FS子系统中文件目录、文件路径和OSD PG的对应关系。所以当我们创建MDS角色,并使用以下命令创建了Ceph FS文件系统后,才能看到Ceph文件系统上的MDS角色信息,如下所示:
[ceph@vmnode1 ~]$ sudo ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
[ceph@vmnode1 ~]$ sudo ceph mds stat
e7: 1/1/1 up {0=vmnode2=up:active}, 2 up:standby
[ceph@vmnode1 ~]$ sudo ceph -s
cluster d05f71b6-0d52-4cde-a010-582f410eb84d
health HEALTH_OK
monmap e1: 3 mons at {......}
election epoch 6, quorum 0,1,2 vmnode1,vmnode2,vmnode3
mdsmap e7: 1/1/1 up {0=vmnode2=up:active}, 2 up:standby
osdmap e18: 3 osds: 3 up, 3 in
pgmap v32: 128 pgs, 3 pools, 1962 bytes data, 20 objects
15459 MB used, 584 GB / 599 GB avail
128 active+clean
client io 2484 B/s wr, 9 op/sRADOS之上有一个访问协议层,任何对分布式对象存储系统(RADOS)进行读写的各类型客户端,都需要通过这个访问协议层来完成操作。而这个访问协议层的具体体现就是编程语言库称为LIBRADOS,如果您使用Ceph-deploy安装助理进行Ceph文件系统的部署的话,那么LIBRADOS在部署RADOS的同时就安装好了,默认是C++版本的。您也可以独立安装其它版本的LIBRADOS,例如Python版本或者Java版本。以下命令可以安装访问协议层对Java语言的支持库:
yum install jna
// 安装好以后相关的jar文件默认存放在/usr/share/java目录下至此技术人员就可以使用LIBRADOS直接操作RADOS中的MON、OSD角色了。但问题是,这样的调用方式并不适用于各种类型的客户端,因为毕竟只是一套访问协议层的具体实现代码。为了便于需要使用Ceph文件系统的各种客户端,在各类情况下都能进行简便的操作,Ceph官方还建立了多种子项目,产生了建立在LIBRADOS之上的多种访问方式。
CEPH FS就是我们最熟悉的一个子项目,它的目的是基于LIBRADOS,遵循POSIX规范提供给各种Linux操作系统将Ceph文件系统作为本地文件系统进行挂载使用的能力,同时也提供对FUSE的支持。在本专题之前的文章中,我们专门用整整一片文章的篇幅来介绍Ceph FS的挂载过程,请参见《架构设计:系统存储(28)——分布式文件系统Ceph(挂载)》
RADOSGW的全称是RADOS Gateway,中文名Ceph对象网关。客户端可以通过它,使用HTTP restful形态的结构访问RADOS。官网上对它的解释是:
RADOSGW is an HTTP REST gateway for the RADOS object store, a part of the Ceph distributed storage system. It is implemented as a FastCGI module using libfcgi, and can be used in conjunction with any FastCGI capable web server.
那么RDB又是什么呢?RDB全称RADOS Block Devices,初看名字就和块存储有一定关系。是的,这是基于RADOS建立的块存储软件设备。关于块存储的技术概念在本专题之前的文章中已经详细介绍过(可参见《架构设计:系统存储(1)——块存储方案(1)》),这里就不再进行赘述了。那么我们要回答的一个问题是,为什么需要把一个分布式对象存储系统通过RDB向上模拟成一个块存储设备呢?这是因为需要对诸如KVM这样的客户端访问提供支持。
举一个浅显易懂的例子,VMware的虚拟机产品相信大家都用过,VMware在创建一个虚拟机时需要设置这台虚拟机的CPU数量、内存数量等内容,而设置的存储设备时都必须是基于块存储技术的设备,例如一个物理磁盘分区、一个真实存在的光驱设备等。如果要让虚拟机能够使用Ceph文件系统,就必须在上层将Ceph文件系统模拟成一个块存储设备。实际上Ceph文件系统上层的RDB子项目,是OpenStack生态中能够集成Ceph文件系统的基本条件。Glance或者Cinder本质上是将Ceph文件系统看成和NAS一样的块存储设备并将其集成进来。
4-2. RADOS结构
关于RADOS上层的访问协议层功能,以及之上的各种子项目的介绍本文只是点到为止,相关的知识点就不再做扩展讲解了。既然Ceph分布对象存储系统中最重要的就是RADOS部分,那么我们还是要将介绍的重点收回来。
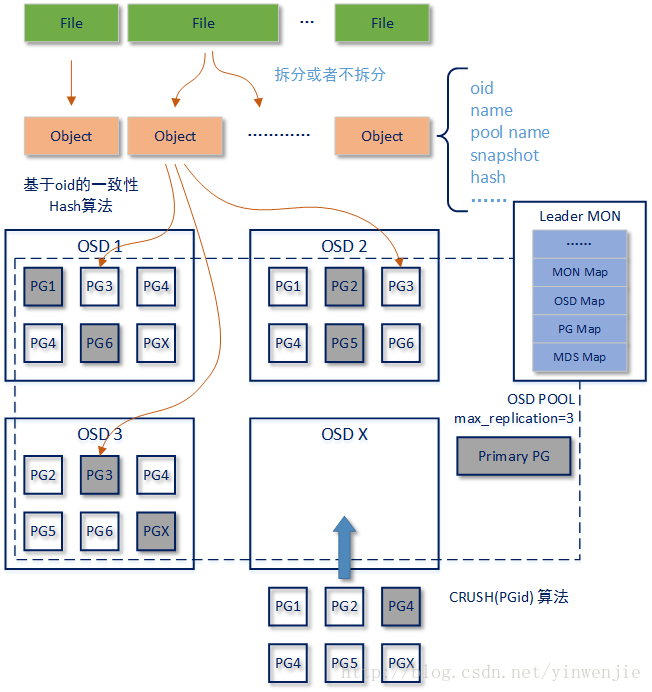
4-3. 数据存储到RADOS的过程
那么一个文件从请求进入Ceph RADOS到最终存储下来的过程过程中,到底发生了什么?这里我们直接通过原生命令操作RADOS,来测试一下这个过程:
[root@vmnode1 ~]# echo "yinwenjie ceph test info" > file
[root@vmnode1 ~]# rados put ceph-object1 ./file --pool=cephfs_data我们直接通过RADOS进行操作,就可以避免RADOS上层各个子系统对我们分析问题造成的影响。首先第一条命令我们给一个名为“file”的文件取了一个对象名,对象名为ceph-object1,并使用一个名叫datapool的OSD Pool保存这个对象。请注意这里有一个曾经解释过的概念,即OSD Pool是存在于多个OSD上PG块的集合,它是Ceph文件系统中存储对若干Object信息的管理单元。
在这个命令之下RADOS完成了几件事情:
首先RADOS会将这个文件转换成一个或者多个Object。每个Object的最大大小是有限制的,默认为4MB,所以如果文件太大,就会拆分为多个Object。每个Object信息中有几个重要属性,例如oid表示这个object在Ceph文件系统中的唯一编号、name表示Object的唯一名字、snapshot快照信息、以确定的所在pool的对应关系等等。通过以下命令,我们可以查看到保存在OSD Pool中的那个对象:
[root@vmnode1 ~]# rados -p cephfs_data ls ...... ceph-object1 ......转换为Object就可以开始进行真正的存储了,存储Object信息的单元称为PG(Placement Group),每个PG可以存储很多Object信息。并且PG还可以分为Primary PG和Replicas PG。例如上图编号为PG1的PG块就有三个,分别存放在三个不同的OSD角色中,其中灰色底的PG1是Primary PG,另外两个是Replicas PG。也就是说这个OSD Pool中的PG副本数量为3。
我们在创建OSD Pool时,需要初始化指定这个OSD Pool的PG数量,这里有一个官方推荐的公式,可以帮助读者确定这个初始的PG数量怎么设置才合理:
Total PGs = ((Total_number_of_OSD * 100) / max_replication_count) / pool_count其中 Total_number_of_OSD 表示目前Ceph文件系统中OSD角色的个数,max_replication_count表示设置的最大副本数量,pool_count表示计划设定的Ceph文件系统中的总的pool数量。举个例子来说,当Ceph文件系统中OSD角色的数量为20、最大副本数量为3、计划设定的Pool数量为3时,带入公式就可以得到PG数量应设定为222。但是关于PG的设定还有一个建议,就是建议设定为2的N次方,那么离222最近的数值就是256.Pool中PG的数量是可以调整,但是Ceph文件系统只允许调大PG的数量,不允许调减——原因很简单,因为这些PG已经存储信息了。并且调整前,最好向Ceph文件系统中加入新的OSD角色,否则调整意义就不大。
那么Ceph文件系统是怎么确定和一个Object存放到哪个PG上的呢?首先Ceph知道Pool中总的PG数量,也知道当前Object的oid编号。那么这个问题使用一致性Hash算法就很好解决了——基于Objec的oid进行Hash计算。我们可以通过以下命令,查看某个Object所在的PG位置;
[root@vmnode1 ~]# ceph osd map cephfs_data ceph-object1 osdmap e18 pool 'cephfs_data' (1) object 'ceph-object1' -> pg 1.adfc9c54 (1.14) -> up ([1,2], p1) acting([1,2], p1)在之前的文章中我们已经提到过,Ceph文件系统中最终落地存储的角色是OSD(对象存储设备),也就是说在确定Object和PG的对应关系后,还需要确定PG和OSD的对应关系,这个过程所需要考虑的因素就比在确认Object和OSD的对应关系是考虑的因素多得多了,例如承载OSD角色的物理节点其性能可能不一样,在确定承载PG的OSD时不仅要考虑散列度,还需要考虑节点的性能问题;再例如多个OSD角色可能存在于同一个物理节点上(这个特点在之前的文章中有过说明),那么相同PG的Primary PG和Replicas PG最好就不要放在同一个物理节点上,以免当物理节点崩溃后,相同PG的多个副本一起失效;再举一个例子,为了保证副本间的同步性能,最好将存储相同PG的多个副本落地在同一个机架上,或者同一个子网内,或者同一个机房内,这样可以尽可能的降低网络延迟。
显然要考虑这么多因素,肯定不是简单使用一致性Hash算法就能解决的,所以Ceph文件系统中专门有一个CRUSH算法来完成这个工作。相对于一致性Hash算法,CRUSH算法是考虑的多种因素的动态算法,只要Ceph文件系统的状态发生变化,CRUSH算法的计算结果就会不一样。例如当Ceph文件系统中某个物理节点失效时,当新的OSD节点加入并开始承载新的PG时。
通过以下命令,可以查看目前Ceph文件系统中CRUSH算法算法的装载状态:
[root@vmnode1 ~]# ceph osd crush dump { "devices": [ { "id": 0, "name": "osd.0" }, ...... ], "types": [ ...... { "type_id": 2, "name": "chassis" }, { "type_id": 3, "name": "rack" }, ...... ], "buckets": [ ...... { "id": -2, "name": "vmnode1", "type_id": 1, "type_name": "host", "weight": 13107, "alg": "straw", "hash": "rjenkins1", "items": [ { "id": 0, "weight": 13107, "pos": 0 } ] }, ...... ], "rules": [ { "rule_id": 0, "rule_name": "replicated_ruleset", "ruleset": 0, "type": 1, "min_size": 1, "max_size": 10, "steps": [ { "op": "take", "item": -1, "item_name": "default" }, ...... ] } ], "tunables": { "choose_local_tries": 0, "choose_local_fallback_tries": 0, ....... "has_v2_rules": 0, "has_v3_rules": 0, "has_v4_buckets": 0 } }
=====================
(接下文)