(接上文《源码阅读(17):红黑树在Java中的实现和应用》)
3.3、HashMap容器结构
上一篇文章我们讲解了红黑树的结构和基本操作,它属于HashMap容器重要的预备知识,现在我们可以正式开始介绍HashMap容器了。HashMap是一种Map容器,也就意味着HashMap中存储的数据对象都是以K-V键值对结构进行定义的,我们先基于JDK1.8中的源代码,介绍HashMap这个Map容器的基本构成。它包括了一个数组结构、一个链表结构和一个红黑树结构,如下图所示:

3.3.1、HashMap的基本构成

上图展示了HashMap容器的主要构造,我们可以发现HashMap容器的最基础结构是一个数组(变量名为table),这个数据的长度最小为16且可以增长,并且被要求必须以2的倍数进行数组容量的增长——这是一个非常有趣的现象,后文我们将对这个数据增长特性进行详细说明;
每个数组索引位上可能已存储K-V键值对也可能没有存储任何对象(为null);当数组索引位上存储着对象时,如果这个对象是HashMap.Node类的实例,那么将以这个索引位为开始结点构造一个单向链表结构;如果这个对象是HashMap.TreeNode类的实例,那么将从这个索引位为根结点,构造一棵红黑树。红黑树相对于单向链表来说,一个显而易见的特点就是前者进行查找操作时,其时间复杂度更低,对于红黑树的详细介绍,将在本文后续内容中展开。
3.3.2、HashMap中的链表

HashMap容器中,使用HashMap.Node类的实例构造单向链表(中的每一个结点),代码如下所示:
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
// 该属性存储了本K-V键值对信息排列在HashMap容器中所依据的hash计算结果
// 它的赋值过程请参考HashMap容器中的newNode()方法和replacementNode()方法
final int hash;
// 记录本K-V键值对信息的键信息,由于K-V键值对信息在HashMap容器的排列位置完全参考键信息
// 所以K-V键值对信息一旦完成初始化动作,就不允许变更了
final K key;
// 记录本K-V键值对信息的值信息
V value;
// 由于需要使用本类的对象构造单向链表,所以需要next属性去存储单向链表中当前结点的下一个结点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// ...... 其它一些不太重要的源代码就省略了
// 重写了hashCode()方法,以便为计算当前K-V对象的hash值提供另一种方式
public final int hashCode() {
// 通过当前K-V键值对的键信息的Hash值和值信息Hash值进行异或运算,得到当前K-V键值对的hash值
// 为什么要这样计算呢?后文将进行说明
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
// 根据上文介绍的hashCode()方法被重写的要求,其equals方法应该也被重写,以便和hashCode()方法的返回值要求匹配
public final boolean equals(Object o) {
// 当参与比较的两个K-V键值对对象的内存起始地址相同是,认为两个对象是相等的
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
// 当参与比较的两个K-V键值对对象的键信息相等,并且值信息也相等的情况下,认为两个对象是相等的
if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue()))
return true;
}
// 其它情况下都认为参与比较的两个对象不相等
return false;
}
}
以上代码片段不复杂,本身不需要太多讲解,这里再说明三个关键点即可。
- 首先是hashCode()方法被重写的要求:
Java官方对重写对象的hashCode()方法有严格的要求,这个要求在上文已经提到过,这里再进行一次强调——在这种要求下重写hashCode()方法一般都会对应重写equals()方法:
如果根据对象的equals(object)方法进行比较,得到两个对象相等的结果。那么调用两个对象的hashCode()方法就会得到相同的返回值;换句话说,这种情况下,如果调用两个对象的hashCode()方法得到了不同的返回值,那么根据对象的equals(object)方法进行比较,将得到两个对象不相等的结果。
- 其次需要理解清楚的是Node类中的hashCode方法:
虽然当前HashMap.Node类的hashCode方法被重写了,但是该方法并不会作为HashMap容器中定位某一个Node所在位置的依据。
- 接着再说明一下Objects工具:
从JDK1.7版本开始,Java为开发者提供了一个工具类Objects。该工具类提供了对象“比较”、“检验”所需的基本操作,诸如:两个对象的比较操作(compare(T , S , Comparator))、求得对象hash值的操作(hashCode(Object))、求得多个对象的hash值组合(hashCode(Object[]))、校验或确认当前对象是否为空(isNull(Object)、nonNull(Object)、requireNonNull(Object)等)、返回对象的字符串化信息(toString(Object))。
- 最后再给出HashMap.Node类的继承关系:
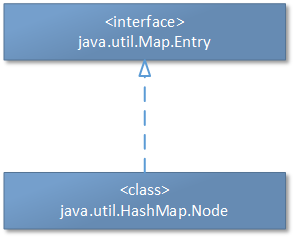
3.3.3、HashMap中的红黑树
当某个索引位上的链表达到指定的阈值(默认当单向链表的长度超过8)时,单向链表就会转化为一颗红黑树;当红黑树上的结点又足够少(默认红黑树的结点数少于6)时,红黑树又会转换成单向链表。HashMap容器中使用HashMap.TreeNode类的实例描述红黑树中的每一个结点以便构成一棵红黑树。

涉及到的HashMap.TreeNode类定义的相关代码片段如下所示:
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
// 当前结点的双亲结点(父结点)
TreeNode<K,V> parent; // red-black tree links
// 当前结点的左儿子
TreeNode<K,V> left;
// 当前结点的右儿子
TreeNode<K,V> right;
// ??这是什么
TreeNode<K,V> prev; // needed to unlink next upon deletion
// 当前结点的颜色是红色还是黑色
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// ......
// TreeNode中还有构建红黑树、解构红黑树、添加结点、移除结点的操作方法
// 这些方法将在后文中给出代码片段
}
同样我们给出HashMap.TreeNode类的继承体系:
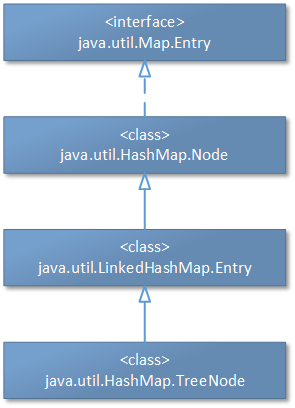
3.4、HashMap工作过程
3.4.1、关键常量和变量
上一小节我们提到了构成HashMap容器的三大基础结构:数组、链表和红黑树,本小节我们介绍这些基础结构如何进行交互。在HashMap容器中有一些关键常量信息和变量信息,在这个交互过程中发挥了作用,首先我们需要列出这些常量和变量:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// ......之前的代码省略
/**
* 默认的数组初始化容量16,这个容量只能以2的整数倍进行扩容。
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 数组最大的容量
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认的负载因子值:0.75,这个值还可以大于1
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 桶的树化阈值,当一个桶(单向链表)中的结点数量大于这个值时,就要转换成红黑树了。
* 该值必须大于2,并且至少为8。
* 但是,是否真的要进行树化,还需要再依据MIN_TREEIFY_CAPACITY常量的判定
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 桶的反树化阈值,当一个桶中红黑树的结点小于这个值时,就要从红黑树重新转换为链表了
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 那么当容器中的键值对过多时,是进行树化还是进行扩容呢?
* 针对这个矛盾的问题,使用MIN_TREEIFY_CAPACITY常量进行控制:
* 只有当容器中键值对的总容量大于该值时,某个桶中的键值对数量再大于TREEIFY_THRESHOLD时,该桶才会进行树化
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* HashMap容器的数组结构,通过该变量进行记录。
* 数组可以扩容,甚至在某些操作时允许数组的长度为0
*/
transient Node<K,V>[] table;
/**
* 该Set集合存储了当前容器中所有键值对的引用,
* 该Set集合可以被理解为缓存方案,它不会在意每个K-V键值对真实的存储位置,并且可以有效减少HashMap容器的编码工作量
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* 记录当前K-V键值对的数量
*/
transient int size;
/**
* 下一次的table数组扩容门槛,这个门槛值通过当前容量 * loadFactor得到
*/
int threshold;
/**
* The load factor for the hash table.
*/
final float loadFactor;
// .......后续代码省略
}
以上代码片段中,对于重要常量和变量的说明也是比较完善了,关于这些常量和变量如何驱动HashMap容器工作,将在下文中详细提到,这里再对一些重要信息进行补充说明:
- 负载因子loadFactor
从表面上看,loadFactor负载因子维护着容器内K-V键值对的数量与容器数组大小的平衡,通过loadFactor负载因子和当前容器的乘法计算,可以得到数组进行下一次扩容的K-V键值对的数值;但从实质上看loadFactor负载因子维护着容器存储所需的空间资源和容器操作所需要的时间资源之间的平衡。
- 数组table和容量的定义
一定要注意,数组table的容量并不是HashMap容器的容量,因为从数组中的某一个索引位出发,都可能存在一个单向链表或者一颗红黑树;另外即使在数组中的某些索引位上还没有存储任何K-V键值对的情况下,数组也会进行扩容操作。
3.4.2、HashMap初始化
HashMap容器的初始化过程,主要是构建HashMap容器中数组结构、初始化负载因子、确定扩容门槛的过程。首先给出相关代码片段:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 该构造函数有一个传入参数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 该构造函数没有传入参数
public HashMap() {
// 这时设定容器的负载因子为默认值(0.75)
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
// 该构造函数传入两个参数
// initialCapacity:指定的初始化大小,不能小于0
// loadFactor 指定的负载因子,不能小于0
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
// 该判定条件约定了当前指定的初始化容量,不能大于“最大容量”
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
// 通过tableSizeFor方法,基于initialCapacity值,确定正确的初始化容量
// tableSizeFor方法将有一个返回值,该值表示下一次table数组扩容的门槛值——注意,构造完成后table数组任然是没有空间的
this.threshold = tableSizeFor(initialCapacity);
}
// 我们重点来看一下tableSizeFor方法内部过程
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
}
以上tableSizeFor(int)方法中的计算过程,可以用下图进行表达。以下示例中入参值为“253”,并不是一个2的倍数:

例如以上实例中,通过该方法计算得到的值是255;再例如,方法的入参如果为73,那么计算得到的值为127。这种处理模式,可以为“数组的容量无论如何扩容,其容量大小只能为2的倍数”这样的数组扩容规范,提供处理基础。HashMap(int , float) 构造函数中只需要通过tableSizeFor(int)方法得到的返回值 + 1,就得到比当前initialCapacity入参值更大,且最接近2的倍数的table数组容量值。
3.4.3、HashMap添加K-V键值对(链表方式)
HashMap容器中用于添加新的键值对的方法是put(K ,V)方法,如果新加入的K-V键值对的键与某个已存在的K-V键值对的键相同(相同是指键的hash值相同),则替换原来K-V键值对中的值信息。本小节我们将重点分析这个方法,以及该方法所扩展使用的关联方法。首先给出该方法的代码片段:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 通过该方法可以计算指定对象的hash值,
// HashMap容器中的K-V键值对,主要是通过该方法计算键的hash值
// 如果当前传入的对象为null,则返回0,这就是为什么HashMap容器允许key键为null的原因
static final int hash(Object key) {
int h;
// 基于对象的hashcode()方法的返回值
// 并通过位右移操作和异或操作计算对象的hash值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* param onlyIfAbsent 如果当前参数为false,则不更新新值
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果当前HashMap容器的数组为0,或者为null
// 则首先进行扩容操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 请注意这里的计算 i = (n - 1) & hash],其中n为当前容器中数组的长度
// 这个与运算的计算,i的值将不会超过n - 1的范围。后文将进行详细说明
// 这个计算式将得到新的K-V键值所属的桶,以及当前桶的第一个对象值p
// 如果条件成立,说明当前数组的索引位上还没有任何K-V键值对信息
if ((p = tab[i = (n - 1) & hash]) == null)
// 于是直接在这个索引位添加一个新的node结点即可
tab[i] = newNode(hash, key, value, null);
// 其它情况做如下处理
else {
Node<K,V> e; K k;
// 如果条件成立,说明K-V键值对的键值和当前桶的一个结点的键值相同
// 则为变量e赋值p
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果条件成立,说明当前桶存储的是红黑树性质的结点
// 所以使用红黑树的方式添加结点,这个方法将在后文中单独说明
// 该方法的返回值,表示是否已存在和当前正在添加的K-V键值对中键信息相同的红黑树结点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 其它情况下,通过以下for循环依次遍历当前桶上单向链表的每一个结点
for (int binCount = 0; ; ++binCount) {
// 如果以下条件成立,说明已经遍历完当前链表的所有结点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果当前条件成立,则说明当前结点的k键和当前添加的K-V键值对的k键值相同
// 这时之前通过e = p.next代码完成的e的赋值,这里直接退出循环
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
// 如果循环执行到这里,说明以上情况都不成立,则将p.next对象赋值给p对象
// 以便准备进行下一次遍历
p = e;
}
}
// 如果条件成立,说明当前容器中已存在和新添加的K-V键值对键信息相同的历史K-V键值对
// 那么本次操作不是添加操作而是更新操作
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 如果条件成立,才能更新新值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 触发afterNodeAccess方法
afterNodeAccess(e);
return oldValue;
}
}
// 当代码执行到这里,说明当前操作是添加操作
// 那么写操作计数器加1
++modCount;
// 如果添加结束后,当前容器中所有结点的总数大于“门槛值”
// 则执行扩容操作,扩容操作会在后文中详细介绍
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}
以上代码比较复杂如果一次没有厘清,可多看几次。这里对代码片段中几个重要的代码信息进行讲解,下面我们对其中几个难理解的点进行讲解,以便协助读者理解:
- (h = key.hashCode()) ^ (h >>> 16)
hash(Object)方法通过以上计算式得到指定对象的hash值,从过程上讲就是取得当前对象的hash值,首先进行带符号位的左移16位操作(这时候对象hash值的高位段就变成了低位段),然后再和对象原来的hash值进行“异或”运算。计算过程可以用下图实例表达:

- i = (n - 1) & hash
putVal(int, K, V, boolean, boolean) 方法中,通过该计算式计算某个hash值应该存储在数组的哪个索引位上;请注意计算式中的n值代表当前数组的长度,长度减一后的“与”运算结果值不可能超过“n-1”,于是就可以正确确定hash值所代表的当前对象在当前数组的哪一个索引位上。这个过程可以用下图实例表达:

- (k = p.key) == key || (key != null && key.equals(k)))
这个表达式在putVal(int, K, V, boolean, boolean) 方法中有两个位置出现过,一个是得到新增K-V键值对应该存储的桶的初始位置后(且桶中至少有一个结点),判定新增的K-V键值对的键值是否匹配桶中的第一个结点时;另一个是在桶结构是单向链表的前提下,循环判定新增的K-V键值对的键值是否匹配当前链表上的某一个结点时;
判定条件是,新增的K-V键值对的键对象的内存起始位置和当前结点key属性的内存起始位置一致;或者新增的K-V键值对的键对象不为null的情况下,对象的equals()方法返回的结果为true。
================
(接后文《源码阅读(19):Java中主要的Map结构——HashMap容器(下)》)