1. HTTP 操作
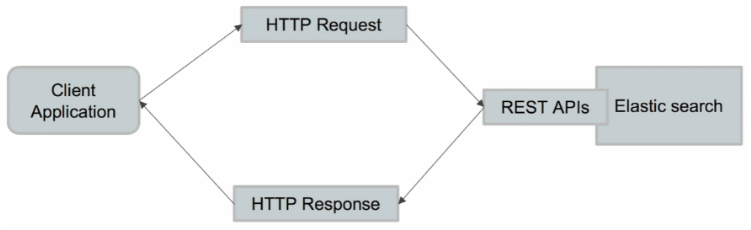
1.1 索引操作
1.1.1 创建索引
在 Lucene 中,创建索引是需要定义字段名称以及字段的类型的,而在 Elasticsearch 中提供了非结构化的索引,就是不需要创建索引结构,即可写入数据到索引中,实际上在 Elasticsearch 底层会进行结构化操作,此操作对用户是透明的。
在 Postman 中,向 ES 服务器发送请求:[PUT] http://127.0.0.1:9200/shopping

PUT 请求方式具有幂等性。
1.1.2 查询所有索引
在 Postman中,向 ES 服务器发送请求:[GET] http://127.0.0.1:9200/_cat/indices?v,这里请求路径中的 _cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引,就好像 MySQL 中的 SHOW TABLES 的感觉,服务器响应结果如下:

各字段含义:
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态:green(集群完整)、yellow(单点正常、集群不完整)、red(单点不正常) |
| status | 索引状态(打开/关闭) |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
其他的 _cat:
GET /_cat/nodes 查看所有节点
GET /_cat/health 查看ES健康状况
GET /_cat/master 查看主节点
GET /_cat/indices 查看所有索引
1.1.3 查询单个索引
在 Postman 中,向 ES 服务器发送请求:[GET] http://127.0.0.1:9200/shopping(查看索引向 ES 服务器发送的请求路径和创建索引是一致的,但是 HTTP 方法不一致。这里可以体会一下 RESTful 的意义~)

1.1.4 删除索引
在 Postman 中,向 ES 服务器发 DELETE 请求 http://127.0.0.1:9200/shopping。
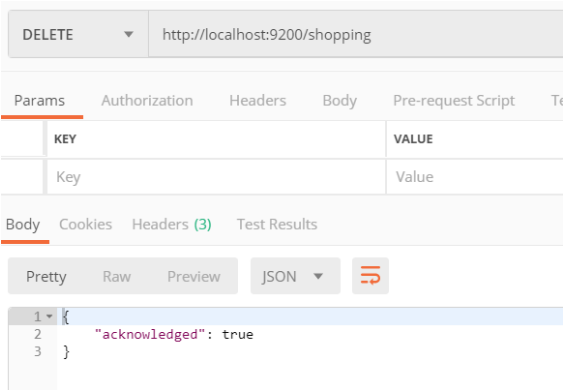
重新访问索引时,服务器返回响应:索引不存在

1.2 映射操作
1.2.1 Mapping
有了索引库,等于有了数据库中的 Database。接下来就需要建索引库(Index)中的映射了,类似于数据库(Database)中的表结构。创建数据库表需要设置字段名称、类型、长度、约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做「映射(Mapping)」。
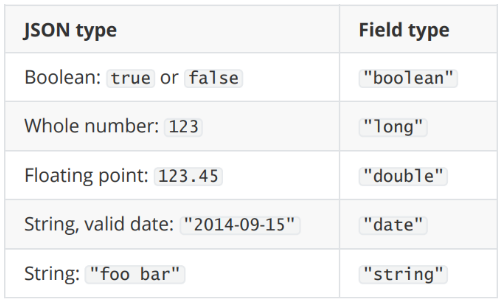
实际上每个 type 中的字段是什么数据类型,由 mapping 定义。但是如果没有设定 mapping 系统会自动,根据一条数据的格式来推断出应该的数据格式。mapping 除了自动定义,还可以手动定义,但是只能对新加的、没有数据的字段进行定义。一旦有了数据就无法再做修改了。
自动判断的规则如下:
1.2.2 创建映射
创建索引 PUT example 后,再创建其映射 PUT example/_mapping(把请求方式换成 GET 即是查询 mapping 信息):
{
"properties": {
"parent": {
"properties": {
"id": {
"type": "integer"
},
"parentName": {
"type": "text"
}
}
},
"child": {
"properties": {
"id": {
"type": "integer"
},
"childName": {
"type": "text"
},
"parentId": {
"type": "integer"
}
}
},
"relation": {
"type": "join",
"relations": {
"parent": [
"child"
]
}
}
}
}
1.2.3 映射说明
(1)字段名:任意填写
(2)type:类型,ES 中支持的数据类型非常丰富,说几个关键的。
- Date:日期类型
- Array:数组类型
- Object:对象
- 字符串类型,又分两种:
- text 类型,当一个字段是要被全文搜索的,比如 Email 内容、产品描述,应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text 类型的字段不用于排序,很少用于聚合。
- keyword 类型适用于索引结构化的字段,比如 email 地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中 status 属性为 published 的文章)、排序、聚合。keyword 类型的字段只能通过精确值搜索到。
- 数值类型,也分两类:
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
"price": { "type": "scaled_float", "scaling_factor": 100 }, 由于比例因子为 100,如果我们输入的价格是 23.45 则 Es 中会将 23.45*100 存储起来 如果输入的价格是 23.456,ES会将 23.456*100 再取一个接近原始值的数,得出 2346 使用比例因子的好处是整型比浮点型更易压缩,节省磁盘空间。
【补充】Text 类型字段排序问题:如果对一个 textField 进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了。通常解决方案是,将一个 textField 建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序。
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
...
}
}
}
(3)index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
(4)store:是否将数据进行独立存储,默认为 false。
原始的文本会存储在 _source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从 _source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置 "store": true 即可,获取独立存储的字段要比从 _source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
(5)analyzer:分词器,这里的 ik_max_word 即使用 IK 分词器(文本分析,是将全文本转换为一系列单词的过程,也叫分词)。
注意!除了在数据写入时将文档进行转换,查询的时候也需要使用相同的分析器对查询内容进行分析。即我们写入“苹果”的时候分词成了“苹”和“果”,查询“苹果”的时候同样也是分词成“苹”和“果”去查。
1.2.4 创建索引及映射
索引、映射规则、设置、别名一并创建
{
"settings": { ...any settings... },
"mappings": {
"dynamic": "true|false|strict",
"date_detection": false,
"numeric_detection": true,
"properties": {
"field1": { ... },
...
}
},
"aliases": {
"default_index": {}
}
}
- 定制 dynamic 策略 // 映射创建完毕后,插入文档时遇到陌生字段的处理方式:
- true:遇到陌生字段就进行 dynamic mapping(Es 会根据传入的值来推断类型);
- false:新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍将出现在返回点击的源字段中。这些字段不会添加到映射中,必须显式添加新字段;
- strict:遇到陌生字段,就报错。
- date_detection 日期探测
- 默认会按照一定格式识别 date类型,比如
yyyy-MM-dd。但是如果某个 field 先过来一个2017-01-01的值,就会被自动 dynamic mapping 成 date,后面如果再来一个"hello world"之类的值,就会报错。可以手动关闭 date_detection,如果有需要就自己手动指定某个 field 为 date 类型; - 自定义日期格式为
"dynamic_date_formats": ["MM/dd/yyyy"],然后新增文档的指定格式字段("birth": "10/18/1998")就会被自动映射成 date 类型了;
- 默认会按照一定格式识别 date类型,比如
- numeric_detection 数字探测
- 虽然 json 支持本机浮点和整数数据类型,但某些应用程序或语言有时可能将数字呈现为字符串;
- 通常正确的解决方案是显式地映射这些字段,但是可以启用数字检测(默认情况下禁用)来自动完成这些操作。
1.2.4 自定义动态映射模板
举例:
- 使用自定义动态映射模板来创建索引
PUT /test_dynamic_mapping_template { "mappings": { "dynamic_templates": [{ # 固定名词 "en": { # 策略名字 "match": "*_en", # 匹配的属性名 "match_mapping_type": "string", # 匹配的属性值 "mapping": { "type": "text", # 映射成 text 类型 "analyzer": "english" # 使用 english 分词器 } } }] } } - 插入数据
PUT /my_index/_doc/1 { "title": "this is my first article" } PUT /my_index/_doc/2 { "title_en": "this is my first article" } - 搜索
GET my_index/_search?q=first title 没有匹配到任何的 dynamic 模板,默认就是 standard 分词器, 不会过滤停用词,is 会进入倒排索引,用 is 来搜索是可以搜索到的 GET my_index/_search?q=is title_en 匹配到了 dynamic 模板,就是 english 分词器,会过滤停用词 is 这种停用词就会被过滤掉,用 is 来搜索就搜索不到了
模板参数:
"match": "long_*",
"unmatch": "*_text",
"match_mapping_type": "string",
"path_match": "name.*",
"path_unmatch": "*.middle",
"match_pattern": "regex",
"match": "^profit_\d+$"
使用场景:
- 结构化搜索:默认情况下,Es 将字符串字段映射为带有子关键字字段的文本字段。但是,如果只对结构化内容进行索引,而对全文搜索不感兴趣,则可以仅将“字段”映射为“关键字”。请注意,这意味着为了搜索这些字段,必须搜索索引所用的完全相同的值;
{ "strings_as_keywords": { "match_mapping_type": "string", "mapping": { "type": "keyword" } } } - 仅搜索:与前面的相反,如果只关心字符串字段的全文搜索,并且不打算对字符串字段运行聚合、排序或精确搜索,可以告诉弹性搜索将其仅映射为文本字段;
{ "strings_as_keywords": { "match_mapping_type": "string", "mapping": { "type": "text" } } } - 不关心评分:norms 是指标时间的评分因素。如果您不关心评分,例如,如果您从不按评分对文档进行排序,则可以在索引中禁用这些评分因子的存储并节省一些空间。
{ "strings_as_keywords": { "match_mapping_type": "string", "mapping": { "type": "text", "norms": false, "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } }
1.3 文档操作

1.3.1 创建文档
发送请求:[POST] .../{索引}/{类型}/{id}。非结构化的索引,不需要事先创建,直接插入数据默认创建索引。
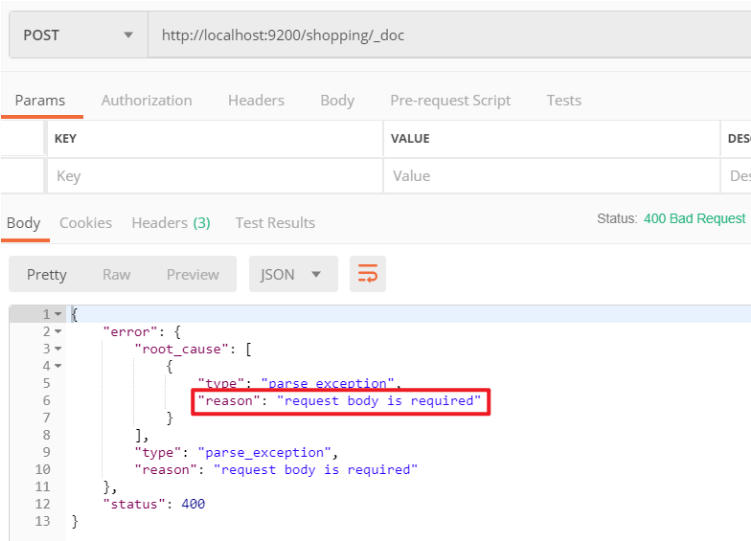
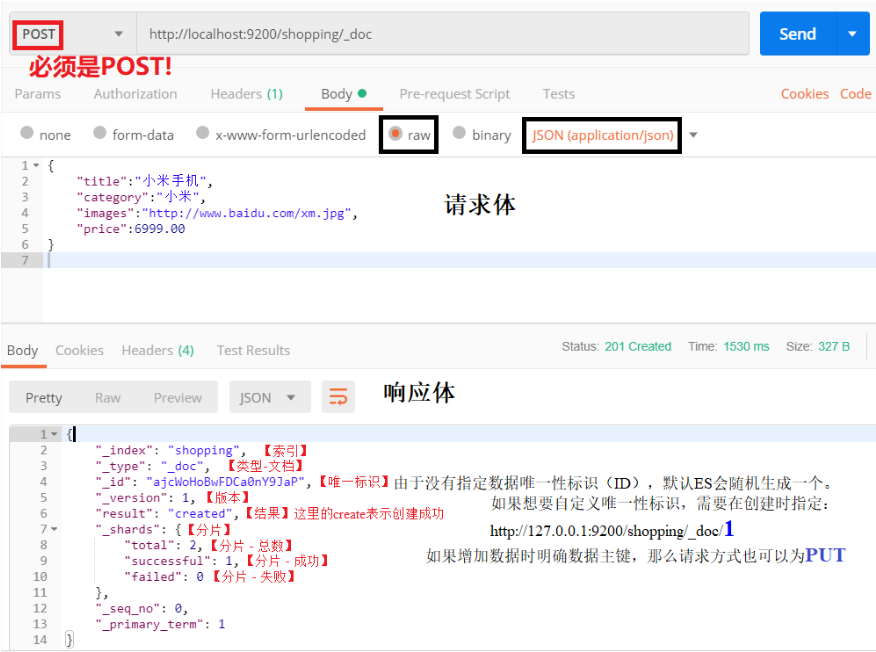
POST 操作不具有幂等性,多次点击 Send 会发现响应体中的 _id 每次都不一样。但如果自己提供唯一性 id,请求方式可以使用 PUT,因为结果确定。
1.3.2 查询文档
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询。在 Postman 中,向 ES 服务器发 GET 请求 http://127.0.0.1:9200/shopping/_doc/1101
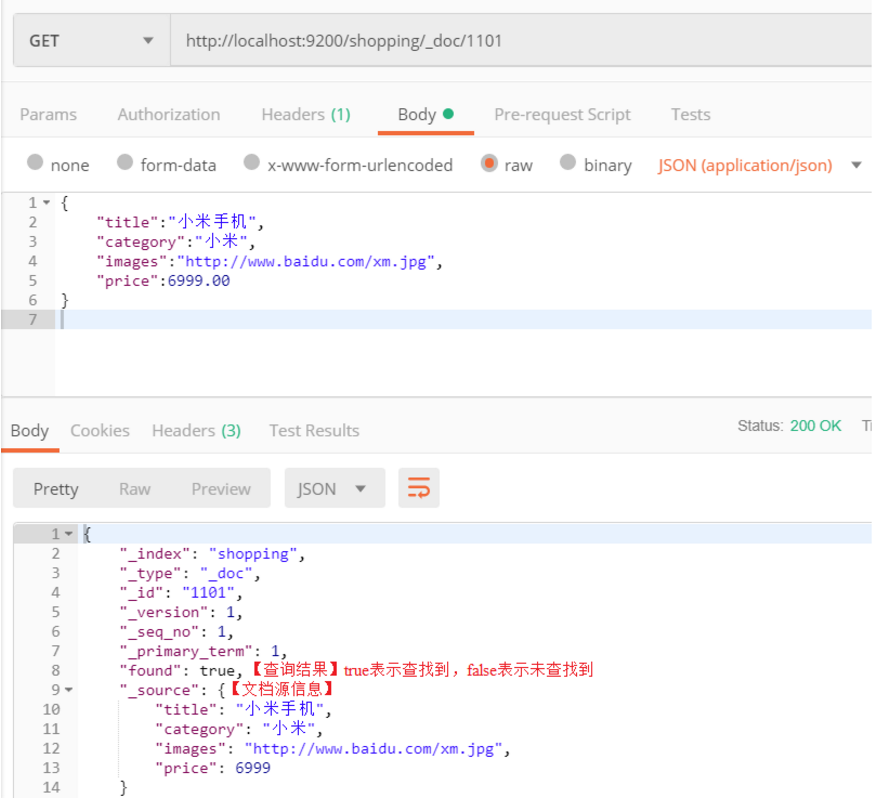
_id 仅仅是一个字符串,它与 _index 和 _type 组合时,就可以在 ES 中唯一标识一个文档。当创建一个文档,你可以自定义 _id,也可以让 ES 帮你自动生成(32 位长度)。
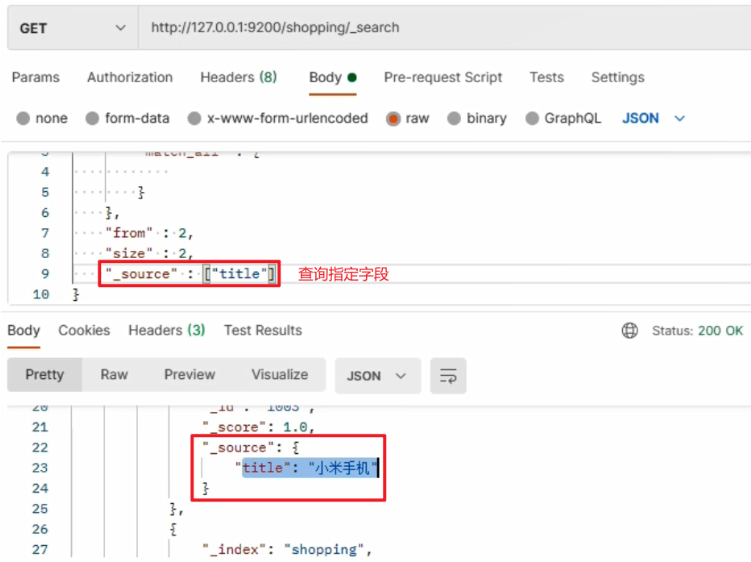
默认情况下,ES 在搜索的结果中,会把文档中保存在 _source 的所有字段都返回。如果我们只想获取其中的部分字段,我们可以添加 _source 的过滤,也可以通过:
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
如果我们只需要判断文档是否存在,而不是查询文档内容,那么可以这样:HEAD /haoke/user/1005

当然,这只表示你在查询的那一刻文档不存在,但并不表示几毫秒后依旧不存在。另一个进程在这期间可能创建新文档。
1.3.3 分页查询
和 SQL 使用 LIMIT 关键字返回只有一页的结果一样,ES 接受 from 和 size 参数:size 结果数,默认10;from 跳过开始的结果数,默认 0。
如果你想每页显示 5 个结果,页码从 1 到 3,那请求如下:
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
应该当心分页太深或者一次请求太多的结果。因为结果在返回前会被排序:一个搜索请求常常涉及多个分片!每个分片生成自己排好序的结果,它们接着需要再集中起来排序以确保整体排序正确。
【在集群系统中深度分页】为了理解为什么深度分页是有问题的,让我们假设在一个有 5 个主分片的索引中搜索。当我们请求结果的第一
页(结果 1 到 10)时,每个分片产生自己最顶端 10 个结果然后返回它们给请求节点(RequestingNode),它再排序这所有的 50 个结果以选出顶端的 10 个结果。
现在假设我们请求第 1000 页 —— 结果 10001 到 10010。工作方式都相同,不同的是每个分片都必须产生顶端的 10010 个结果。然后请求节点排序这 50050 个结果并丢弃 50040 个!
你可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于 1000 个结果的原因。
1.3.3 修改文档
在 Elasticsearch 中,文档数据是不能修改的,但是可以通过覆盖的方式进行更新;
(1)完全覆盖:和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖在 Postman 中,向 ES 服务器发请求 [POST] http://localhost:9200/shopping/_doc/1101。注意响应体的 _version 字段。

(2)修改字段:修改数据时,也可以只修改某一条数据的局部信息。
前面不是说,文档数据不能更新吗?其实是这样的:在内部,依然会查询到这个文档数据,然后进行覆盖操作,步骤如下:① 从旧文档中检索 JSON;② 修改它;③ 删除旧文档;④ 索引新文档。
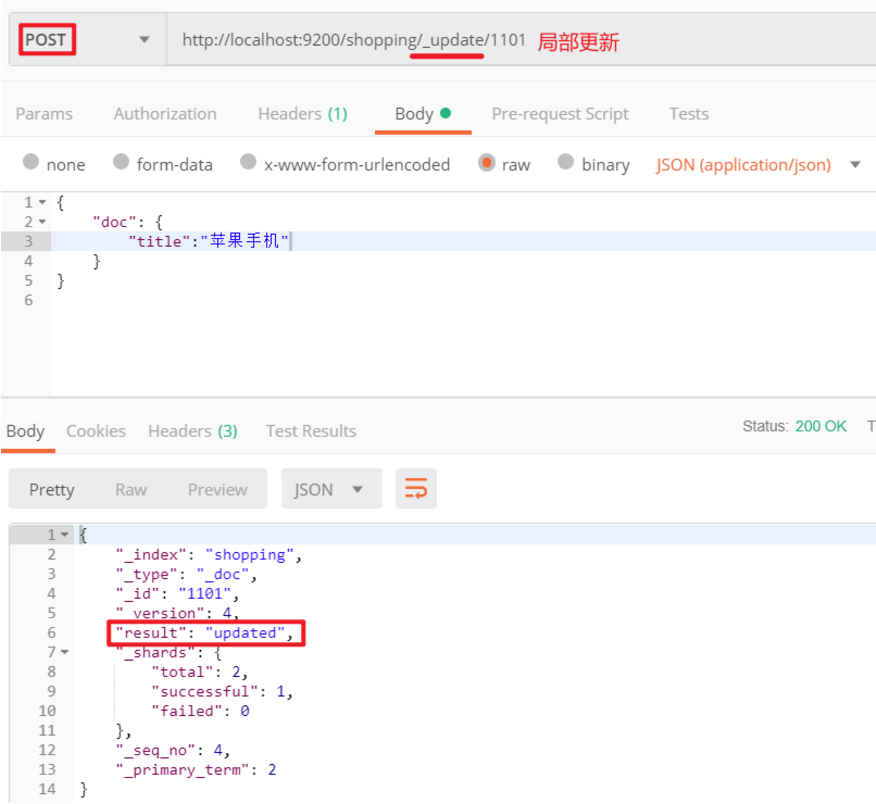
(3)脚本更新,例子如下
[POST] http://localhost:9200/student_info/_update/1
{
"script": "ctx._source.name += ctx._index"
}
1.3.4 删除文档
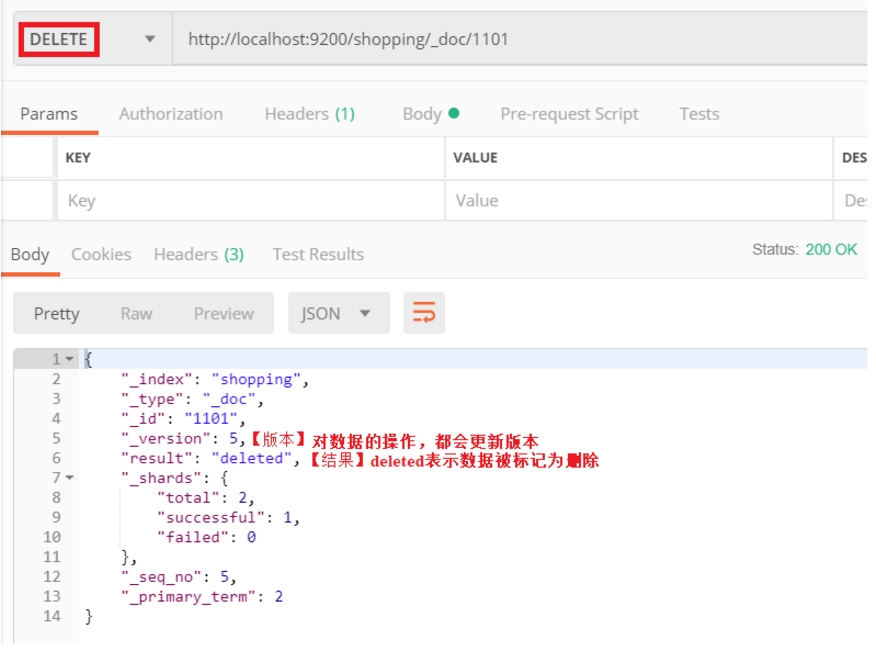
删除一个文档也不会立即从磁盘上移除,它只是被标记成已删除。Elasticsearch 将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数据进行删除。
向 ES 服务器发 POST 请求 http://127.0.0.1:9200/shopping/_delete_by_query。
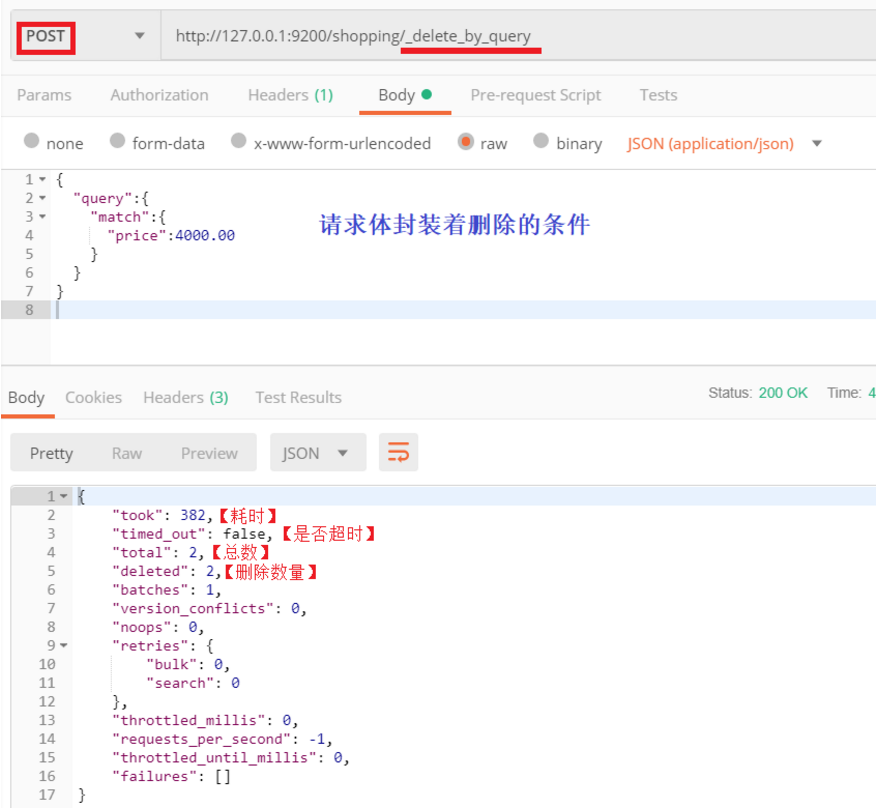
1.3.5 批量操作
有些情况下可以通过批量操作以减少网络请求。如:批量查询、批量插入数据。
(1)批量查询
POST /haoke/user/_mget
{
"ids" : [ "1001", "1003" ]
}
如果,某一条数据不存在,不影响整体响应,需要通过 found 的值进行判断是否查询到数据。

(2)持批量的插入、修改、删除操作,都是通过 _bulk 的 API 完成的
请求格式如下(别忘了最后一行的换行):
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
a. 批量插入数据
{"create":{"_index":"haoke","_type":"user","_id":2001}}
{"id":2001,"name":"name1","age": 20,"sex": "男"}
{"create":{"_index":"haoke","_type":"user","_id":2002}}
{"id":2002,"name":"name2","age": 20,"sex": "男"}
{"create":{"_index":"haoke","_type":"user","_id":2003}}
{"id":2003,"name":"name3","age": 20,"sex": "男"}
b. 批量删除(由于 Delete 没有请求体,所以 action 的下一行直接就是下一个 action)
{"delete":{"_index":"haoke","_type":"user","_id":2001}}
{"delete":{"_index":"haoke","_type":"user","_id":2002}}
{"delete":{"_index":"haoke","_type":"user","_id":2003}}
其他操作就类似了~ 按照下述流程去进行处理:
- 将 json[] 解析为 JSONArray 对象,这个时候,整个数据就会在内存中出现一份一模一样的拷贝,一份数据是 json 文本,一份数据是 JSONArray 对象;
- 解析 json[] 里的每个 json,对每个请求中的 document 进行路由;
- 为路由到同一个 shard 上的多个请求,创建一个请求数组。100 请求中有 10 个是到 P1 ... 如此类推...
- 将这个请求数组序列化,然后发送到对应的节点上去;
思考一个问题,一次请求多少性能最高?
整个批量请求需要被加载到接收我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一个最佳的 bulk 请求大小。超过这个大小,性能不再提升而且可能降低。
最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载。
幸运的是,这个最佳点(sweetSpot)还是容易找到的:试着批量索引标准的文档,随着大小的增长,当性能开始降低,说明你每个批次的大小太大了。开始的数量可以在 1000~5000 个文档之间,如果你的文档非常大,可以使用较小的批次。
通常着眼于你请求批次的物理大小是非常有用的。1K 个 1KB 的文档和 1K 个 1MB 的文档大不相同。一个好的批次最好保持在 5~15MB 大小之间。
1.3.6 重建索引
一个 Field 的设置是不能被修改的,如果要修改一个 Field,那么应该重新按照新的 mapping,建立一个 new_index,然后将数据批量查询出来,重新用 bulk api 写入 new_index 中。
批量查询的时候,建议采用 scroll api,并且采用多线程并发的方式来 reindex 数据,每次 scoll 就查询指定日期的一段数据,交给一个线程即可。
如果说旧索引的名字,是 my_index,新索引的名字是 my_index_new,终端应用已经在使用 my_index 在操作了,难道还要去停止应用,修改使用的 index 为 my_index_new,再重新启动应用吗?可用性降低。
所以说,给应用一个索引别名(alias:prod_index),这个别名是指向旧索引的,应用先用着,此时操作实际指向的是旧的 my_index。
PUT /my_index/_alias/prod_index
GET /prod_index/_search
待批量导入到 my_index_new 完成后,将别名 prod_index 切换到 my_index_new 上去,应用会直接通过 alias 使用新索引中的数据,应用程序不需要停机,高可用。
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index", "alias": "prod_index" }},
{ "add": { "index": "my_index_new", "alias": "prod_index" }}
]
}
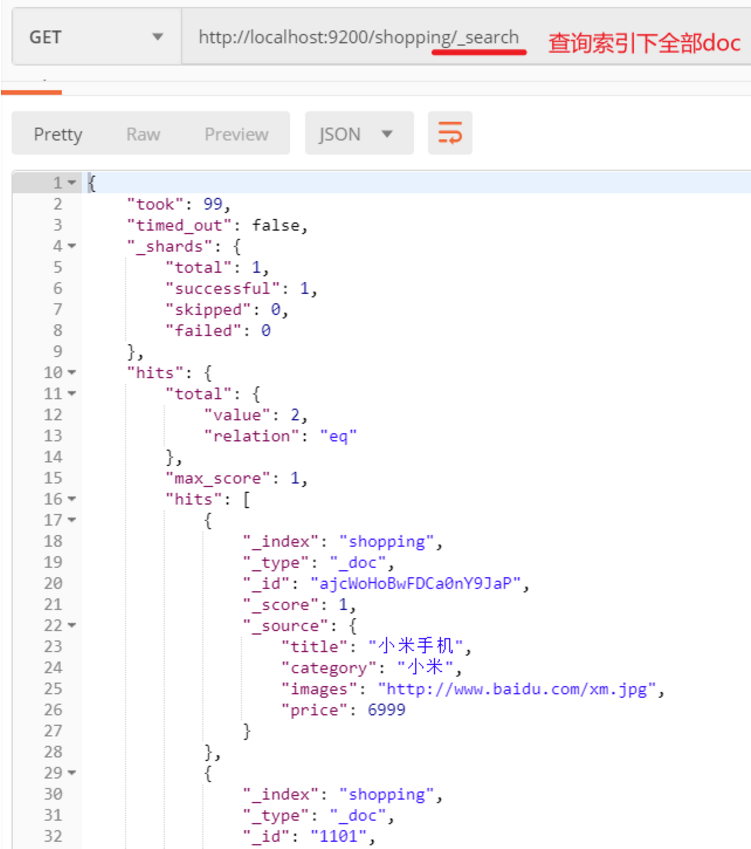
2. Search API 概述
- URI Search:在 URL 中使用查询参数
- Request Body Search:使用 ES 提供的,基于 JSON 格式的更加完备的 Query Domain Specific Language(DSL)
2.1 DSL
ElasticSearch 提供了一个完整的 Query DSL,并且是 JSON 形式的。它和 AST 比较类似,并且包含两种类型的语句:
- 叶子查询语句(Leaf Query):用于查询某个特定的字段,如 match , term 或 range 等;
- 复合查询语句 (Compound Query Clauses):用于合并其他的叶查询或复合查询语句,也就是说复合语句之间可以嵌套,用来表示一个复杂的单一查询。
记住这张图!#3开始就是依次按这张图中内容讲解。

一个查询语句究竟具有什么样的行为和得到什么结果,主要取决于它到底是处于查询上下文(Query Context) 还是过滤上下文(Filter Context)。两者有很大区别,我们来看下:
- 【QueryContext 查询上下文】这种语句在执行时既要计算文档是否匹配,还要计算文档相对于其他文档的匹配度有多高,匹配度越高,
_score分数就越高; - 【FilterContext 过滤上下文】过滤上下文中的语句在执行时只关心文档是否和查询匹配,不会计算匹配度,也就是得分。
下面来看一个例子:
GET /_search
{
"query": { (1)
"bool": { (2)
"must": [
{ "match": { "title": "Search" }}, (2)
{ "match": { "content": "Elasticsearch" }} (2)
],
"filter": [ (3)
{ "term": { "status": "published" }}, (4)
{ "range": { "publish_date": { "gte": "2015-01-01" }}} (4)
]
}
}
}
对上面的例子分析下:
- query 参数表示整个语句是处于 queryContext 中
- bool 和 match 语句被用在 queryContext 中,也就是说它们会计算每个文档的匹配度(_score)
- filter 参数则表示这个子查询处于 filterContext 中(filter 先执行)
- filter 语句中的 term 和 range 语句用在 filterContext 中,它们只起到过滤的作用,并不会计算文档的得分。
【查询和过滤的对比】
- 一条过滤语句会询问每个文档的字段值是否包含着特定值(不计算评分),而查询语句会询问每个文档的字段值与特定值的匹配程度如何。
- 一条查询语句会计算每个文档与查询语句的相关性,会给出一个相关性评分
_score,并且按照相关性对匹配到的文档进行排序。 这种评分方式非常适用于一个没有完全匹配结果的全文本搜索。 - 一个简单的文档列表,快速匹配运算并存入内存是十分方便的, 每个文档仅需要 1 个字节。这些缓存的过滤结果集与后续请求的结合使用是非常高效的。
- 查询语句不仅要查找相匹配的文档,还需要计算每个文档的相关性,所以一般来说查询语句要比过滤语句更耗时,并且查询结果也不可缓存。
换句话说,filter 适合在大范围筛选数据,而查询则适合精确匹配数据;一般应用时,应先使用过滤操作过滤数据,然后使用查询匹配数据。
【定位错误语法】
GET /book/_validate/query?explain
{
"query": {
"mach": {
"description": "查询计划"
}
}
}
2.2 无查询条件
GET /user/_doc/_search
{
"query":{ # 代表一个查询对象,里面可以有不同的查询属性
"match_all":{} # 查询类型,例如:match_all(代表查询所有)、match、term、range ...
}
}
结果示例:
{
"took": 73, # 查询花费时间(ms)
"timed_out": false, # 是否超时
"_shards": { # 分片信息
"total": 1, # > 总数
"successful": 1, # > 成功
"skipped": 0, # > 忽略
"failed": 0 # > 失败
},
"hits": { # 搜索命中结果
"total": { # 搜索条件所匹配的文档总数
"value": 9, # 总命中计数的值
"relation": "eq" # 计数规则(eq表示计数准确、gte表示计数不准确)
},
"max_score": 1, # 匹配度分值
"hits": [ # 命中结果集合
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "张三"
}
},
...
]
}
}
【补充】搜索时,请求必定跨所有主分片。如果数据量特别大,全部搜索出来需要花费大量时间,用户等不及,丢失业务。使用 timeout 机制指定每个 shard 在给定的时间内查询数据,能有几条就返回几条,返回给客户端(不常用)。
- 局部设置:GET user/_search?timeout=10ms
- 全局设置:配置文件中设置 search.default_search_timeout:100ms。默认不超时。
2.3 有查询条件
- 一个查询语句的典型结构
{ QUERY_NAME: { ARGUMENT: VALUE, ARGUMENT: VALUE, ... } } - 如果是针对某个字段,那么它的结构如下:
{ QUERY_NAME: { FIELD_NAME: { ARGUMENT: VALUE, ARGUMENT: VALUE, ... } } }
1. 叶子条件查询(单字段查询)
(1)模糊匹配
模糊匹配主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过 match 等参数来实现。
- match:模糊匹配条件内容
- prefix:前缀匹配
- regexp:通过正则表达式来匹配数据
(2)精准匹配
- term:单个条件相等
- terms:单个字段属于某个值数组内的值
- range:字段属于某个范围内的值
- exists:某个字段的值是否存在
- ids:通过 ID 批量查询
2. 组合条件查询(多条件查询)
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件。
- constant_score:不计算相关度评分
- bool:bool 查询允许我们利用“布尔逻辑”将较小的查询组合成较大的查询~
- must:各个条件都必须满足,即各条件是 and 的关系
- should:各个条件有一个满足即可,即各条件是 or 的关系
- must_not:不满足所有条件,即各条件是 not 的关系
- filter:不计算相关度评分
3. 连接查询(多文档合并查询)
- 父子文档查询:parent/child
- 嵌套文档查询:nested
2.4 聚合运算
聚合不是查询相关的记录,而是将记录作为基础,进行相应的运算得到聚合的值。
3. 模糊匹配
3.1 match
3.1.1 match
对搜索的字符串进行分词,从目标字段中的倒序索引(目标字段分词后的集合,并与文档主键形成的关联映射)中查找是否有其中某个分词,多个分词之间是 OR 的关系。
适用范围:多值的文本、可分词的文本
(1)对于分词的字段
address 字段是 text 类型,默认是会分词,我们可以使用 _analyze 这个 API 来查看地址会被分成什么的样的。
POST _analyze
{
"text":"HangZhou,ZheJiang,China"
}
【注】使用 _analyze 这个 API 默认使用的是标准英文分词,如果是“中文分词”则需要指定分词器,而以上的文本内容,根据 , 分成了三个词。
{
"tokens" : [
{
"token" : "hangzhou",
"start_offset" : 0,
"end_offset" : 8,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "zhejiang",
"start_offset" : 9,
"end_offset" : 17,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "china",
"start_offset" : 18,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
因此只要查询的条件中,将条件的内容再进行分词,与目标字段内容的分词词组进行对比~
GET user/_doc/_search
{
"_source":["user_id","address"],
"query":{
"match":{
"address":"zhejiang"
}
}
}
得出以下的结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.2876821,
"_source" : {
"address" : "NingBo,ZheJiang,China",
"user_id" : 5
}
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"address" : "HangZhou,ZheJiang,China",
"user_id" : 1
}
}
]
}
}
(2)对于多值的字段
本例中 tags 字段是一个多值的字段
GET user/_doc/_search
{
"query":{
"match":{
"tags":"运"
}
}
}
搜索结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.9227539,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9227539,
"_source" : {
"user_id" : 2,
"nickname" : "tree6x7",
"password" : "ljq1101",
"status" : 0,
"tags" : [
"活泼",
"运动型"
],
"address" : "ShiYan,HuBei,China",
"create_time" : 1554886682618
}
}
]
}
}
【注】因为我们在建立 mapping 时,没有指定分词器,默认的分词器会把中文按‘字’分割。
(3)match 的复杂用法
| 参数 | 含义 |
|---|---|
| query | 指定匹配的值 |
| operator(and/or) | 匹配条件类型(都要匹配 / 有一个匹配即可) |
| minmum_should_match | 指定最小匹配的数量 |
A. operator 为 or 的情况(默认,故可省)是只要包含其中一个条件即可
GET user/_doc/_search
{
"_source":["user_id", "tags"],
"query":{
"match":{
"tags":{
"query":"运,艺"
}
}
}
}
- 条件中的 "运, 艺" 会被分词为 ["运","艺"] 这样的集合;
- tags 字段会根据默认分词,形成一个词组集合,如 ["活泼","运动型"] 会被分词为 ["活","动","运","动","型"] 这样的词组集合;
- 因此只需要比较「条件中的词组集合」和「目标字段中的词组集合」即可,即 tags 字段中只要包含 "运" 或者 "艺" 即可。
B. 通过 operator 中的 and 控制匹配结果
GET user/_doc/_search
{
"_source":["user_id", "tags"],
"query":{
"match":{
"tags":{
"query":"天,艺",
"operator":"and"
}
}
}
}
- 条件中的“天,艺”会被分词为 ["天", "艺"] 这样的集合;
- tags 字段会根据默认分词形成一个词组集合;
- 因为 operator 是 and,所有 tags 的词组集合必须包含条件中两个词组才能满足条件!
C. 通过 minimum_shoud_match 控制匹配结果
GET user/_doc/_search
{
"_source":["user_id", "tags"],
"query":{
"match":{
"tags":{
"query":"天,艺,运",
"minimum_should_match":2
}
}
}
}
- 条件中的“天,艺,运”会被分词为 ["天", "艺", "运"] 这样的集合;
- tags 字段会根据默认分词形成一个词组集合;
- 因此只要 tags 字段的分词后的词组至少包含 ["天", "艺", "运"] 这个集合其中两个词就可满足条件。
3.1.2 match_pharse
完全包含搜索的内容!
如下示例查找必须包含”艺术”这个词,与 match 区别是比较大的(目标的字段必须完全包含搜索的词语,而不是分词后的匹配结果)。
GET user/_doc/_search
{
"_source":["user_id","tags"],
"query":{
"match_phrase":{
"tags":"艺术"
}
}
}
下面与 match 比较一下(match 可以查找到 tags 包含“艺”和“术”的记录):
GET user/_doc/_search
{
"_source":["user_id","tags"],
"query":{
"match":{
"tags":{
"query":"艺术",
"operator":"and"
}
}
}
}
3.1.3 multi_match
可以在多个字段中查询,用于搜索多个字段匹配同一个内容(内容会被分词)。
【参数】
- query:匹配的值
- fields:查找的字段范围
- type:过滤筛选的类型
- best_fields:只要匹配任意一个字段即可,使用最匹配的那个字段的相关度评分
- most_fields:只要匹配做任意一个字段,但会将匹配度的得分进行组合
- corss_fields:使用相同的分词器,只要有一个字段匹配即可
- phrase:最匹配的字段要完全匹配搜索的内容
- phrase_prefix:最匹配的字段要完全匹配搜索的内容(包含搜索的的内容)
- operator:匹配的字段关系
- and:所有字段都匹配
- or:只要一个字段匹配即可
[GET] http://localhost:9200/user/_search
{
"query": {
"multi_match": {
"query": "刘",
"fields": ["name"]
}
}
}
查询结果:
{
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.9763691,
"hits": [
{
"_index": "user",
"_type": "_doc",
"_id": "1003",
"_score": 1.9763691, <------
"_source": {
"name": "刘源",
"sex": "",
"age": 33
}
},
{
"_index": "user",
"_type": "_doc",
"_id": "1019",
"_score": 1.5485401, <------
"_source": {
"name": "刘佳琦",
"sex": "",
"age": 29
}
}
]
}
}
从用户 index 的 email、nickname 字段中查找“shixinke”这个关键词。
3.2 prefix
匹配 email 字段以“tree”为前缀的记录:
GET user/_doc/_search
{
"_source":["user_id","email"],
"query":{
"prefix":{
"email":"tree"
}
}
}
3.3 regexp
使用正则表达式来搜索指定的内容。
3.4 fuzzy
返回包含与搜索字词相似的分词的文档。
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
- 更改字符(box → fox)
- 删除字符(black → lack)
- 插入字符(sic → sick)
- 转置两个相邻字符(act → cat)
为了找到相似的术语,fuzzy 查询会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展。然后查询返回每个扩展的完全匹配。通过 fuzziness 修改编辑距离。一般使用默认值 AUTO,根据术语的长度生成编辑距离。
{
"query": {
"fuzzy": {
"city": {
"value": "Shawmut"
}
}
}
}

3.5 wildcard
通配符查询,Can only use wildcard queries on keyword and text fields
# 字段值为空字符串
{
"query": {
"bool": {
"must_not": {
"wildcard": {
"name": {
"value": "*"
}
}
}
}
}
}
# 字段值不为空字符串的文档
{
"query": {
"wildcard": {
"name": {
"value": "*"
}
}
}
}
# http://localhost:9200/user/_mapping
{
"user": {
"mappings": {
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
比如我想查 刘佳琦 这个名字的时候,我输入 刘* 或者 *琦 的时候都能查出来但是输入 刘佳* 或者直接 刘佳琦 的时候却查不出来,原因是在使用 wildcard 进行模糊查询 text 类型的字段时,必须为 text 字段分词后中的某一个才行,而“刘佳琦”这三个字很可能就被分词成了三个字,但却没有连起来的分词,所以查的时候 刘* / *佳* / *琦 可以,但 刘佳* / 刘佳琦 不行的原因。
解决办法:在使用 wildcard 模糊查询的时候如果不想对字段内容进行分词查询的话可以将内容变成 keyword 模式去查询,这样我们进行查询的时候就不会进行分词查询了。
{
"query": {
"wildcard": {
"name.keyword": {
"value": "刘佳*" / "刘佳琦"
}
}
}
}
4. 精准匹配
4.1 条件与目标字段相等
4.1.1 term
查找目标字段与条件相等的记录,不对查询条件进行分词,语法:
term:{"fieldName":"value"}。
查找居住城市为 Shawmut(写入时的值)的用户:
GET user/_doc/_search
# 注意我给的 value 是小写才查到的,把 'S' 大写就查不到了
{
"query": {
"term": {
"city": "shawmut"
}
}
}
# 如下也能搜到,但此时你换成's'可就又搜不到了
{
"query": {
"term": {
"city.keyword": "Shawmut"
}
}
}
# 查看 Mapping
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
# 查看下分词处理
[GET] http://localhost:9200/_analyze
{
"text" : "Shawmut"
}
return:{
"tokens": [{
"token": "shawmut",
"start_offset": 0,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 0
}]
}
- Es 中默认使用的分词器为“标准分词器”,标准分词器对于英文单词分词,对于中文按字分词;
- 通过使用 term 查询可知,在 Es 的 Mapping Type 中 keyword、date、Interger、long、double、boolean、IP 这些类型不分词,只有 text 类型分词;
- 字符串类型就算写入 Es 是大写,但建立索引的时候会自动进行处理为全小写(39 行);
- 【Mapping】字符串将默认被同时映射成 text 和 keyword 类型,为 city 属性创建动态映射(Dynamic Mappings),基于这个映射你既可以在 city 字段上进行全文搜索,也可以通过 city.keyword 字段实现关键词搜索及数据聚合。
4.1.2 terms
一个字段在某个值的范围内或通过其他 index 的某个字段的值来作为条件。
(1)简单用法:查找状态 status = 1或2 的记录 // 这里有点类似于 SQL 中的 IN
GET user/_doc/_search
{
"_source":["user_id","status"],
"query":{
"terms":{
"status":[0,1]
}
}
}
(2)复杂用法:在另外一个文档中的某个字段的值作为查询条件来查询。
【参数】
- index:指定要查询的 index
- type:指定要查询的 type (7.x 以后不再使用,因为只有
_doc一种类型) - id:指定要查询的 id
- path:查询的字段
【示例】从 info 这个 index 中查询 id 为1的这条记录,并取出这条记录的 user_id 这个字段的值作为 user 这个 index 的查询条件(类似于SQL中的子查询)。
GET user/_doc/_search
{
"_source":["user_id","status"],
"query":{
"terms":{
"user_id":{
"index":"info",
"type":"_doc",
"id":1,
"path":"user_id"
}
}
}
}
4.2 范围条件
4.2.1 range
在一定范围内查找符合条件的记录。
【参数】
- lt:小于指定的值
- lte:小于等于指定的值
- gt:大于指定的值
- gte:大于等于指定的值
- format:对于日期类型的字段可以设置格式
- time_zone:参于日期类型的字段可以设置时区
【示例】
GET user/_doc/_search
{
"_source":["user_id","create_time"],
"query":{
"range":{
"create_time":{
"gte":"2019-04-10 00:00:00",
"lte":"2019-04-10 07:59:59",
"format":"yyyy-MM-dd HH:mm:ss"
}
}
}
}
4.2.2 ids
查找指定 id 数组中的记录(和 SQL 中的 id IN 是类似的)。
- type:指定 type(7.x 移除)
- values:id 数组的值
【示例】
GET user/_doc/_search
{
"_source":["user_id","nickname"],
"query":{
"ids":{
"values":[1,2,3]
}
}
}
4.3 存在(exists)
查找某个字段值是否存在。
不存在的情况:① 字段不存在;② 字段的值为 null、空字符串、[] 或 [null]。
【参数】
field:检查的字段
【示例】
GET user/_doc/_search
{
"_source":["user_id","nickname"],
"query":{
"exists":{
"field":"update_time"
}
}
}
5. 组合查询
组合条件查询是基于叶子查询条件,将叶子条件作为子条件,形成一个多字段多条件的组合条件。
5.1 bool
bool把各种其它查询通过must(必须 )、must_not(必须不)、should(应该)的方式进行组合,最终形成一个 bool 条件树~
〈bool 过滤器〉将多个小查询组合成一个大查询,查询语法有如下特点:
- 子查询可以任意顺序出现;
- 可以嵌套多个查询,包括 bool 查询也可以;
- 如果 bool 查询中没有 must 条件,should 中必须至少满足 1 条才会返回结果。
〈bool 过滤器〉包括如下操作符,这 4 个都是数组,数组里面是对应的判断条件:
- must:必须匹配(各子条件是 AND 关系);贡献算分
- should:选择性匹配,至少满足一条(各子条件是 OR 关系);贡献算分
- must_not:过滤子句,必须不能匹配(NOT);不贡献算分
- filter:过滤子句,必须匹配;不贡献算分
【注】must/filter/shoud/must_not 等的子条件是通过 term/terms/range/ids/exists/match 等叶子条件为参数的。当只有一个搜索条件时,must 等对应的是一个对象;当是多个条件时,对应的是一个数组!

5.1.1 must
【示例】通过 must 来查询状态为 1 的用户列表
GET user/_doc/_search
{
"_source":["user_id", "status"],
"query":{
"bool":{
"must":{
"term":{
"status":1
}
}
}
}
}
5.1.2 must_not
用于排除某个条件的记录
【示例】查询状态不为 0 的用户列表
GET user/_doc/_search
{
"_source": [
"user_id",
"status"
],
"query": {
"bool":{
"must_not":{
"term":{
"status":0
}
}
}
}
}
5.1.3 should
当多个条件之间是 OR 的关系时,使用 should。
【示例】查询 address 中包含“zhejiang”或 nickname 为“shixinke”的记录。
GET user/_doc/_search
{
"_source": [
"user_id",
"nickname",
"address"
],
"query": {
"bool": {
"should": [
{
"match": {
"address": "zhejiang"
}
},
{
"term":{
"nickname":"shixinke"
}
}
]
}
}
}
5.1.4 filter
filter 与其他子查询条件不同,它不计算
_score即相关度评分,效率更高 // 查询和过滤的对比详见#2.1
GET user/_doc/_search
{
"_source":["user_id", "status"],
"query":{
"bool":{
"filter":{
"term":{
"status":1
}
}
}
}
}
5.2 constant_score
给每条记录以一个固定的评分,即不计算相关度评分,所以 constant_score 只支持 filter 上下文~
-- 只想筛出满足条件的数据,不关心评分
GET user/_doc/_search
{
"_source": [
"user_id",
"status"
],
"query": {
"constant_score":{
"filter":{
"term":{
"status":1
}
}
}
}
}
5.3 dis_max
即分离最大化查询(Disjunction Max Query) 。分离(Disjunction)的意思是“或or”,这与可以把结合(Conjunction)理解成“与and”相对应。分离最大化查询指的是: 将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回。
【语法】"dis_max":{"queries":[...]}
【示例】查询 status 为 1 或 address 中包含 zhejiang 的记录,有的记录匹配 status=1,有的记录匹配 addres 包含 zhejiang,这时取最匹配的那个字段的分数作为所有记录的评论。
GET user/_doc/_search
{
"_source": [
"user_id",
"address"
],
"query": {
"dis_max": {
"queries": [
{
"term": {
"status": 1
}
},
{
"match":{
"address":"zhejiang"
}
}
]
}
}
}
6. 连接查询
6.1 父子文档查询
// TODO
6.2 嵌套文档查询
// TODO
7. 其他操作
7.1 排序
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式:desc 降序,asc 升序。
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"_score":{
"order": "desc"
}
}
]
}
7.2 高亮
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为“高亮”。
ES 可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。
在使用 match 查询的同时,加上一个 highlight 属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
- title:这里声明 title 字段需要高亮,后面可以为这个字段设置特有配置,也可以空
【示例】
{
"query": {
"match": {
"name": "zhangsan"
}
},
"highlight": {
"fields": {
"name": {}
}
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"require_field_match": false # match.field 匹配才内容高亮,其他 field 匹配上了不管
}
}
·················································
{
"took": 97,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": 0.05129329,
"hits": [
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_score": 0.05129329,
"_source": {
"name": "张三"
},
"highlight": {
"name": [
"<font color='red'>张</font>三"
]
}
},
...
]
}
}
7.3 分页
- from:当前页的起始索引,默认从 0 开始 // from = (pageNum - 1) * size
- size:每页显示多少条
应该当心“分页太深”或者“一次请求太多的结果”。结果在返回前会被排序。但是一个搜索请求常常涉及多个分片。每个分片生成自己排好序的结果,它们接着需要集中起来排序以确保整体排序正确。
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
【在集群系统中深度分页】
为了理解为什么深度分页是有问题的,让我们假设在一个有 5 个主分片的索引中搜索。当我们请求结果的第 1 页(结果 1 到 10)时,每个分片产生自己最顶端 10 个结果然后返回它们给请求节点(Requesting Node),它再排序这所有的 50 个结果以选出顶端的 10 个结果。
现在假设我们请求第 1000 页 —— 结果 10001 到 10010。工作方式都相同,不同的是每个分片都必须产生顶端的 10010 个结果。然后请求节点排序这 50050 个结果并丢弃 50040 个!
你可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于 1000 个结果的原因。
8. 聚合运算
上面都是在单纯地讲如何查 Doc,现在来说下如何对 Doc 进行统计分析。Aggregations 的部分特性类似于类似与关系型数据库中的 GROUP BY、AVG、SUM 等函数。但 AggregationsAPI 还提供了更加复杂的统计分析接口。
两个核心概念:
- 桶(Buckets):符合条件的文档的集合,相当于 SQL 中的 GROUP BY。比如,在 users 表中,按“地区”聚合,一个人将被分到“北京桶”或“上海桶”或其他桶里;按“性别”聚合,一个人将被分到“男桶”或“女桶”。
- 指标(Metrics):基于 Buckets 的基础上进行统计分析,相当于 SQL 中的 COUNT、MAX、MIN、AVG、SUM 等。比如,按“地区”聚合,计算每个地区的人数,平均年龄等。
对照一条 SQL 来加深理解:SELECT COUNT(color) FROM table GROUP BY color,其中 GROUP BY 相当于做分桶的工作,COUNT 为统计指标。
【聚合缓存】Es 中经常使用到的聚合结果集可以被缓存起来,以便更快速的系统响应。这些缓存的结果集和你略过缓存直接查询的结果是一样的。因为,第一次聚合的条件与结果缓存起来后,Es 会判断你后续使用的聚合条件,如果聚合条件不变,并且检索的数据块未增更新,Es 会自动返回缓存的结果。注意!聚合结果的缓存只针对 size=0 的请求,还有在聚合请求中使用了动态参数的(比如 Date Range 中的 now),Es 同样不会缓存结果,因为聚合条件是动态的,即使缓存了结果也没用了。
8.1 简单聚合
max、min、sum、avg、cardinality(求基数)
【聚合语法】
"aggs": {
"AGGS_NAME 本次聚合的名字,方便展示在结果集中": {
"AGG_TYPE 聚合的类型": {
"FIELD_NAME": "xxx", ...
},
"aggs": {
...
}
}
}
·························· example ··························
{
"aggs":{
"max_age":{
"max":{
"field":"age"
}
}
}
}
【嵌套聚合】按照指定的价格范围区间进行分组,然后在每组内再按照 tag 进行分组,最后再计算每组的平均价格。
GET /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 40
},
{
"from": 40,
"to": 60
},
{
"from": 60,
"to": 80
}
]
},
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
【排序:order】
- 最后返回结果的排序方式默认是按照 doc_count 来的:
{ "aggs" : { "genders" : { "terms" : { "field" : "gender", "order" : { "_count" : "asc" } } } } } - 也可以按照字典方式排序:
{ "aggs" : { "genders" : { "terms" : { "field" : "gender", "order" : { "_term" : "asc" } } } } } - 也可以通过 order 指定一个单值聚合来排序:
{ "aggs" : { "genders" : { "terms" : { "field" : "gender", "order" : { "avg_balance" : "desc" } # 可以直接调用子聚合 }, "aggs" : { "avg_balance" : { "avg" : { "field" : "balance" } } } } } } - 同时也支持多值聚合,不过要指定使用的多值字段:
{ "aggs" : { "genders" : { "terms" : { "field" : "gender", "order" : { "balance_stats.avg" : "desc" } }, "aggs" : { "balance_stats" : { "stats" : { "field" : "balance" } } } } } }
8.2 多值聚合
8.2.1 percentiles 百分比

8.2.2 stats 统计
{
"size": 0,
"aggs": {
"balance_stats": {
"stats": {
"field": "balance"
}
}
}
}

8.2.3 terms 聚合
例1:搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情。
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"age_count": {
"terms": {
"field": "age"
}
},
"age_avg": {
"avg": {
"field": "age"
}
}
},
"size": 0
}

例2:按照年龄聚合,并且请求各年龄段的这些人的平均薪资。
{
"aggs": {
"age_count": {
"terms": {
"field": "age"
}, // 按照 age_count 的聚合结果再聚合,看清楚这个 aggs 是写在哪的
"aggs": {
"avgSalary_Age": {
"avg": {
"field": "balance"
}
}
}
}
}
}

例3:查出所有年龄分布和各年龄的总体平均薪资,以及各年龄段中 M 的平均薪资和 F 的平均薪资。
{
"aggs": {
"age_count": {
"terms": {
"field": "age"
},
"aggs": {
"gender_count": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"avg_balance_of_gender": {
"avg": {
"field": "balance"
}
}
}
},
"avgSalary_EveryAge": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}

【补充:使用 terms 聚合,结果可能带有一定的偏差与错误性】
比如,我们想要获取 name 字段中出现频率最高的前 5 个。此时,客户端向 ES 发送聚合请求,主节点接收到请求后,会向每个独立的分片发送该请求。分片独立的计算自己分片上的前 5 个 name,然后返回。当所有的分片结果都返回后,在主节点进行结果的合并,再求出频率最高的前 5 个,返回给客户端。
这样就会造成一定的误差,比如最后返回的前 5 个中,有一个叫 A 的,有 50 个 Doc;B 有 49 个。 但是由于每个分片独立的保存信息,信息的分布也是不确定的。 有可能第一个分片中 B 的信息有 2 个,但是没有排到前 5,所以没有在最后合并的结果中出现。 这就导致 B 的总数少计算了 2,本来可能排到第一位,却排到了 A 的后面。
为了改善上面的问题,就可以使用 size 和 shard_size 参数:
- size 参数规定了最后返回的 term 个数(默认是 10 个);
- shard_size 参数规定了每个分片上返回的个数;
- 若 shard_size 小于 size,那么分片也会按照 size 指定的个数计算。
通过这两个参数,如果我们想要返回前 5 个:size=5, shard_size>5,这样每个分片返回的词条信息就会增多,相应的误差几率也会减小。
8.3 TV exmaple
(0)前置操作
PUT /tvs
PUT /tvs/_doc/_mapping
{
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"sold_date": {
"type": "date"
}
}
}
GET /tvs/_mapping
POST /tvs/_doc/_bulk
{ "index": {}}
{ "price" : 1000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-10-28" }
{ "index": {}}
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-11-05" }
{ "index": {}}
{ "price" : 3000, "color" : "绿色", "brand" : "小米", "sold_date" : "2019-05-18" }
{ "index": {}}
{ "price" : 1500, "color" : "蓝色", "brand" : "TCL", "sold_date" : "2019-07-02" }
{ "index": {}}
{ "price" : 1200, "color" : "绿色", "brand" : "TCL", "sold_date" : "2019-08-19" }
{ "index": {}}
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-11-05" }
{ "index": {}}
{ "price" : 8000, "color" : "红色", "brand" : "三星", "sold_date" : "2020-01-01" }
{ "index": {}}
{ "price" : 2500, "color" : "蓝色", "brand" : "小米", "sold_date" : "2020-02-12" }
(1)统计哪种颜色的电视销量最高 // 默认按 doc_count 降序排序
查询:
GET tvs/_doc/_search
{
"size": 0, # 只获取聚合结果,而不要执行聚合的原始数据
"aggs": { # 固定语法,要对一份数据执行分组聚合操作
"distinct_by_color": { # 就是对每个 aggs 都要起一个名字
"terms": { # 如何划分桶,这里是根据字段的值进行分组
"field": "color" # 根据指定的字段的值进行分组
}
}
}
}
结果:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 9,
"max_score": 0,
"hits": [] # 指定了 size 是 0 所以 hits.hits 就是空的
},
"aggregations": { # 聚合结果
"distinct_by_color": { # 指定的某个聚合的名称
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ # 根据指定的 field 划分出的 buckets
{
"key": "红色", # 每个 bucket 对应的值
"doc_count": 4 # 这个 bucket 分组内有多少个数据
},
{
"key": "绿色",
"doc_count": 2
},
{
"key": "蓝色",
"doc_count": 2
}
]
}
}
}
(2)统计每种颜色电视平均价格
GET tvs/_doc/_search
{
"size": 0,
"aggs": { # first aggs for bucket
"distinct_by_color": {
"terms": {
"field": "color"
},
"aggs": { # second aggs for metric
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
(3)每个颜色下,平均价格及每个颜色下,每个品牌的平均价格
GET tvs/_doc/_search
{
"size":0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price_of_color": {
"avg": {
"field": "price"
}
},
"second_group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"avg_price_of_brand": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
(4)求出每个颜色的销售数量、平均/最大/最小价格、价格总和
GET tvs/_doc/_search
{
"size":0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": { "avg": { "field": "price" } },
"min_price" : { "min": { "field": "price"} },
"max_price" : { "max": { "field": "price"} },
"sum_price" : { "sum": { "field": "price" } }
}
}
}
}
(5)求出每 2k 一个区间,各区间的销售总额
GET tvs/_doc/_search
{
"size":0,
"aggs": {
"range_by_2k": {
"histogram": {
"field": "price",
"interval": 2000
},
"aggs": {
"range_sum": {
"sum": {
"field": "price"
}
}
}
}
}
}
等宽度的划分范围要用 histogram,也是进行 bucket 分组操作,接收一个 field 并按照 interval 对这个 field 的值进行区间划分(如 interval=2000 则划分范围为 02000,20004000,40006000,60008000,8000~10000)。
(6)按月展示销售数量,没有售出的月份显示为 0,返回指定日期范围内的月销售数据
GET tvs/_doc/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2019-01-01",
"max" : "2020-12-31"
}
}
}
}
}
date_histogram 按照我们指定的某个 date 类型的日期 field 以及日期 interval,按照一定的日期间隔去划分 bucket。
- min_doc_count:即使某个日期 interval 如 2019-01-01~2019-01-31 中一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的;
- extended_bounds { min,max }:划分 bucket 的时候,会限定在这个起始日期和截止日期内。
(7)统计每季度每个品牌的销售额及每个季度的销售总额
GET tvs/_doc/_search
{
"size": 0,
"aggs": {
"group_by_sold_season": {
"date_histogram": {
"field": "sold_date",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2019-01-01",
"max": "2020-12-31"
}
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
},
"total_sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
(8)搜索与聚合结合,查询某个品牌按颜色销量
GET tvs/_doc/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
}
}
}
}
(9)Global Bucket:单个品牌均价与所有品牌均价销量对比
GET tvs/_doc/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"single_group_avg_price": {
"avg": {
"field": "price"
}
},
"all": {
"global": {},
"aggs": {
"avg_of_all_brand": {
"avg": {
"field": "price"
}
}
}
}
}
}
global 一加,就不受上面 query 影响了,面向所有数据执行聚合~
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0,
"hits": []
},
"aggregations": {
"all": {
"doc_count": 9,
"avg_of_all_brand": {
"value": 2650
}
},
"single_group_avg_price": {
"value": 2750
}
}
}
(10)过滤+聚合:统计价格大于 1200 的电视平均价格
GET tvs/_doc/_search
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 1200
}
}
}
}
},
"aggs": {
"matric_by_price": {
"avg": {
"field": "price"
}
}
}
}
(11)Bucket Filter:统计某品牌最近半年/一年的平均售价
GET tvs/_doc/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"recent_90d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-90d"
}
}
},
"aggs": {
"recent_90d_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"recent_180d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-180d"
}
}
},
"aggs": {
"recent_180d_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
aggs.filter 针对聚合去做的。如果放 query 里面的 filter 是全局的,会对所有的数据都有影响。比如说你要统计长虹电视(global filter)最近 1/3/6 个月(bucket filter)的平均值(matric)。
(12)按每种颜色的平均销售额降序排序
GET tvs/_doc/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_price": "desc" # 相当于 SQL 子表数据字段可以立刻使用
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
(13)按每种颜色的每种品牌平均销售额降序排序
GET tvs/_doc/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_sale": "desc"
}
},
"aggs": {
"avg_sale": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
9. 其他搜索
9.1 Multi Index Search
【场景】生产环境 log 索引可以按照日期分开,如 log_to_es_20220104、log_to_es_20220105、log_to_es_20220106 ...
/_search 所有索引下的所有数据都搜索出来
/index1/_search 指定一个 index,搜索其下所有的数据
/index1,index2/_search 同时搜索两个 index 下的数据
/index*/_search 按照通配符去匹配多个索引
9.2 Deep Paging Search
三个分片,每个分片上 1 亿数据,现在要看 pageNum=999&pageSize=10 上的数据内容。
每个分片按评分倒序返回前 1w 条(id, _score)到协调节点,协调节点将这 3w 条排序,排序之后返回第 9990 ~ 10000 条记录。
根据相关度评分倒排序,所以分页过深,协调节点会将大量数据聚合分析。引发的性能问题:
- 消耗网络带宽,因为所搜过深的话,各 shard 要把数据传递给 Coordinate Node,这个过程是有大量数据传递的,消耗网络;
- 消耗内存,各 shard 要把所有数据都传送给 Coordinate Node,这个传递回来的数据是被 Coordinate Node 保存在内存中的,这样会大量消耗内存;
- 消耗 CPU,Coordinate Node 要把传回来的数据进行排序,这个排序过程很消耗 CPU。所以,鉴于 Deep Paging 的性能问题,应尽量减少使用。
9.3 Scroll Batch Search
【场景】下载某一个索引中 1 亿条数据到文件或是数据库。不能一下全查出来,系统内存溢出。
【解决】使用 Scroll 滚动搜索技术,一批一批查询。Scroll 搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的。
(1)每次发送 Scroll 请求,我们还需要指定一个 Scroll 参数和一个“时间窗口”,每次搜索请求只要在这个“时间窗口”内能完成就可以了;
GET /book/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 3
}
(2)响应结果
{
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAMOkWTURBNDUtcjZTVUdKMFp5cXloVElOQQ==",
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
...
]
}
}
(3)获得的结果会有一个 scroll_id,下一次再发送 Scroll 请求的时候,必须带上这个 scroll_id:
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAMOkWTURBNDUtcjZTVUdKMFp5cXloVElOQQ=="
}
(4)Java 代码
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
public void syncEsData() {
Client esClient = elasticsearchTemplate.getClient();
log.info("syncEsData: 开始同步 Es 数据");
try {
SearchResponse response = esClient.prepareSearch(vehicleIndex)
.setScroll(new TimeValue(300000))
.setQuery(QueryBuilders.matchAllQuery())
.setFrom(0).setSize(maxInsertCount)
.execute().actionGet();
SearchHits vehicleHistory = response.getHits();
long hitSize = vehicleHistory.totalHits;
List<BasicVehicleBean> list = new ArrayList<>(maxInsertCount);
while (hitSize > 0) {
for (SearchHit vehicleHistoryHit : vehicleHistory) {
BasicVehicleBean bean = new BasicVehicleBean();
JSONObject vehicleObject = JSON.parseObject(vehicleHistoryHit.getSourceAsString());
// ...
list.add(bean);
}
dataCollectionDao.batchInsertBasicVehicle(list);
list.clear();
String scrollId = response.getScrollId();
response = esClient.prepareSearchScroll(scrollId)
.setScroll(new TimeValue(300000))
.execute()
.actionGet();
hitSize = response.getHits().getHits().length;
}
} catch (Exception e) {
log.error("syncEsData throw Ex: ", e);
}
log.info("syncEsData: 同步 Es 数据结束");
}
(5)与分页区别:Paging 给用户看的;Scroll 是系统内部操作,如下载批量数据、数据转移、零停机改变索引映射。