1. itertools迭代器函数
itertools包括一组用于处理序列数据集的函数。这个模块提供的函数是受函数式编程语言(如Clojure、Haskell、APL和SML)中类似特性的启发。其目的是要能快速处理,以及要高效地使用内存,而且可以联结在一起表述更复杂的基于迭代的算法。
与使用列表的代码相比,基于迭代器的代码可以提供更好的内存消费特性。在真正需要数据之前,并不从迭代器生成数据,由于这个原因,不需要把所有数据都同时存储在内存中。这种“懒”处理模式可以减少交换以及大数据集的其他副作用,从而改善性能。
除了itertools中定义的函数,这一节中的例子还会利用一些内置函数完成迭代。
1.1 合并和分解迭代器
chain()函数取多个迭代器作为参数,最后返回一个迭代器,它会生成所有输入迭代器的内容,就好像这些内容来自一个迭代器一样。
from itertools import * for i in chain([1, 2, 3], ['a', 'b', 'c']): print(i, end=' ') print()
利用chain(),可以轻松地处理多个序列而不必构造一个很大的列表。

如果不能提前知道所有要结合的迭代器(可迭代对象),或者如果需要采用懒方法计算,那么可以使用chain.from_iterable()来构造这个链。
from itertools import * def make_iterables_to_chain(): yield [1, 2, 3] yield ['a', 'b', 'c'] for i in chain.from_iterable(make_iterables_to_chain()): print(i, end=' ') print()

内置函数zip()返回一个迭代器,它会把多个迭代器的元素结合到一个元组中。
for i in zip([1, 2, 3], ['a', 'b', 'c']): print(i)
与这个模块中的其他函数一样,返回值是一个可迭代对象,会一次生成一个值。

第一次输入迭代器处理完时zip()就会停止。要处理所有输入(即使迭代器生成的值个数不同),则要使用zip_longest()。
from itertools import * r1 = range(3) r2 = range(2) print('zip stops early:') print(list(zip(r1, r2))) r1 = range(3) r2 = range(2) print(' zip_longest processes all of the values:') print(list(zip_longest(r1, r2)))
默认地,zip_longest()会把所有缺少的值替换为None。可以借助fillvalue参数来使用一个不同的替换值。

islice()函数返回一个迭代器,它按索引从输入迭代器返回所选择的元素。
from itertools import * print('Stop at 5:') for i in islice(range(100), 5): print(i, end=' ') print(' ') print('Start at 5, Stop at 10:') for i in islice(range(100), 5, 10): print(i, end=' ') print(' ') print('By tens to 100:') for i in islice(range(100), 0, 100, 10): print(i, end=' ') print(' ')
islice()与列表的slice操作符参数相同,同样包括开始位置(start)、结束位置(stop)和步长(step)。start和step参数是可选的。

tee()函数根据一个原输入迭代器返回多个独立的迭代器(默认为2个)。
from itertools import * r = islice(count(), 5) i1, i2 = tee(r) print('i1:', list(i1)) print('i2:', list(i2))
tee()的语义类似与UNIX tee工具,它会重复从输入读到的值,并把它们写至一个命名文件和标准输出。tee()返回的迭代器可以用来为并行处理的多个算法提供相同的数据集。
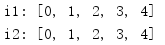
tee()创建的新迭代器会共享其输入迭代器,所以创建了新迭代器后,不应再使用原迭代器。
from itertools import * r = islice(count(), 5) i1, i2 = tee(r) print('r:', end=' ') for i in r: print(i, end=' ') if i > 1: break print() print('i1:', list(i1)) print('i2:', list(i2))
如果原输入迭代器的一些值已经消费,新迭代器不会再生成这些值。

1.2 转换输入
内置的map()函数返回一个迭代器,它对输入迭代器中的值调用一个函数并返回结果。任何输入迭代器中的元素全部消费时,map()函数都会停止。
def times_two(x): return 2 * x def multiply(x, y): return (x, y, x * y) print('Doubles:') for i in map(times_two, range(5)): print(i) print(' Multiples:') r1 = range(5) r2 = range(5, 10) for i in map(multiply, r1, r2): print('{:d} * {:d} = {:d}'.format(*i)) print(' Stopping:') r1 = range(5) r2 = range(2) for i in map(multiply, r1, r2): print(i)
在第一个例子中,lambda函数将输入值乘以2。在第二个例子中,lambda函数将两个参数相乘(这两个参数分别来自不同的迭代器),返回一个元组,其中包含原参数和计算得到的值。第三个例子会在生成两个元组后停止,因为第二个区间已经处理完。

starmap()函数类似于map(),不过并不是由多个迭代器构成一个元组,它使用 * 语法分解一个迭代器中的元素作为映射函数的参数。
from itertools import * values = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9)] for i in starmap(lambda x, y: (x, y, x * y), values): print('{} * {} = {}'.format(*i))
map()的映射函数名为f(i1,i2),而传入starmap()的映射函数名为f(*i)。

1.3 生成新值
count()函数返回一个迭代器,该迭代器能够无限地生成连续的整数。第一个数可以作为参数传入(默认为0)。这里没有上界参数(参见内置的range(),这个函数对结果集可以有更多控制)。
from itertools import * for i in zip(count(1), ['a', 'b', 'c']): print(i)
这个例子会停止,因为列表参数会被完全消费。
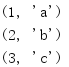
count()的“开始位置”和“步长”参数可以是可相加的任意的数字值。
import fractions from itertools import * start = fractions.Fraction(1, 3) step = fractions.Fraction(1, 3) for i in zip(count(start, step), ['a', 'b', 'c']): print('{}: {}'.format(*i))
在这个例子中,开始点和步长是来自fraction模块的Fraction对象。

cycle()函数返回一个迭代器,它会无限地重复给定参数的内容。由于必须记住输入迭代器的全部内容,所以如果这个迭代器很长,则可能会耗费大量内存。
from itertools import * for i in zip(range(7), cycle(['a', 'b', 'c'])): print(i)
这个例子中使用了一个计数器变量,在数个周期后会中止循环。

repeat()函数返回一个迭代器,每次访问时会生成相同的值。
from itertools import * for i in repeat('over-and-over', 5): print(i)
repeat()返回的迭代器会一直返回数据,除非提供了可选的times参数来限制次数。

如果即要包含来自其他迭代器的值,也要包含一些不变的值,那么可以结合使用repeat()以及zip()或map()。
from itertools import * for i, s in zip(count(), repeat('over-and-over', 5)): print(i, s)
这个例子中就结合了一个计数器值和repeat()返回的常量。

下面这个例子使用map()将0到4区间中的数乘以2。
from itertools import * for i in map(lambda x, y: (x, y, x * y), repeat(2), range(5)): print('{:d} * {:d} = {:d}'.format(*i))
repeat()迭代器不需要被显式限制,因为任何一个输入迭代器结束时map()就会停止处理,而且range()只返回5个元素.

1.4 过滤
dropwhile()函数返回一个迭代器,它会在条件第一次变为false之后生成输入迭代器的元素。
from itertools import * def should_drop(x): print('Testing:', x) return x < 1 for i in dropwhile(should_drop, [-1, 0, 1, 2, -2]): print('Yielding:', i)
dropwhile()并不会过滤输入的每一个元素。第一次条件为false之后,输入迭代器的所有其余元素都会返回。

taskwhile()与dropwhile()正相反。它也返回一个迭代器,这个迭代器将返回输入迭代器中保证测试条件为true的元素。
from itertools import * def should_take(x): print('Testing:', x) return x < 2 for i in takewhile(should_take, [-1, 0, 1, 2, -2]): print('Yielding:', i)
一旦should_take()返回false,takewhile()就停止处理输入。

内置函数filter()返回一个迭代器,它只包含测试条件返回true时所对应的元素。
from itertools import * def check_item(x): print('Testing:', x) return x < 1 for i in filter(check_item, [-1, 0, 1, 2, -2]): print('Yielding:', i)
filter()与dropwhile()和takewhile()不同,它在返回之前会测试每一个元素。

filterfalse()返回一个迭代器,其中只包含测试条件返回false时对应的元素。
from itertools import * def check_item(x): print('Testing:', x) return x < 1 for i in filterfalse(check_item, [-1, 0, 1, 2, -2]): print('Yielding:', i)
check_item()中的测试表达式与前面相同,所以在这个使用filterfalse()的例子中,结果与上一个例子的结果正好相反。

compress()提供了另一种过滤可迭代对象内容的方法。不是调用一个函数,而是使用另一个可迭代对象中的值指示什么时候接受一个值以及什么时候互虐一个值。
from itertools import * every_third = cycle([False, False, True]) data = range(1, 10) for i in compress(data, every_third): print(i, end=' ') print()
第一个参数是要处理的数据迭代器。第二个参数是一个选择器迭代器,这个迭代器会生成布尔值指示从数据输入中取哪些元素(true值说明将生成这个值;false值表示这个值将被忽略)。
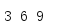
1.5 数据分组
groupby()函数返回一个迭代器,它会生成按一个公共键组织的值集。下面这个例子展示了如何根据一个属性对相关的值分组。
import functools from itertools import * import operator import pprint @functools.total_ordering class Point: def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return '({}, {})'.format(self.x, self.y) def __eq__(self, other): return (self.x, self.y) == (other.x, other.y) def __gt__(self, other): return (self.x, self.y) > (other.x, other.y) # Create a dataset of Point instances data = list(map(Point, cycle(islice(count(), 3)), islice(count(), 7))) print('Data:') pprint.pprint(data, width=35) print() # Try to group the unsorted data based on X values print('Grouped, unsorted:') for k, g in groupby(data, operator.attrgetter('x')): print(k, list(g)) print() # Sort the data data.sort() print('Sorted:') pprint.pprint(data, width=35) print() # Group the sorted data based on X values print('Grouped, sorted:') for k, g in groupby(data, operator.attrgetter('x')): print(k, list(g)) print()
输入序列要根据键值排序,以保证得到预期的分组。

1.6 合并输入
accumulate()函数处理输入迭代器,向一个函数传递第n和n+1个元素,并且生成返回值而不是某个输入。合并两个值的默认函数会将两个值相加,所以accumulate()可以用来生成一个数值输入序列的累加和。
from itertools import * print(list(accumulate(range(5)))) print(list(accumulate('abcde')))
用于非整数值序列时,结果取决于将两个元素“相加”是什么含义。这个脚本中的第二个例子显示了当accumulate()接收到一个字符串输入时,每个相应都将是该字符串的一个前缀,而且长度不断增加。

accumulate()可以与任何取两个输入值的函数结合来得到不同的结果。
from itertools import * def f(a, b): print(a, b) return b + a + b print(list(accumulate('abcde', f)))
这个例子以一种特殊的方式合并字符串值,会生成一系列(无意义的)回文。每一步调用f()时,它都会打印accumulate()传入的输入值。

迭代处理多个序列的嵌套for循环通常可以被替换为product(),它会生成一个迭代器,值为输入值集合的笛卡尔积。
from itertools import * import pprint FACE_CARDS = ('J', 'Q', 'K', 'A') SUITS = ('H', 'D', 'C', 'S') DECK = list( product( chain(range(2, 11), FACE_CARDS), SUITS, ) ) for card in DECK: print('{:>2}{}'.format(*card), end=' ') if card[1] == SUITS[-1]: print()
product()生成的值是元组,成员取自作为参数传入的各个迭代器(按其传入的顺序)。返回的第一个元组包含各个迭代器的第一个值。传入product()的最后一个迭代器最先处理,接下来处理倒数第二个迭代器,依此类推。结果是按第一个迭代器、下一个迭代器等的顺序得到的返回值。
在这个例子中,扑克牌首先按牌面大小排序,然后按花色排序。
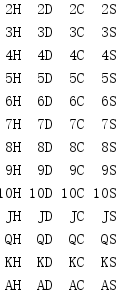
要改变这些扑克牌的顺序,需要改变传入product()的参数的顺序。
from itertools import * FACE_CARDS = ('J', 'Q', 'K', 'A') SUITS = ('H', 'D', 'C', 'S') DECK = list( product( SUITS, chain(range(2, 11), FACE_CARDS), ) ) for card in DECK: print('{:>2}{}'.format(card[1], card[0]), end=' ') if card[1] == FACE_CARDS[-1]: print()
这个例子中的打印循环会查找一个A而不是黑桃,然后增加一个换行使输出分行显示。

要计算一个序列与自身的积,开源指定输入重复多少次。
from itertools import * def show(iterable): for i, item in enumerate(iterable, 1): print(item, end=' ') if (i % 3) == 0: print() print() print('Repeat 2: ') show(list(product(range(3), repeat=2))) print('Repeat 3: ') show(list(product(range(3), repeat=3)))
由于重复一个迭代器就像把同一个迭代器传入多次,product()生成的每个元组所包含的元素个数就等于重复计数器。

permutations()函数从输入迭代器生成元素,这些元素以给定长度的排列形式组合。默认地它会生成所有排列的全集。
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('All permutations: ') show(permutations('abcd')) print(' Pairs: ') show(permutations('abcd', r=2))
可以使用r参数限制返回的各个排列的长度和个数。

为了将值限制为唯一的组合而不是排列,可以使用combinations()。只要输入的成员是唯一的,输出就不会包含任何重复的值。
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('Unique pairs: ') show(combinations('abcd', r=2))
与排列不同,combinations()的r参数是必要参数。

尽管combinations()不会重复单个的输入元素,但有时可能也需要考虑包含重复的元素组合。对于这种情况,可以使用combinations_with_replacement()。
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('Unique pairs: ') show(combinations_with_replacement('abcd', r=2))
在这个输出中,每个输入元素会与自身以及输入序列的所有其他成员配对。
