一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
二、文件准备
2.1 文件名称
hadoop-2.7.3.tar.gz
2.2 下载地址
http://hadoop.apache.org/releases.html

三、工具准备
3.1 Xshell
一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。
Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
3.2 Xftp
一个基于 MS windows 平台的功能强大的SFTP、FTP 文件传输软件。
使用了 Xftp 以后,MS windows 用户能安全地在UNIX/Linux 和 Windows PC 之间传输文件。
四、部署图

五、Hadoop安装
以下操作,均使用root用户
5.1 主机名与IP地址映射关系配置
Master节点上,执行如下命令:
#vi /etc/hosts
在文件最后,输入如下内容:
10.10.0.1 DEV-SH-MAP-01 10.10.0.2 DEV-SH-MAP-02 10.10.0.3 DEV-SH-MAP-03
保存,退出,然后通过scp命令,将配置好的文件拷贝其他两个Slave节点:
#scp /etc/hosts root@DEV-SH-MAP-02:/etc
#scp /etc/hosts root@DEV-SH-MAP-03:/etc
5.2 SSH免登陆配置
#ssh-keygen -t rsa
一直回车
然后分别拷贝到Master以及Slave节点:
#ssh-copy-id DEV-SH-MAP-01 #ssh-copy-id DEV-SH-MAP-02 #ssh-copy-id DEV-SH-MAP-03
通过#ssh DEV-SH-MAP-02 测试是否配置成功,如果不需要输入密码,则证明配置成功
5.3 通过Xftp将下载下来的Hadoop安装文件上传到Master及两个Slave的/usr目录下
5.4 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf hadoop-2.7.3.tar.gz
5.5 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
# Hadoop Env
export HADOOP_HOME=/usr/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.6 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
5.7 查看Hadoop版本信息
# hadoop version Hadoop 2.7.3 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff Compiled by root on 2016-08-18T01:41Z Compiled with protoc 2.5.0 From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4 This command was run using /usr/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
六、Hadoop配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Slave节点即可。
切换到/usr/hadoop-2.7.3/etc/hadoop/目录下,修改如下文件:
6.1 hadoop-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/usr/jdk1.8.0_121 export HADOOP_PREFIX=/usr/hadoop-2.7.3
6.2 yarn-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/usr/jdk1.8.0_121
6.3 core-site.xml
创建tmp目录:#mkdir /usr/hadoop-2.7.3/tmp
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://DEV-SH-MAP-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/hadoop/tmp</value>
</property>
</configuration>
6.4 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/mnt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/mnt/hadoop/dfs/data</value>
</property>
</configuration>
6.5 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>DEV-SH-MAP-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>DEV-SH-MAP-01:19888</value>
</property>
</configuration>
6.6 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>DEV-SH-MAP-01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>DEV-SH-MAP-01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>DEV-SH-MAP-01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>DEV-SH-MAP-01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>DEV-SH-MAP-01:8088</value>
</property>
</configuration>
6.7 slaves
DEV-SH-MAP-01 DEV-SH-MAP-02 DEV-SH-MAP-03
6.8 拷贝配置文件到两个Slave节点
在Master节点,执行如下命令:
# scp -r /usr/hadoop-2.7.3/etc/hadoop/ root@DEV-SH-MAP-02:/usr/hadoop-2.7.3/etc/
# scp -r /usr/hadoop-2.7.3/etc/hadoop/ root@DEV-SH-MAP-03:/usr/hadoop-2.7.3/etc/
七、Hadoop使用
7.1 格式化NameNode
Master节点上,执行如下命令
#hdfs namenode -format
7.2 启动HDFS(NameNode、DataNode)
Master节点上,执行如下命令
#start-dfs.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode 33922 NameNode 34028 DataNode 49534 Jps
在两个Slave上,看到如下进程:
34028 DataNode 49534 Jps
7.3 启动 Yarn(ResourceManager 、NodeManager)
Master节点上,执行如下命令
#start-yarn.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode
33922 NameNode
34632 NodeManager
34523 ResourceManager
34028 DataNode
49534 Jps
在两个Slave上,看到如下进程:
34632 NodeManager
34028 DataNode
49534 Jps
7.4 通过浏览器查看HDFS信息
浏览器中,输入http://10.10.0.1:50070
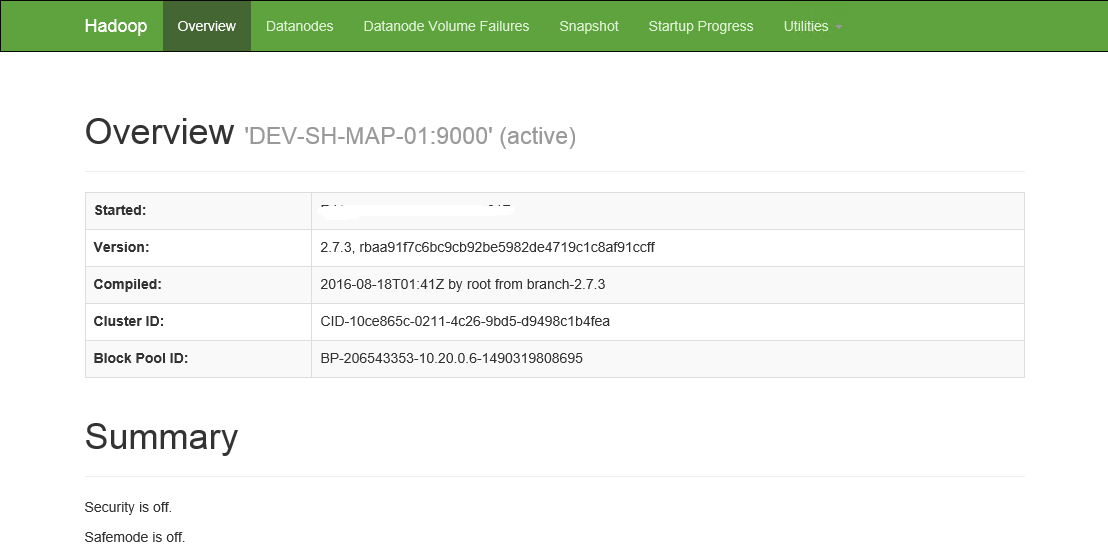
7.5 通过浏览器查看Yarn信息
浏览器中,输入http://10.10.0.1:8088
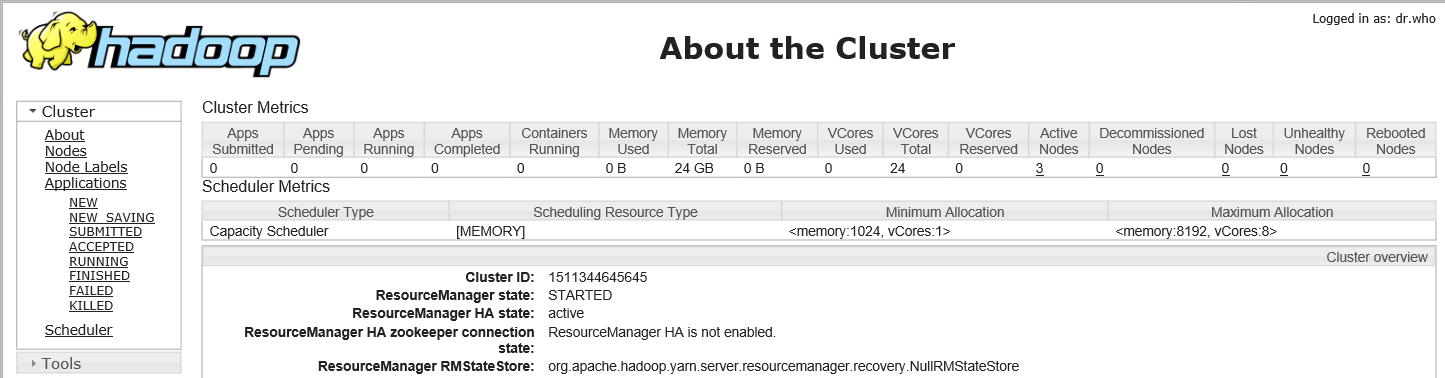
7.6 停止Yarn及HDFS
#stop-yarn.sh
#stop-dfs.sh