- SparkSession、SparkContext
- SparkContext:从Spark2.0开始之后,spark使用全新的SparkSession接口代替Spark1.6的的SQLContext和HiveContext
-
 SparkContext
SparkContext1 //set up the spark configuration and create contexts 2 val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local") 3 // your handle to SparkContext to access other context like SQLContext 4 val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value") 5 val sqlContext = new org.apache.spark.sql.SQLContext(sc)
-
- SparkSession:是SparkSQL的入口,Builder是SparkSession的构造器,通过stop函数来停止(SparkConf、SparkContext、SQLContext均封装在其中)
- Builder:
- getOrCreate
- enableHiveSupport
- appName
- config
- Spark.conf.set:设置运行参数
- 读取元数据:
spark.catalog.listDatabases.show(false)-
spark.catalog.listTables.show(false)
- 创建DataSet
- range()
- 创建DataFrame
- createDataFrame()
- Builder:
- SparkContext:从Spark2.0开始之后,spark使用全新的SparkSession接口代替Spark1.6的的SQLContext和HiveContext
- RDD、DataSet、DataSchema
- DataSet:
Dataset<String> logData = spark.read().textFile(logFile).cache();
- DataSet:
- 集群模式
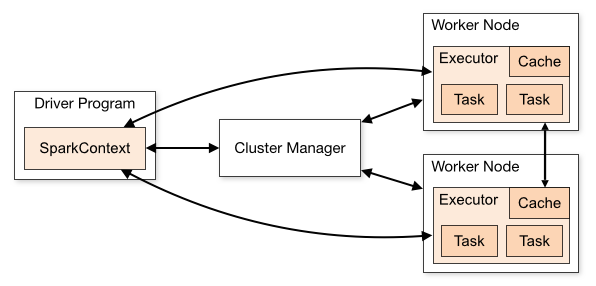
-
集群模式
- standalone
- Apache Mesos
- Hadoop Yarn
- Kubernets
- 提交应用
./bin/spark-submit --class <main-class> (e.g.
org.apache.spark.examples.SparkPi) --master <master-url> (e.g.spark://23.195.26.187:7077) --deploy-mode <deploy-mode> (clusterclient(default)) --conf <key>=<value> ... # other options <application-jar> (hdfs:\ or file:\) [application-arguments]- Client:
- 启动master和worker,worker负责整个集群的资源管理,监控自己的CPU、内存并定时向master报告
- 在client中启动Driver,并向master注册
- master通过rpc与worker进行通信,通知worker启动一个或多个executor进程
- executor进程向Driver注册,告知Driver自身的信息,包括所在节点的host等
- Driver对job进行划分stage,并对stage进行更进一步的划分,将一条pipeline封装成一个task,并向自己注册的executor进程中的task线程中执行
- 应用程序执行完成,Driver进程退出
- Cluster:
- 启动master和worker,worker负责整个集群的资源管理,监控自己的CPU、内存并定时向master报告
- 客户端提交任务后,ActorSelection(master的actor引用),然后通过ActorSelection给master发送注册Driver请求(RequestSubmitDriver)
- 客户端提交任务后,master通知worker节点启动driver进程。(worker的选择是随意的,只要worker有足够的资源即可)driver进程启动成功后,将向master返回注册成功信息
- master通知worker启动executor进程
- 启动成功后的executor的进程向driver进行注册
- Driver对job进行划分stage,并对stage进行更进一步的划分,将一条pipeline封装成一个task,并向自己注册的executor进程中的task线程中执行
- 所有task执行完毕后,程序结束
- Master URL:
- local
- local[K]
- local[K,F]:K-worker,F-maxFailures
- local[*]
- local[*,F]
- spark://HOST:PORT
- spark://HOST1:PORT1,HOST2:PORT2;all the masters in HA
- mesos://HOST:PORT
- yarn
- k8s://HOST:PORT
- Load Configuration:By default, it will read options from conf/spark-default.conf
- 若需要知道配置文件的来源,可使用--verbose
- jar包依赖:使用--jar选项的jar包将会自动传输到集群
- file:绝对路径,file:/URIs存储在driver's HTTP文件服务器,每个executor从driver HTTP服务器获取jar包
- hdfs:http:https:ftp
- local:默认每个work节点本地都有该文件
- jar包清理:yarn自动清理;spark standalone可用spark.worker.cleanup.appDataTtl来配置自动清理
- --package:添加maven依赖
- --repositories:附加存储库或SBT解析器
- Client:
