参考:http://blog.csdn.net/u010270403/article/details/51444677
虚拟机中共五个centos系统,每个系统有两个用户root和hadoop:cdh1,cdh2,cdh3,cdh4,cdh5
集群规划

第一步,切换到hadoop的家目录下,然后在hadoop家目录下创建 tools目录(只在一台机器即可,以cdh1为例)
创建tools目录
#mkdir tools
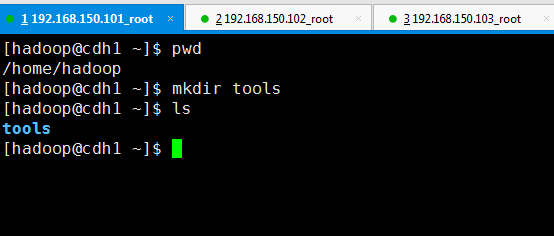
第二步,在tools目录下创建三个批处理文件:deploy.conf、deploy.sh、runRemoteCmd.sh(因为后续还要用Hadoop为这三个文件赋权限,且只有Hadoop用户会用这些文件,所以这三个文件用Hadoop用户创建)
创建deploy.conf
#vi deploy.conf
cdh1,all,namenode,journalnode,resourcemanager,
cdh2,all,namenode,journalnode,slave,resourcemanager,
cdh3,all,zookeeper,slave,journalnode,datanode,nodemanager,
cdh4,all,zookeeper,slave,journalnode,datanode,nodemanager,
cdh5,all,zookeeper,slave,journalnode,datanode,nodemanager,
创建deploy.sh
#vi deploy.sh
#!/bin/bash #set -x #判断参数是否小于3个,因为运行deploy.sh需要有源文件(或源目录)和目标文件(或目标目录), #以及在MachineTag(哪些主机)上执行,这个标记就是上面deploy.conf中的标记 ,如 zookeeper、all等 #使用实例如:我们把app目录下的所有文件复制到远程标记为zookeeper的主机上的/home/hadoop/app目录下 # ./deploy.sh /home/hadoop/app /home/hadoop/app zookeeper #执行完上述命令后,shell脚本文件就自动把CDHNode1下的app目录中的文件复制到三个zookeeper节点的app目录下 if [ $# -lt 3 ] then echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag" echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile" exit fi #源文件或源目录 src=$1 #目标文件或目标目录 dest=$2 #标记 tag=$3 #判断是否使用deploy.conf配置文件,或者自己指定配置文件 if [ 'a'$4'a' == 'aa' ] then confFile=/home/hadoop/tools/deploy.conf else confFile=$4 fi #判断配置文件是否是普通文本文件 if [ -f $confFile ] then #判断原件是普通文件还是目录 if [ -f $src ] then #如果是普通文件就把解析出标记对应的主机名的ip for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'` do scp $src $server":"${dest} #使用循环把文件复制到目标ip上的相应目录下 echo "循环"$src $server":"${dest} done elif [ -d $src ] then for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'` do scp -r $src $server":"${dest} echo "循环"$src $server":"${dest} done else echo "Error: No source file exist" fi else echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory" fi
创建runRemoteCmd.sh#vi runRemoteCmd.sh
#!/bin/bash #set -x #判断参数个数 #实例如:显示所有节点的java进程,中间用引号的就是命令,这个命令将在所以节点上执行 #./runRemoteCmd.sh "jps" all if [ $# -lt 2 ] then echo "Usage: ./runRemoteCmd.sh Command MachineTag" echo "Usage: ./runRemoteCmd.sh Command MachineTag confFile" exit fi cmd=$1 tag=$2 if [ 'a'$3'a' == 'aa' ] then confFile=/home/hadoop/tools/deploy.conf else confFile=$3 fi if [ -f $confFile ] then for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'` do echo "*******************$server***************************" ssh $server "source /etc/profile; $cmd" # 注意在使用的时候要根据自己设置的环境变量的配置位置,给定相应的source源 , # 如 我把环境变量设/home/hadoop/.bash_profile文件下,就需要上面这条命令改为 # ssh $server "source /home/hadoop/.bash_profile;$cmd" #上面的例子:这条命令就是在远程标记为tag的主机下执行这个命令jps。 done else echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory" fi
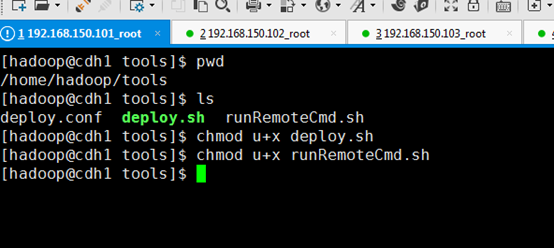
第三步,给脚本文件添加执行权限
#chmod u+x deploy.sh #chmod u+x runRemoteCmd.sh
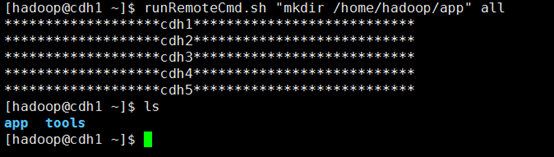
第五步,在cdh1节点上,通过runRemoteCmd.sh脚本,一键创建所有节点的软件安装目录/home/hadoop/app
# ./runRemoteCmd.sh "mkdir /home/hadoop/app" all
查看cdh1和cdh2家目录
cdh1

cdh2
在cdh1上进入~/tools,执行runRemoteCmd.sh脚本,并查看Hadoop家目录
cdh1
cdh2
完成!