https://github.com/little-seasalt/031902343
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 2260 | 3040 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 480 |
| · Design Spec | · 生成设计文档 | 60 | 90 |
| · Design Review | · 设计复审 | 30 | 90 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 50 | 60 |
| · Design | · 具体设计 | 200 | 180 |
| · Coding | · 具体编码 | 1200 | 1600 |
| · Code Review | · 代码复审 | 360 | 360 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 95 | 105 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 45 | 60 |
| · 合计 | 2385 | 3205 |
二、计算模块接口
-
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
用到的函数如下:
1.void build_sensitivepy();//建立敏感词的映射,并区分中英文敏感词
2.void buildArticle_Chinese();//用于匹配中文敏感词的文本
3.void buildArticle_Endlish();//用于匹配英文敏感词的文本
4.void getNxte();//kmp算法求nxt数组
5.void getAnswer_chinese();//中文敏感词kmp匹配
6.void getAnswer_english();//中文敏感词kmp匹配
7.void match_chinese();//中文匹配
8.void match_english();//英文匹配
9.int getAllPingyinForWord();//获取一个汉字的【所有】拼音(首字母、全拼)
10.wstring getNoRepeatPingyinForWord();//获取一个字的拼音,如果是多音字返回常用读音,如果不是则返回该字
11.bool isHanziChar();//检查是否为汉字
12.bool isfullp();//判断全角符号
13.void buildMap();//读取词库,并建立映射
14.int buildSensitiveWord();//建立敏感词的拆字完的部分并保存原词
15.wstring& buildArticle();//建立文章的拆字完的部分并保存原文本
16.void getNxt();//建立nxt数组
17.void getAnswer();//kmp算法
18.void match();//对每个敏感字在文章上查找敏感
关键之处:
代码的核心算法是kmp,利用kmp进行敏感词匹配(本来想用AC自动机,但想想其实kmp也可以,AC自动机不是特别熟)。主题思路就是拆分敏感词和文章,然后进行一一比对,具体的思路和流程如下图:
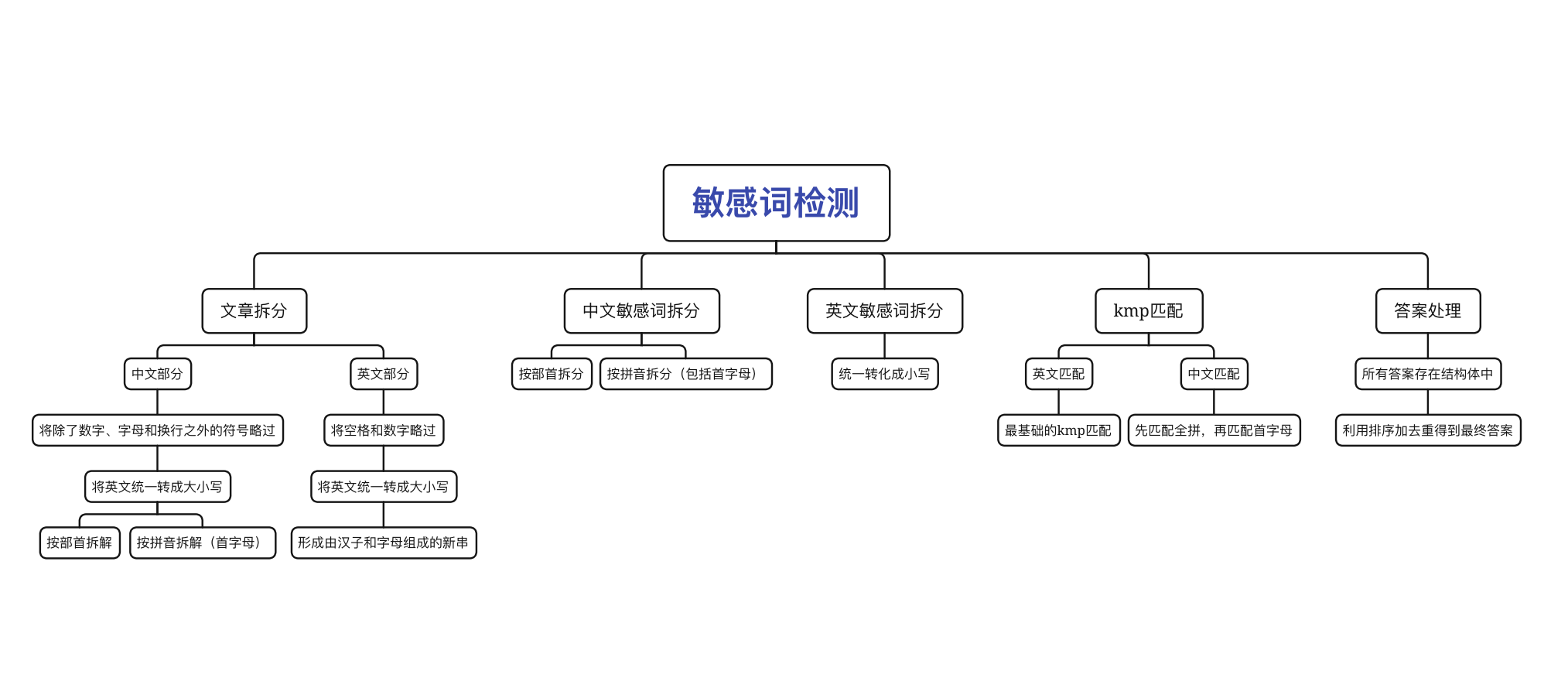
独到之处:
感觉没啥独到之处,就是比较普通的一些算法(高端的还不会,还受语言限制),如果非说独到之处,就是本来会出现的繁体字被我全部转成拼音,这样就可以省去简繁体转换这一步。但感觉算我的算法其实是一种非常暴力的算法,整篇文本在我的代码里进行四次遍历,分别被拆解成不同的样子进行kmp匹配,整个时间复杂度其实挺高的。因为进行了四次全文的kmp和敏感词匹配,耗费一定的时间复杂度的基础上,更多了保证正确率吧,遗漏敏感词的情况会大大减少。
-
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
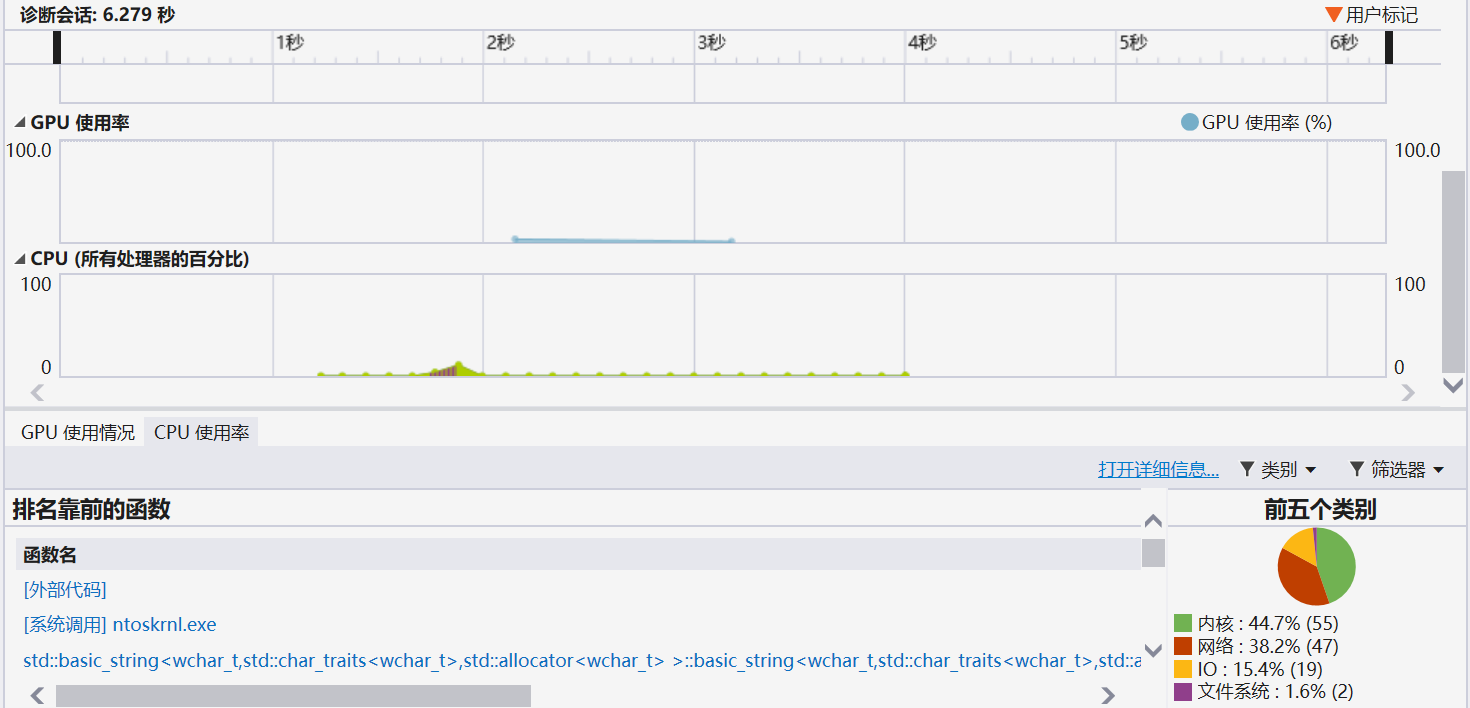

由上图可知,除了主函数之外最大消耗函数是buildMap,其代码如下:
void buildMap()
{
freopen("chinese.txt", "r", stdin);
while (scanf("%s", str) > 0)
{
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
wstring s = converter.from_bytes(str);
wstring word = s.substr(0, 1);
wstring part = s.substr(1, s.length() - 1);
mp[word] = part;
}
}
-
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。

这是群里的样例跑出来的答案,与更正后的答案完全一致。

单元测试的测试覆盖图是在是不是很会,所以没有弄出来。补上一张自己构造的样例跑出来的图,和预期答案是一样的。
-
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
当传入参数数目不对的时候
if (argc != 4) {
printf("Incorrect number of files. Please confirm and try again.
" );
return 0;
}

三、心得
心得体会有很多,讲几点印象比较深的:
1.只会一门编程语言是真的很吃亏,知道别人语言有更好的解决问题的办法,但奈何一点都不会,本想速成,但又觉得单纯速成的知识应用起来可能会很不顺手,最后还是选了原本的C++语言(虽然C++之前也没有学的很好),深深地感受到在空闲时间多学点东西的重要性;
2.按照题目的要求做出一个有点实用性的东西和之前面向题目编写一段代码是完全不一样的,之前没有类似的经验,拿到题目的时候还是很迷茫的,有点无从下手,对题目分析完大致弄懂了需要实现的功能,渐渐开始一点点做起来,整个做的过程中学习了很多新的东西,也把过去有些学过但已经忘的东西给捡回来了;
3.由于各方面能力的限制,在DDL前不久才赶出了程序,可能这个程序并没有完全达到题目的要求,但完成程序的那一刻确实有满满的收获感;
4.实在不会的东西,多用搜索和求助,不要死磕在一个地方。
5.Python真的要学起来了,那个单元测试利用VS一直弄不出来,但是听用Python的同学说挺好弄的。