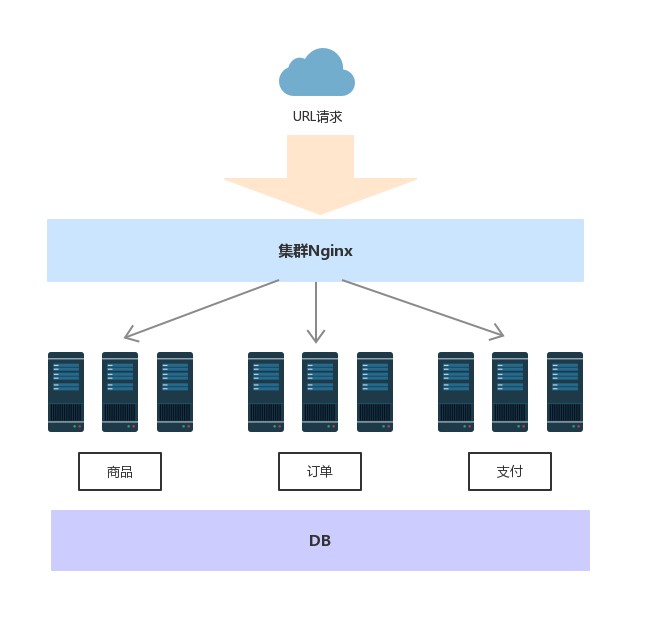
1、分布式集群架构
2、分布式高并发环境的订单号要求
- 全局唯一
- 订单号信息要安全
- 趋势递增
3、订单号生成策略总结
| 策略 | 优点 | 缺点 | 格式 |
|---|---|---|---|
| uuid | 实现简单不占用带宽 | 无序、不可读、查询慢 | 32位 |
| db自增 | 无代码、递归 | DB单点故障、扩展有瓶颈 | |
| snowflake | 不占用带宽、低位趋势递增 | 依赖服务器时间 | 18位 |
| redis | 无单点故障、性能优于DB递增 | 占用带宽、Redis集群需要维护 | 12位 |
3.1、策略一:UUID(通用唯一识别码)
组成:当前日期+时间+时钟序列+机器识别号(MAC地址或其他)
分布式系统中,所有元素(web服务器)都不需要通过中央控制端来判断数据唯一性。
3.2、策略二:数据库自增ID
关系型数据库都实现数据库自增ID;mysql通过auto_increment实现、oralce通过sequence实现。
在数据库集群环境下,不同数据库节点可设置不同起步值、相同步长值来实现集群下生成全局唯一、递增ID。
3.3、策略三:snowflake算法
组成:41位时间戳+10为机器ID+12位序列号(自增),转换位长度为18的长整型。
twitter位满足每秒上万条消息的创建,每条消息都必须分配全局唯一id,这些id要趋势递增,方便客户排序。
github上可以下载到snowflake源码

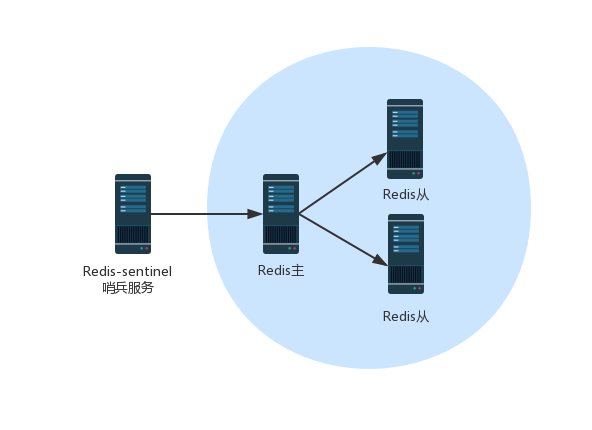
3.4、策略四:Redis自增ID
- redis的api: incr(key) 若key存在,则将key的value递增1并返回,如果key不存在则将改key对应的value初始化为0并返回。
- 自增格式:前缀+自增id 。
- 超时时间:使用超时时间是为了防止自增到9999时订单号的位数变长。
public class RedisUtil {
@Autowired
JedisPool jedisPool;
public long getIncr(String key, int timeout) {
Jedis redis = null;
try {
redis = jedisPool.getResource();
// 当key不存在时,创建一个值为0的key
long id = redis.incr(key);
if (timeout > 0) {
// 设置超时时间
redis.expire(key, timeout);
return id;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (redis != null) {
redis.close();
}
}
return -1;
}
}