To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and being are stored as showed in Figure 1.
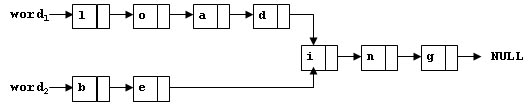
Figure 1
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive N (≤), where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −.
Then N lines follow, each describes a node in the format:
Address Data Next
whereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input 1:
11111 22222 9
67890 i 00002
00010 a 12345
00003 g -1
12345 D 67890
00002 n 00003
22222 B 23456
11111 L 00001
23456 e 67890
00001 o 00010
Sample Output 1:
67890
Sample Input 2:
00001 00002 4
00001 a 10001
10001 s -1
00002 a 10002
10002 t -1
Sample Output 2:
-1
最后一个case错是因为,没有理解,同一个字母可以有多个地址
#include <iostream> #include <unordered_map> using namespace std; struct node{ string addr, ch, next; }; int main() { ios::sync_with_stdio(false); cin.tie(0); int N; string addr, addr2; node tmp; unordered_map<string, node> m; unordered_map<string, bool> m2; cin >> addr >> addr2 >> N; for(int i = 0; i < N; i++) { cin >> tmp.addr >> tmp.ch >> tmp.next; m[tmp.addr] = tmp; } while(addr != "-1") { m2[addr] = true; addr = m[addr].next; } while(addr2 != "-1") { if(m2[addr2]) { cout << m[addr2].addr << endl;return 0; } addr2 = m[addr2].next; } cout << -1 << endl;return 0; }