第一个python程序
一、运行python(.py)文件
终端运行:通过 ls 命令,查找相对应的文件--cd到相对应的文件下面--终端输入:python+运行的文件名即可,如下图:

查看文件是否可执行命令:ls -slh helly.py
如果运行出来的结果如下图,有x就代表文件可执行。

C++、C、JAVA、PHP、BUBY、GO、python 各个语言print出“hello world”的区别(截图后续补上)
变量的定义
一、变量的定义
二、变量的作用
1、存储信息,类似于一个容器
将数据存储在内存里面
内存于硬盘的区别
内存:临时存储
硬盘:永久存储
2、被调用
3、标识数据的名称或者类型
三、声明变量
1、用“”标注起来的为字符串

2、变量的命名规则
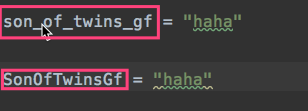
正确的命名规则:变量名只能是字母、数字、下划线的任意组合
首个字母大写:驼峰体
利用_下划线区分
错误的命名规则
-不可以使用(代表的是减号)
不可以数字开头
特殊字符开头
变量里面不能有空格:命名里面会有空格
以下关键字不能被声明为变量: ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
四、变量的作用域
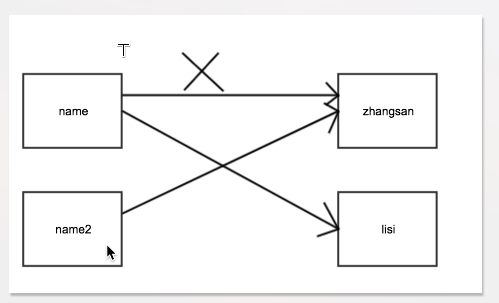
name = "zhangsan" name1 = name name = "lisi" print(name,name1) #结果:lisi zhangsan
五、常量
在python当中是没有常量这个概念的,但是当别人定义数据的时候前面是全部大写的话,就表示是一个常量,不能修改的,如果修改的话会报错。
如:连接数据库的信息算是一个常量,不能随便的进行更改。如果有更改的话应该要重启下程序才可以。
![]()
字符编码
一、ascii码
计算机最小的存储单位:比特(一个二进制位)(bite)
二进制:0、1
字节 = 8bite
1024字节 = 1KB
1024KB = 1GB
1个字符 = 8比特位(bit,8个0或1二进制编码组成) = 1字节(byte)
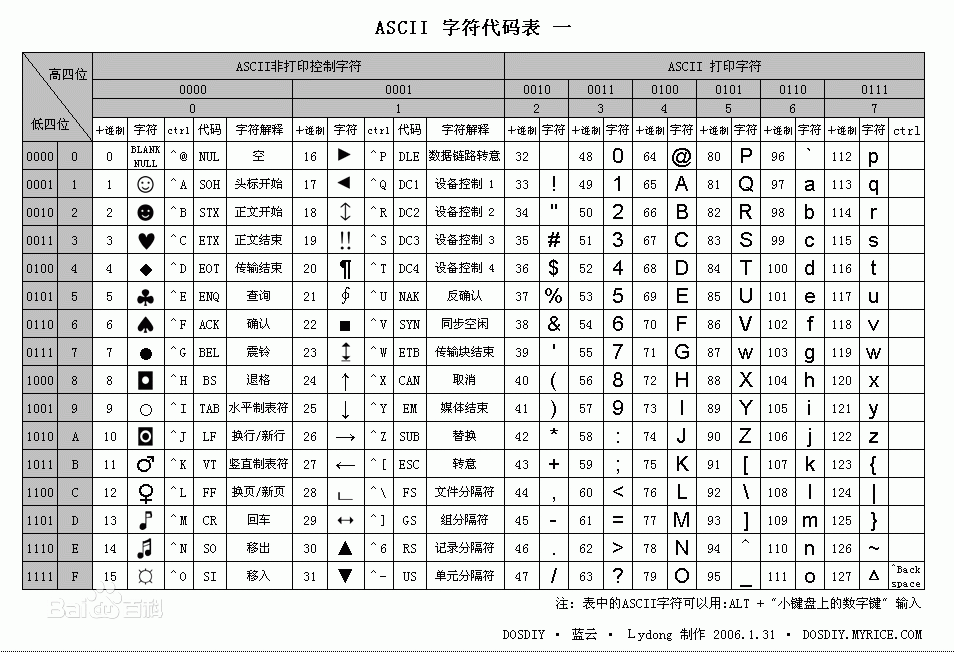
如图所示,有127个字符,如果我们自己看到一个字母E其实计算机去ascii表中查询字母E对应的十进制69,并且转化成二进制01010100;计算机是由西方人发明的,刚开始的时候只能支持英文,也就是26个字母就可以拼出所有的英文单词,加上一些特殊字符就只有占用127个字符--一个字符就可以将整张表的数据存储下来。一个字节8位,能表示的最大数字位28 -1 =255个字符
上面的ascii中占用的是127,剩下扩展的为255 - 127 =128种方式。后面其它国家的经济发展越来越快,如:中国这边也引进了电脑的技术,而且单单常用的汉字就有六千多个字,就将剩下的字符中占用一位字符扩展成另一张表(这张表要存储的大小由我们自己来确定),这张扩展出来的表中存储的就是全部的中文和其它国家的文字。中国扩展的表中会包含日文、韩文、中文,日本所扩展的表中也有了中文、日文等语言,这样就会赞成了乱码的情况(同一种语言在不同编码表里面的编码归责是不一样的)--国外的部分软件,我们安装之后就会乱码(字符集出现交叉导致乱码要么就是没有安装相对应的字符集)
二、unicode编码
由于上面会出现乱码的问题,所以就统一推出了unicode编码(统一码、万国码),是一种在计算机上使用的字符编码,unicode是为了解决传统的字符编码方案的局限而产生的,,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定所有的字符和符号最少由16位来表示(2个字节),即216 = 65536种 (比之前的ascii多一个或者更多的字符,占用的空间太大,推出下面的UTF-8 编码)
三、UTF- 8编码
是对unicode编码的压缩和优化,不再使用最少2个字节,而是将所有的字符和符号进行分类:ascii码种的内容用1个字节保存,欧洲的字符用2个字符保存,东亚(中文)的字符由3个字符保存
四、python2.X版本的编码声明
python3.X默认编码集都是UTF-8,所以不用做相对应的声明。
python2.0的时候只支持ascii编码,所以需要写入中文的时候需要告诉解释器,用UTF-8编码来执行源代码
#!/user/bin/env python 加解释器 # -*- coding: utf-8 -*- 加字符集
五、添加编码集
点击【Settings】--Editor--File and Code Templates--python Script 进行添加默认编码集即可
注释
一、单行注释:#
在每段代码后面或者是上面可以利用#进行添加单行注释
二、多行注释:''' '''
python的开发规范:每一行的代码不超过80个字符
多行注释(可以为单、双引号,但是一定要英文的输入法情况下写入)
用户输入
一、python3
程序启动,读取用户的输入,并且打印出来
user_input = input('input your name:') print("user input msg:",user_input)
二、python2
1、raw_input
user_input = raw_input("your name:") print (user_input)
2、input
name = "haha" #先声明变量name user_input = input("your name:") print (user_input)
解析:如果在2.7里面使用input的话,输入的是一个字符串的时候,系统不认为是一个字符串,而是一个变量,就会去找这个变量,找不到就会报错;所以如果要输入一个变量的话必须先声明,如上面代码所示。但是,如果是数字的话则是认为是数字输出。
格式化字符串
一、文本格式化
将外面的变量置换到文本里面
二、占位符:%
每一个占位符必须赋予一个变量,如果输出是字符串的话用“s”表示,如果是数字的话用“d”表示,如果是小数(浮点型)的话则是用“f”表示
三、类型转换
1、字符串转换成int类型
在python3中,只要是用input的话,输出的都是字符串类型
如上面的age,需要将字符串强制转换成数字,操作方式:
age = int(input("input your age:")) #利用int进行强制转换
2、输入年龄、姓名、工作并且打印出来
将需要输入的变量结果复制给对应的变量
s:字符 d;数字
name = input("input your name:") age = int(input("input your age:")) #只要用input,在python3里面默认都当成是字符串,如果是其他数字之类的需要将接收到的结果,强制的转换成数字 job = input("input your job:") msg=''' Infomation of user %s: ---------------------- Name: %s Age: %d Job: %s ----------End--------- '''%(name,name,age,job) print(msg)
3、浮点型举例
name = input("input your name:") age = int(input("input your age:")) ###浮点型(小数)需要用f来进行代替 job = input("input your job:") msg=''' Infomation of user %s: ---------------------- Name: %s Age: %f #浮点数
Job: %s ----------End--------- '''%(name,name,age,job) print(msg)
常用模块初识--import
一、Linux相关命令
| 相关命令 | 操作说明 |
| df | 检查Linux服务器的文件系统磁盘空间占用情况 |
| df -h | 更方便的阅读方式来展示服务器文件系统磁盘的空间占用情况 |
| ls | 列出所在目录的所有文件 |
| ls p* | 模糊搜索当前目录中包含p的文件 |
| mkdir("文件名") | 在当前目录下创建文件 |
二、导入当前目录模块
1、方法
import + 要导入的模块名称
2、说明
导入的是当前目录下面的模块
三、环境变量的查询方式
1、相关命令截图

2、说明
一般自己写的模块,都是保存在上面截图的其中一个文件当中(一般是会保存在site-packages文件中),这样这个模块的适用范围是全部文件
3、密文输入--getpass
import getpass username = input("username:") password = getpass.getpass("password:") print(username,password)
如果保存在其他文件中的话则是表示仅仅适用于这个文件
四、tab补齐模块文档
1、相关代码(只是适用于Mac,windows需要自行百度)
#!/user/bin/env python # -*- coding: utf-8 -*- import readline,rlcompleter ### Indenting class TabCompleter(rlcompleter.Completer): """Completer that supports indenting""" def complete(self, text, state): if not text: return (' ', None)[state] else: return rlcompleter.Completer.complete(self, text, state) readline.set_completer(TabCompleter().complete) ### Add autocompletion if 'libedit' in readline.__doc__: readline.parse_and_bind("bind -e") readline.parse_and_bind("bind ' ' rl_complete") else: readline.parse_and_bind("tab: complete") ### Add history import os histfile = os.path.join(os.environ["HOME"], ".pyhist") try: readline.read_history_file(histfile) except IOError: pass import atexit atexit.register(readline.write_history_file, histfile) del histfile
if判断
一、强制缩进型语言
1、相关代码
#!/user/bin/env python # -*- coding: utf-8 -*- user = 'monkey' passwd = '124555' username = input("username:") password = input("password:") if user == username: print("username is correct...") if passwd == password: print("Weclome...") else: print("password is invalid...") else: print("哈哈哈哈哈,傻了吧,用户名错了啦。。。")
2、流程图
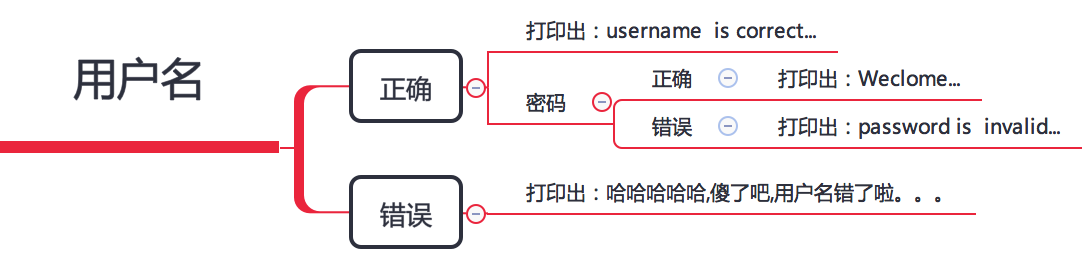
3、解析

python是属于强制缩进型的语言,如上面的代码if与print之间是属于从属关系,所以需要如上的格式。
4、等于与赋值的区别
| == | 等于(在判断语句中,如果要判断所输入的值是否跟正确的标准值是否相等的话需要用双等号) |
| = | 赋值 (赋值关系,并非判断是否相等) |
二、一条语句多个判断
1、利用and判断的相关代码
#!/user/bin/env python # -*- coding: utf-8 -*- user = 'monkey' passwd = '124555' username = input("username:") password = input("password:") if user == username and password == passwd: print("Welcome...") else: print("Invalid username or password...")
2、流程图
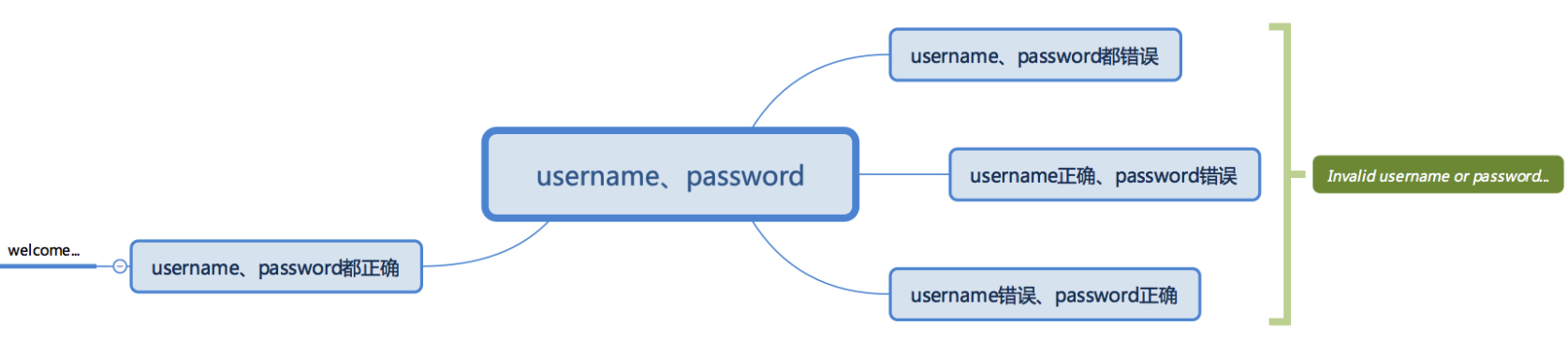
三、多重判断--elif
1、相关代码
#!/user/bin/env python # -*- coding: utf-8 -*- age = 20 guess_num = int(input("input your guess num:")) if guess_num == age: print("Congratulations! you got it.") elif guess_num > age: print("bigger...") else: print("smaller...")
2、应用场景
elif = else if 用于存在着三种或三种以上的判断情况
3、流程图
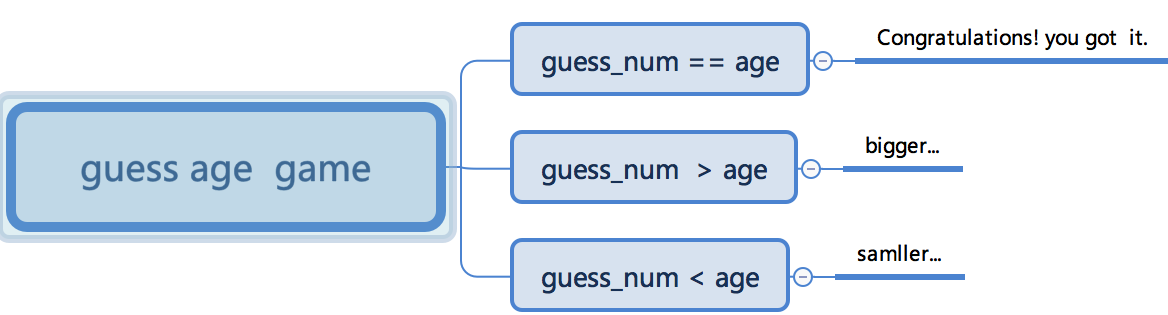
***一个语句中一个if可以对应多个elif,但是只能对应一个else***
for循环
一、基本语法
1、相关代码格式
for i in range(10): print(i)
2、语法解析
range(10):循环10次,i如果没有进行定义的话,默认是从0开始的,每次都是自增1(i++)
3、输出结果
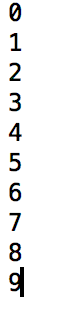
二、语句应用
1、场景
将if语句中的guess age 游戏进行循环
语句循环的次数为10次,即使是猜对了age也不会停下来,一直循环,直到10次使用完
2、相关代码
age = 20 #age是固定的参照标准,所以不用在for循环里面进行循环,故写在for循环的外面 for i in range(10): guess_num = int(input("input your guess num:")) if guess_num == age: print("Congratulations! you got it.") elif guess_num > age: print("bigger...") else: print("smaller...")
三、break语法
1、场景
如上代码,如果猜对了年龄的话就跳出循环,而不是一直循环10次才终止
2、相关代码
age = 20 for i in range(10): guess_num = int(input("input your guess num:")) if guess_num == age: print("Congratulations! you got it.") break #如果遇到break之后就跳转整个loop(循环),不再往下走 elif guess_num > age: print("bigger...") else: print("smaller...")
四、if+for循环
1、场景
在range10次的情况下,限制输入的次数只能是输入5次,如果超过5次输入错误的话则退出,不能再进行输入。
2、相关代码
#!/user/bin/env python # -*- coding: utf-8 -*- age = 20 for i in range(10): if i <= 4: #i是默认自增1的,所以可以当做次数来做参考 guess_num = int(input("input your guess num:")) if guess_num == age: print("Congratulations! you got it.") break elif guess_num > age: print("bigger...") else: print("smaller...") else: print("game over!") break #超过5次的话就退出循环,并且打印出来game over!
五、counter += 1 与 counter = counter + 1
1、场景
每循环3次问用户是否想要继续游戏,如果用户想要再继续的话就继续游戏,大于10次之后退出
2、例子1(糟糕哦)
解析:因为 for i in range(10):中的i是根据range(10),每次执行一次的话都会从range(10)中减1,而不会根据我们定义的new i1来表示为执行的次数,所以当第6次的时候,i2还是等于6,会选择直接跳出循环
#!/user/bin/env python # -*- coding: utf-8 -*- age = 20 for i in range(10): print('new i2',i) if i <= 4: guess_num = int(input("input your guess num:")) if guess_num == age: print("Congratulations! you got it.") break elif guess_num > age: print("bigger...") else: print("smaller...") else: continue_confirm = input("Do you want to continue?") if continue_confirm == "y": i = 0 print('new i1',i) else: print("game over!") break
#运行结果
new i2 0
input your guess num:3
smaller...
new i2 1
input your guess num:4
smaller...
new i2 2
input your guess num:4
smaller...
new i2 3
input your guess num:4
smaller...
new i2 4
input your guess num:44
bigger...
new i2 5
Do you want to continue?y
new i1 0
new i2 6
Do you want to continue?y
new i1 0
new i2 7
3、利用counter=+1 进行改善例子1的问题
相关代码
解析:counter += 1 与 counter = counter + 1 表示的含义都是一样的
#!/user/bin/env python # -*- coding: utf-8 -*- age = 20 counter = 0 for i in range(10): print('-->counter:',counter) if counter <= 4: guess_num = int(input("input your guess num:")) if guess_num == age: print("Congratulations! you got it.") break elif guess_num > age: print("bigger...") else: print("smaller...") else: continue_confirm = input("Do you want to continue?") if continue_confirm == "y": counter = -1 #因为后面会执行counter+1,所以重新开始输入的时候counter默认开始的是1而不是0,会少一次,所以需要修改成-1 else: print("game over!") break counter += 1 #counter = counter + 1
#运行结果
-->counter: 0
input your guess num:45
bigger...
-->counter: 1
input your guess num:54
bigger...
-->counter: 2
input your guess num:44
bigger...
-->counter: 3
input your guess num:4
smaller...
-->counter: 4
input your guess num:4
smaller...
-->counter: 5
Do you want to continue?y
-->counter: 0
input your guess num:423
bigger...
六、continue语句:继续操作指令
相关代码
解析:如果直接是用i的话,根据例子4运行的时候是会直接默认为每执行一次i加1的,需要重新定义一个变量counter来当计时器
#!/user/bin/env python # -*- coding: utf-8 -*- age = 20 counter = 0 for i in range(10): print('-->counter:',counter) if counter <= 4: guess_num = int(input("input your guess num:")) if guess_num == age: print("Congratulations! you got it.") break elif guess_num > age: print("bigger...") else: print("smaller...") else: continue_confirm = input("Do you want to continue?") if continue_confirm == "y": counter = 0 continue #只要用户输入y 就继续执行,直接不让程序往下走了,跳出当次循环,进入到下次循环 else: print("game over!") break counter += 1 #counter = counter + 1