作业要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
功能要求
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个
注意:
a) 空格,水平制表符,换行符,均算字符,需要统计的字符ASCII码值范围:32-126,其他字符均可视为分隔符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。
如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词,iPhone4和IPhone5是同一个单词,但是,windows和windows32a是不同的单词,因为他们不是仅有数字结尾不同
输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000
词组的定义:windows95 good, windows2000 good123,可以算是同一种词组。按照词典顺序输出。
c) 输入文件名以命令行参数传入
d) 输出文件result.txt
characters: number
words: number
lines: number
<word>: number
<word>为文件中真实出现的单词大小写格式,例如,如果文件中只出现了File和file,程序不应当输出FILE,且<word>按字典顺序(基于ASCII)排列,上例中程序应该输出File: 2
e) 根据命令行参数判断是否为目录
初步思路
1.文件遍历:采用深度优先搜索的方法递归遍历根目录下的所有文件
2.行数统计:以按行读取的方式读取文本文件,每次成功读取后对应的counter+1,直至文件末尾
3.字符数统计:判断字符的ASCII码范围是否是32-126,若是则对应的counter+1,若不是则继续看下一个字符
4.单词统计:根据要求,只有由至少4个英文字母打头的连续英文、数字字符串才算做一个单词,并且单词实体忽略数字尾端以及不区别大小写字母,因此可以用单词的前四个字母计算出偏移量,并根据这个偏移量将单词放入哈希散列表中,同时每个单词应具有最简形式、已统计数量等属性,故采用结构体的形式存储
5.词组统计:一个词组由两个单词构成,故可以用指向两个单词结构体的指针表示词组


typedef struct My_Word_Class { string word; string trimmed; //word without digital suffix and capital character intptr_t number; struct My_Word_Class *next; }MyWC; typedef struct My_Group_Class { MyWC *firstWord, *secondWord; intptr_t number; struct My_Group_Class *next; }MyGC;
代码实现
1.宏定义与全局变量
#define WORD_LIMIT 4 #define HASH_CAPACITY 456976 #define DIGIT_FIRST 17576 #define DIGIT_SECOND 676 #define DIGIT_THIRD 26 #define MOST_FREQUENT_NUM 10 long charactNum = 0, wordNum = 0, textLine = 0; MyWC *(ptrOfWord[HASH_CAPACITY]); MyGC *(ptrOfGroup[HASH_CAPACITY]);
2.打开单个文件或遍历文件夹下所有文件
vector<char *> getFilesList(const char *dir) { vector<char *> allPath; string dirNew; dirNew = dir; dirNew += "\*.*"; //add "*.*" to our directory for the first search intptr_t handle; //file's handle _finddata_t findData; //file's structure handle = _findfirst(dirNew.c_str(), &findData); //get file's handle if (-1 == handle) { dirNew = dir; handle = _findfirst(dirNew.c_str(), &findData); if (-1 == handle) { cout << "can not find the file : " << dir << endl; return allPath; } else { allPath.push_back(const_cast<char *>(dir)); return allPath; } } do { if (findData.attrib & _A_SUBDIR) //check of subdirectory { if (strcmp(findData.name, ".") == 0 || strcmp(findData.name, "..") == 0) continue; //add "" to our directory for next search dirNew = dir; dirNew += "\"; dirNew += findData.name; vector<char *> tempPath = getFilesList(dirNew.c_str()); //recursive search for subdirectory allPath.insert(allPath.end(), tempPath.begin(), tempPath.end()); //add files in subdirectory to the end of our list } else { string filePath; filePath = dir; filePath += '\'; filePath += findData.name; char *cString_filePath = new char[filePath.size()]; //change to cString type strcpy_s(cString_filePath, filePath.size() + 1, filePath.c_str()); allPath.push_back(cString_filePath); //add a file to the end of our list } } while (0 == _findnext(handle, &findData)); _findclose(handle); //close handle search return allPath; }
3.统计字符数、行数
bool Statistics_of_File(char *filePath) { ifstream operateFile; operateFile.open(filePath, ios::in); if (!operateFile.is_open()) //file open checking { cout << "can not open this file : " << filePath << endl; return(false); } string getWordL; string getWordN; MyWC *getFirst = NULL, *getSecond = NULL; intptr_t counter = 0; char singleCharact = 0; string singleLine; intptr_t flag = 1; //flag of word group while (!operateFile.eof()) { getline(operateFile, singleLine); textLine++; if (operateFile.eof() == NULL) singleLine += " "; for (size_t i = 0; i < singleLine.size(); i++) { singleCharact = singleLine[i]; if (singleCharact >= 32 && singleCharact <= 126) charactNum++; else singleCharact = ' '; if (isalpha(singleCharact) || (counter >= WORD_LIMIT && isdigit(singleCharact))) { counter++; if (flag) getWordL += singleCharact; else getWordN += singleCharact; } else { if (counter >= WORD_LIMIT) { if (flag) { getFirst = putIntoWordList(getWordL); flag = 0; counter = 0; getWordL = ""; } else { getSecond = putIntoWordList(getWordN); putIntoGroupList(getFirst, getSecond); getFirst = getSecond; counter = 0; getWordN = ""; } } else { counter = 0; getWordL = ""; getWordN = ""; } } } } operateFile.close(); return(true); }
4.统计单词数,并放进哈希散列表
MyWC *putIntoWordList(string getWord) { size_t offset = 0; string trimmedWord; MyWC *ptrTemp = NULL; offset = (tolower(getWord[0]) - 97) * DIGIT_FIRST; offset += (tolower(getWord[1]) - 97) * DIGIT_SECOND; offset += (tolower(getWord[2]) - 97) * DIGIT_THIRD; offset += tolower(getWord[3]) - 97; wordNum++; for (size_t i = getWord.size() - 1; i >= 0; i--) { if (isalpha(getWord[i])) { trimmedWord = ""; for (size_t j = 0; j <= i; j++) { trimmedWord += tolower(getWord[j]); } break; } } if (ptrOfWord[offset] == NULL) { ptrOfWord[offset] = new MyWC; ptrOfWord[offset]->word = getWord; ptrOfWord[offset]->trimmed = trimmedWord; ptrOfWord[offset]->number = 1; ptrOfWord[offset]->next = NULL; ptrTemp = ptrOfWord[offset]; } else { ptrTemp = ptrOfWord[offset]; while (1) { if (ptrTemp->trimmed == trimmedWord) { if (strcmp(ptrTemp->word.c_str(), getWord.c_str()) == 1) ptrTemp->word = getWord; ptrTemp->number++; break; } if (ptrTemp->next == NULL) { ptrTemp->next = new MyWC; ptrTemp = ptrTemp->next; ptrTemp->word = getWord; ptrTemp->trimmed = trimmedWord; ptrTemp->number = 1; ptrTemp->next = NULL; break; } else { ptrTemp = ptrTemp->next; } } } return ptrTemp; }
5.将词组放进哈希表
void putIntoGroupList(MyWC *getFirst, MyWC *getSecond) { size_t offset = 0; string wordF, wordS; wordF = getFirst->trimmed; wordS = getSecond->trimmed; MyGC *ptrTemp = NULL; offset = (tolower(getFirst->word[0]) - 97) * DIGIT_FIRST; offset += (tolower(getFirst->word[1]) - 97) * DIGIT_SECOND; offset += (tolower(getSecond->word[0]) - 97) * DIGIT_THIRD; offset += tolower(getSecond->word[1]) - 97; if (!ptrOfGroup[offset]) { ptrOfGroup[offset] = new MyGC; ptrOfGroup[offset]->firstWord = getFirst; ptrOfGroup[offset]->secondWord = getSecond; ptrOfGroup[offset]->number = 1; ptrOfGroup[offset]->next = NULL; ptrTemp = ptrOfGroup[offset]; } else { ptrTemp = ptrOfGroup[offset]; while (1) { if ((ptrTemp->firstWord)->trimmed == wordF && (ptrTemp->secondWord)->trimmed == wordS) { ptrTemp->number++; break; } if (!ptrTemp->next) { ptrTemp->next = new MyGC; ptrTemp = ptrTemp->next; ptrTemp->firstWord = getFirst; ptrTemp->secondWord = getSecond; ptrTemp->number = 1; ptrTemp->next = NULL; break; } else { ptrTemp = ptrTemp->next; } } } }
6.输出
ofstream outputFile("result.txt"); if (outputFile.is_open()) { outputFile << "characters: " << charactNum << endl; outputFile << "words: " << wordNum << endl; outputFile << "lines: " << textLine << endl << endl; outputFile << "the top ten frequency of word :" << endl; for (size_t i = 0; i < MOST_FREQUENT_NUM; i++) { intptr_t max = 0; string printWord; MyWC *ptrTemp = NULL; MyWC *clear = NULL; for (intptr_t j = 0; j < HASH_CAPACITY; j++) { ptrTemp = ptrOfWord[j]; while (ptrTemp != NULL) { if (ptrTemp->number > max) { max = ptrTemp->number; printWord = ptrTemp->word; clear = ptrTemp; } ptrTemp = ptrTemp->next; } } if (printWord != "") { clear->number = -1; outputFile << printWord << " " << max << endl; } else outputFile << "null" << endl; } outputFile << endl << "the top ten frequency of phrase :" << endl; for (size_t i = 0; i < MOST_FREQUENT_NUM; i++) { intptr_t max = 0; MyWC *printPhraseL = NULL, *printPhraseN = NULL; MyGC *ptrTemp = NULL; MyGC *clear = NULL; for (size_t j = 0; j < HASH_CAPACITY; j++) { ptrTemp = ptrOfGroup[j]; while (ptrTemp != NULL) { if (ptrTemp->number > max) { max = ptrTemp->number; printPhraseL = ptrTemp->firstWord; printPhraseN = ptrTemp->secondWord; clear = ptrTemp; } ptrTemp = ptrTemp->next; } } if (printPhraseL != NULL) { clear->number = -1; outputFile << printPhraseL->word << " " << printPhraseN->word << " " << max << endl; } else outputFile << "null" << endl; } } cout << "success!" << endl;
性能分析
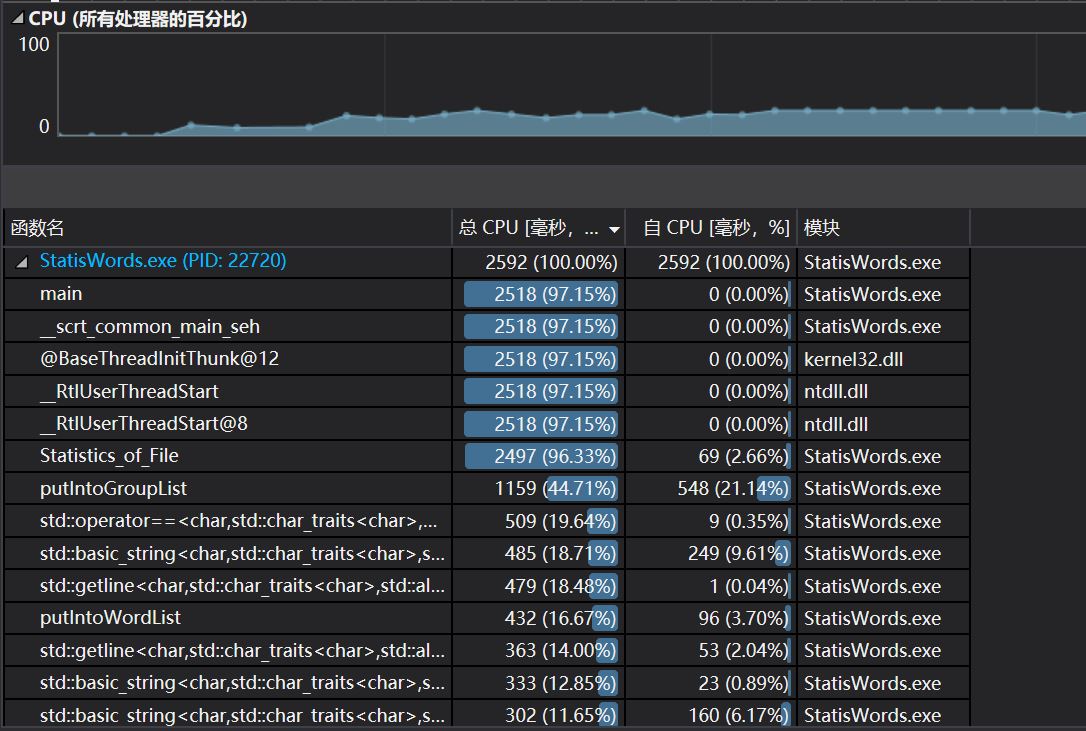
CPU性能及各函数调用时间
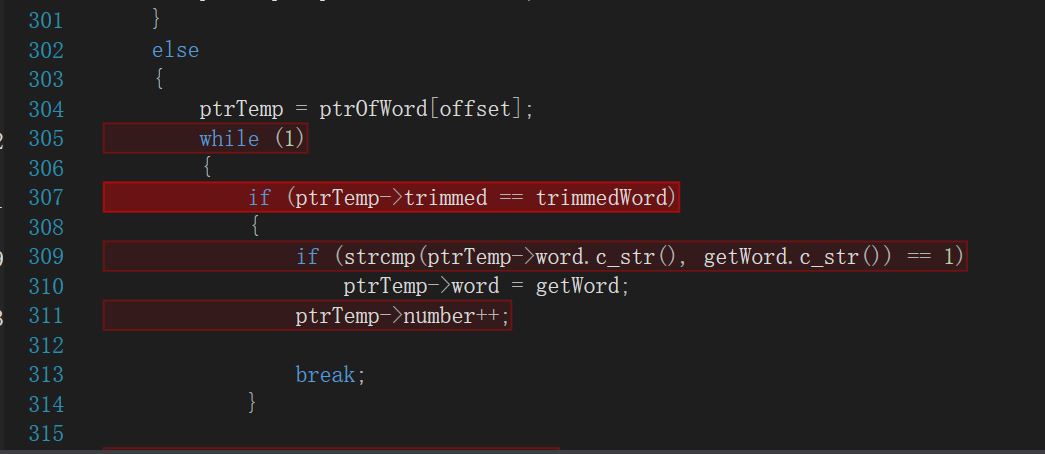
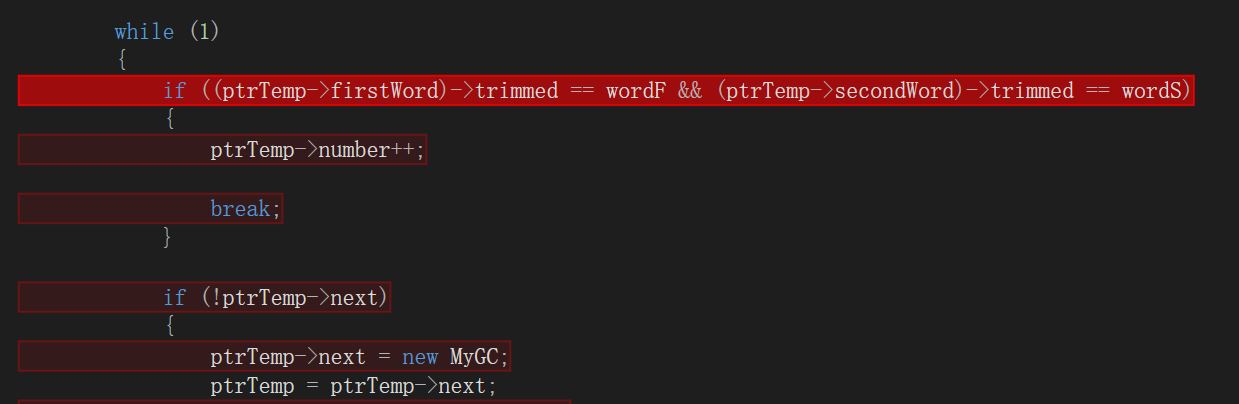
热行分析
可以看到,将单词、词组放进对应的哈希表中是最耗费时间的,原因可能是一些单词/词组会放进同一拉链表,新来的单词/词组要和已经存在的词组进行比较,而比较是一件好费时间的事情。
也就是说,这种哈希函数是不够好的,不能将相似的单词分散到不同的槽中,对应的解决方法我想到了如下两种方式:
(1)改进哈希函数,增加槽的数量,减少冲突发生的几率;
(2)改用其他的数据结构,比如<key,value>键值对。
白盒测试
sample 1:空文件
sample 2:只含一个单词的文件
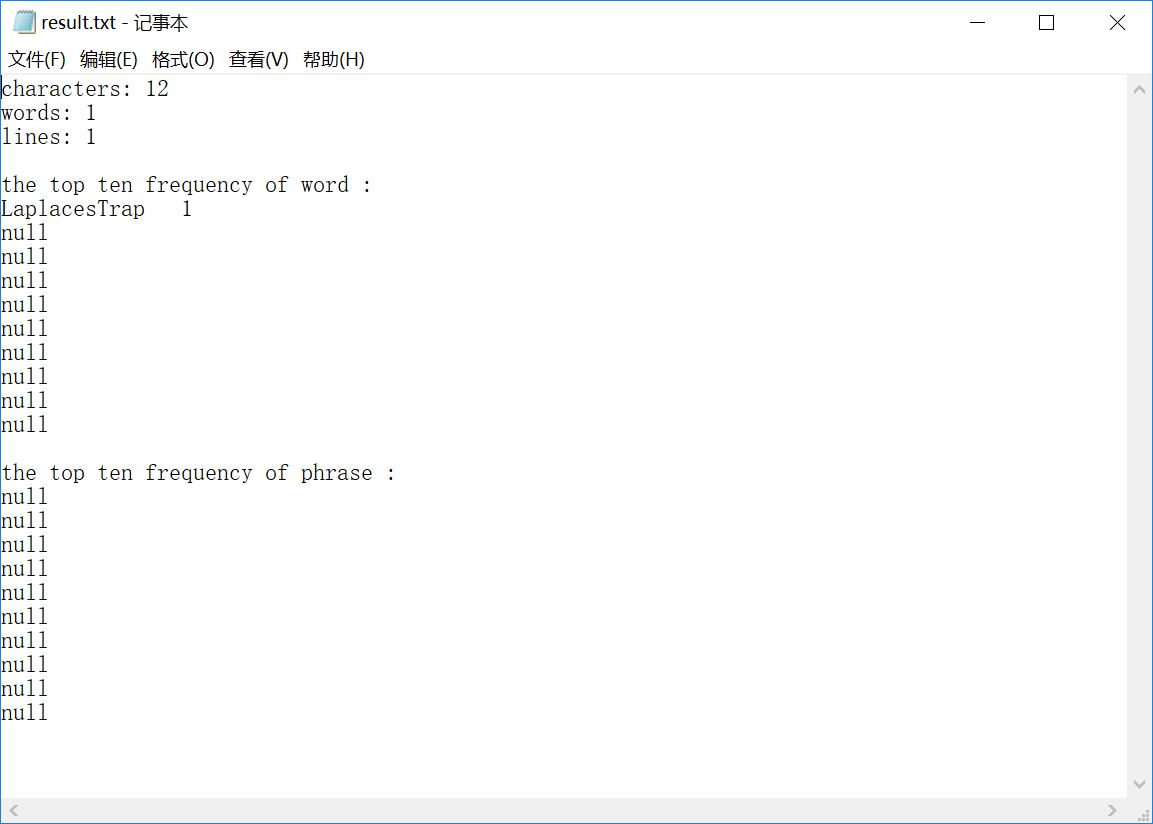
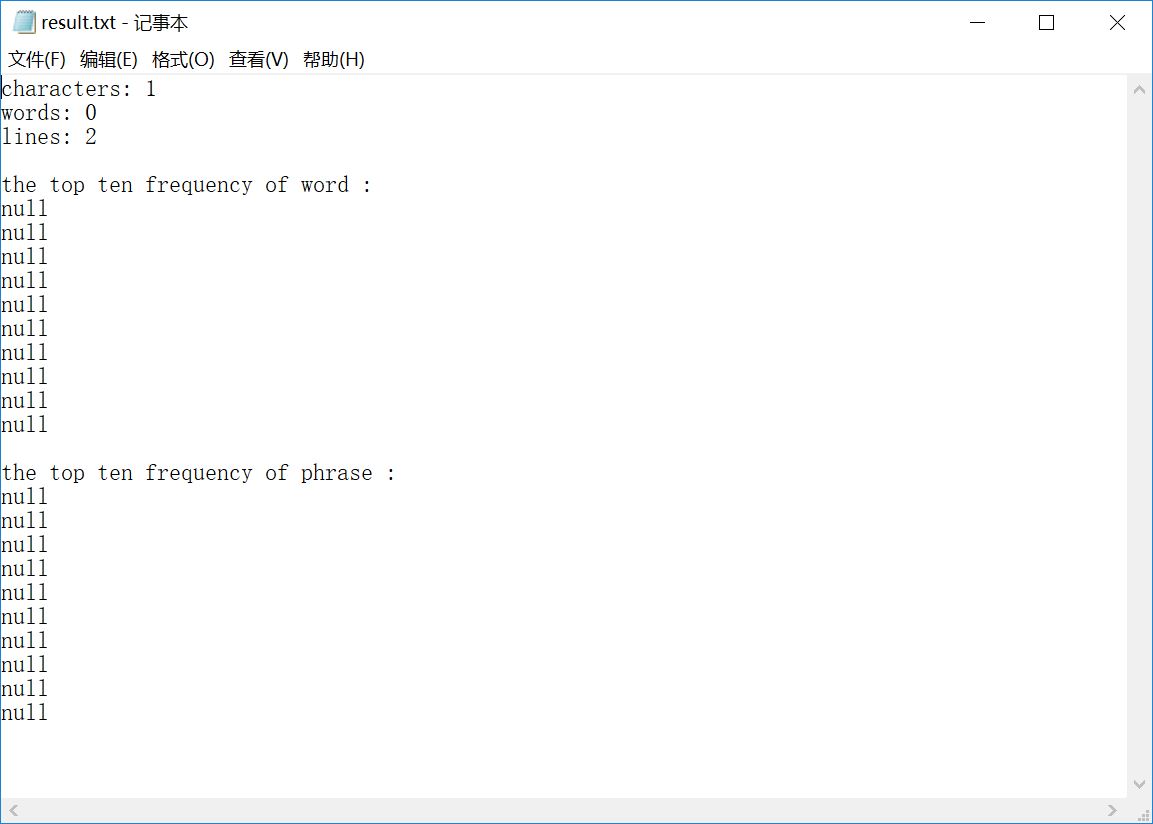
sample 3:只含一个换行符的文件
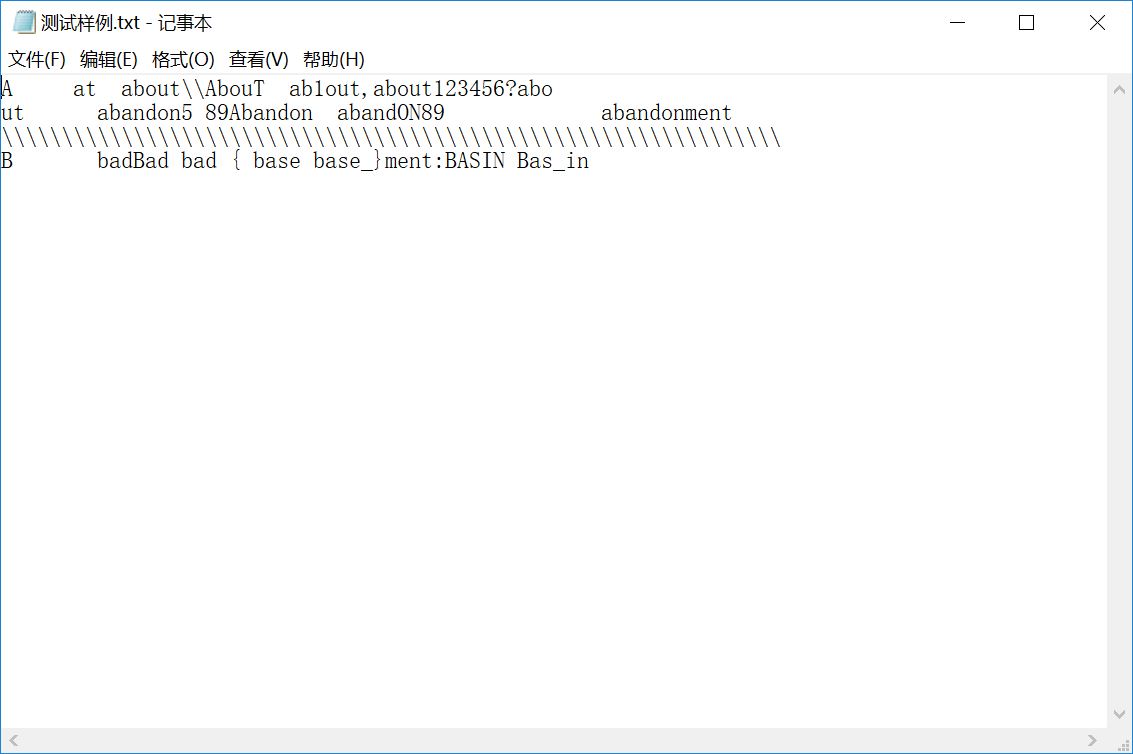
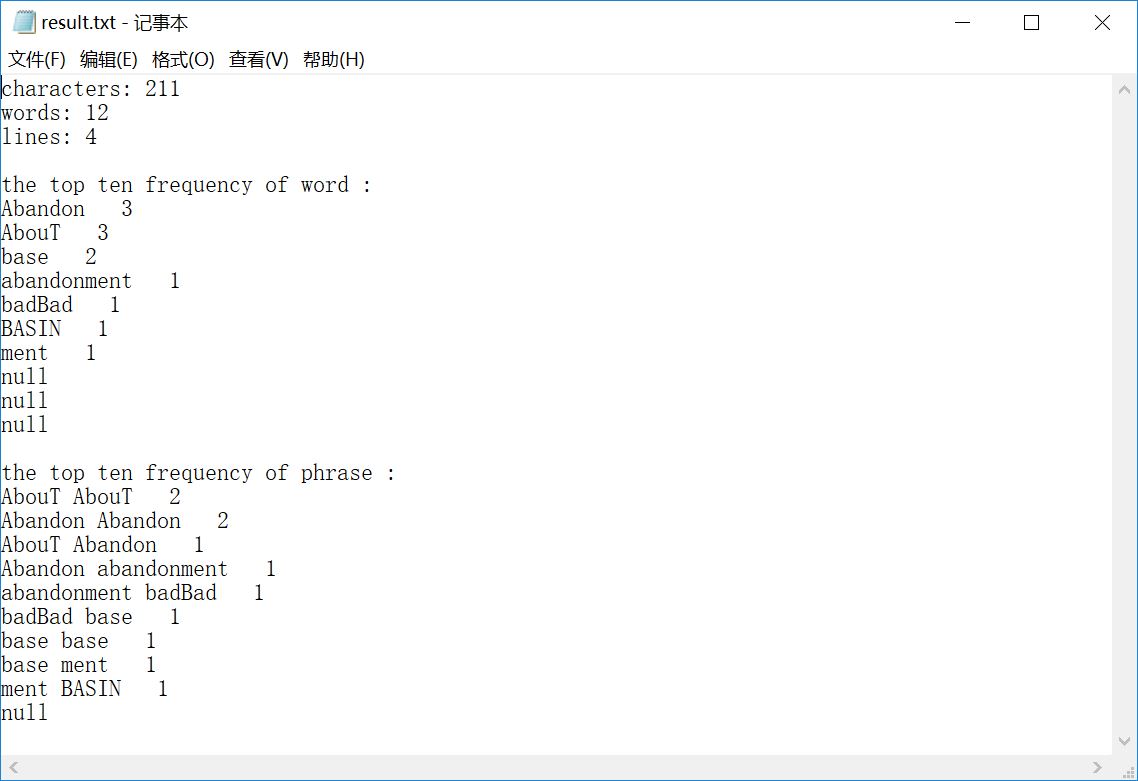
sample 4:含许多类似单词的文件
sample 5:错误文件路径
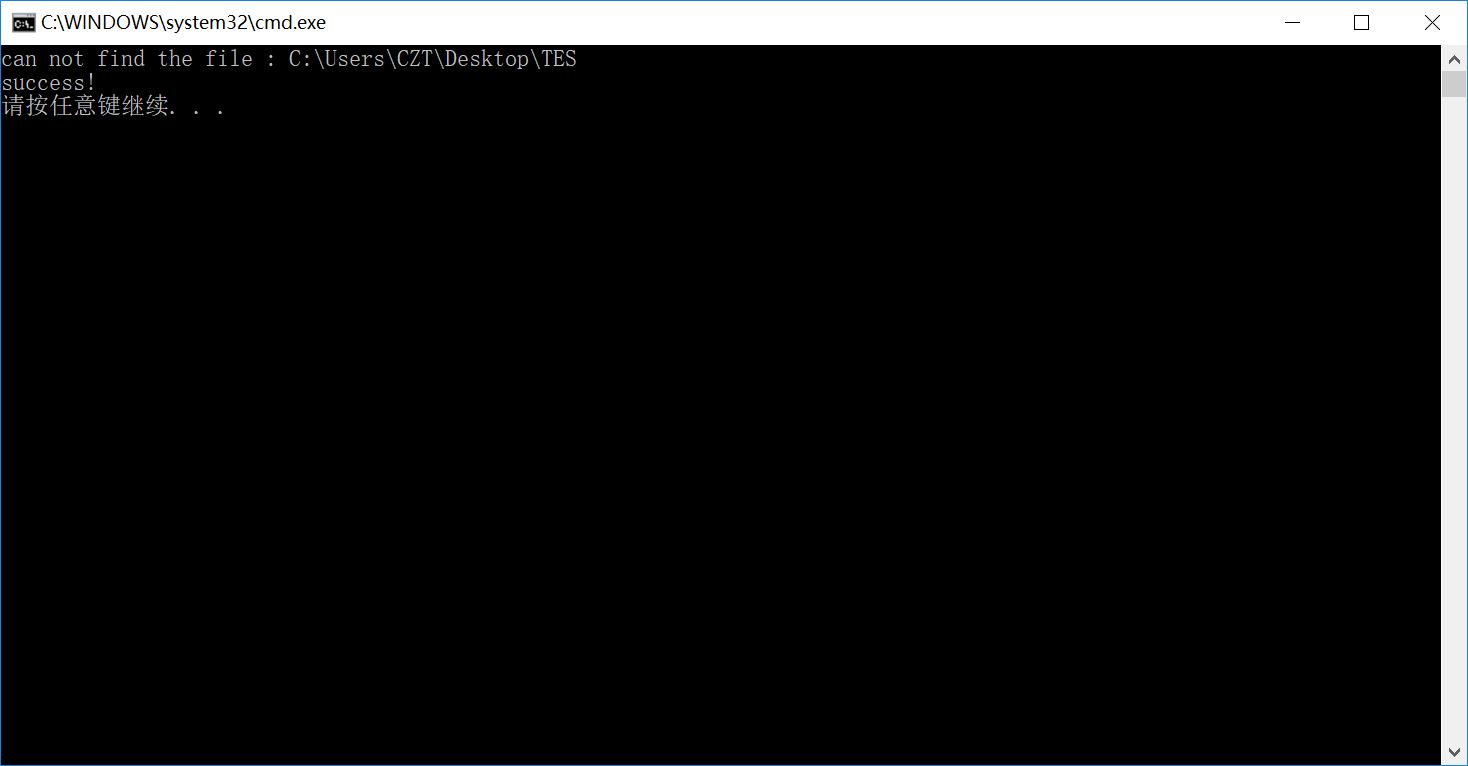
sample 6:空文件夹
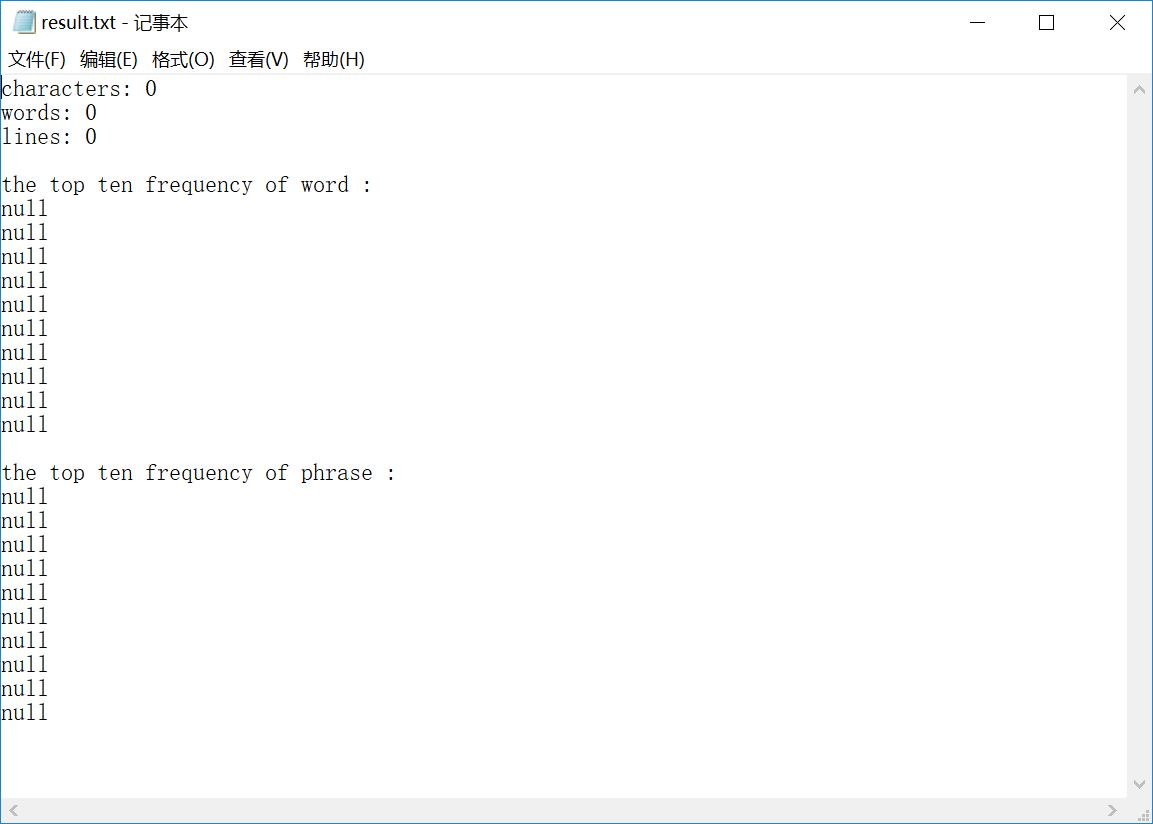
sample 7:多个文件
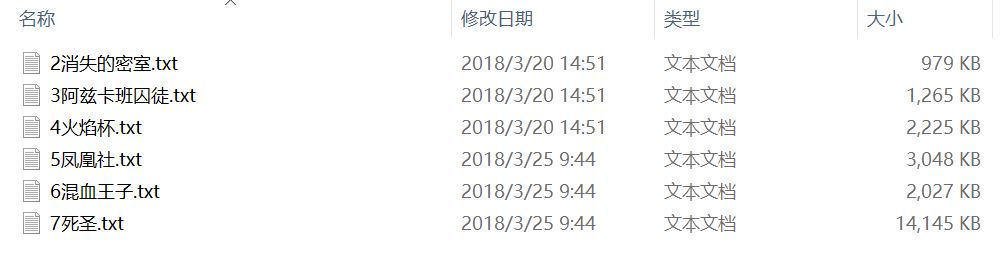

sample 8:多个文件夹/子文件夹

sample 9:奇怪的文件
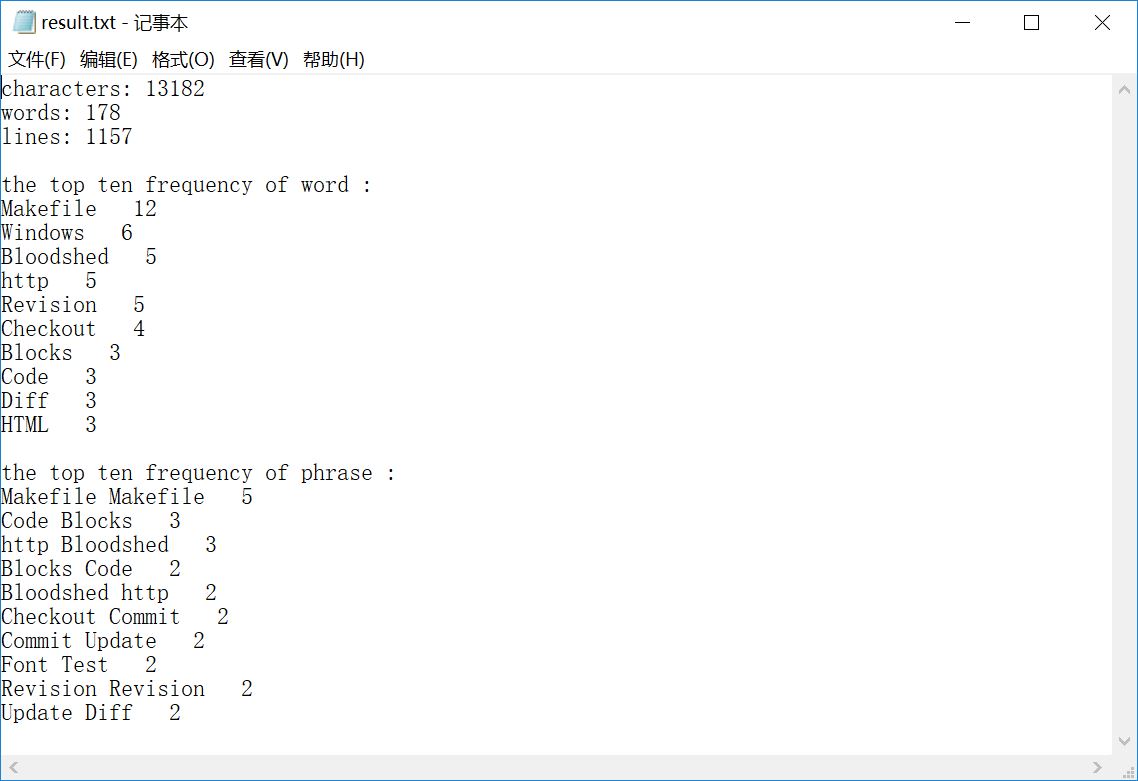
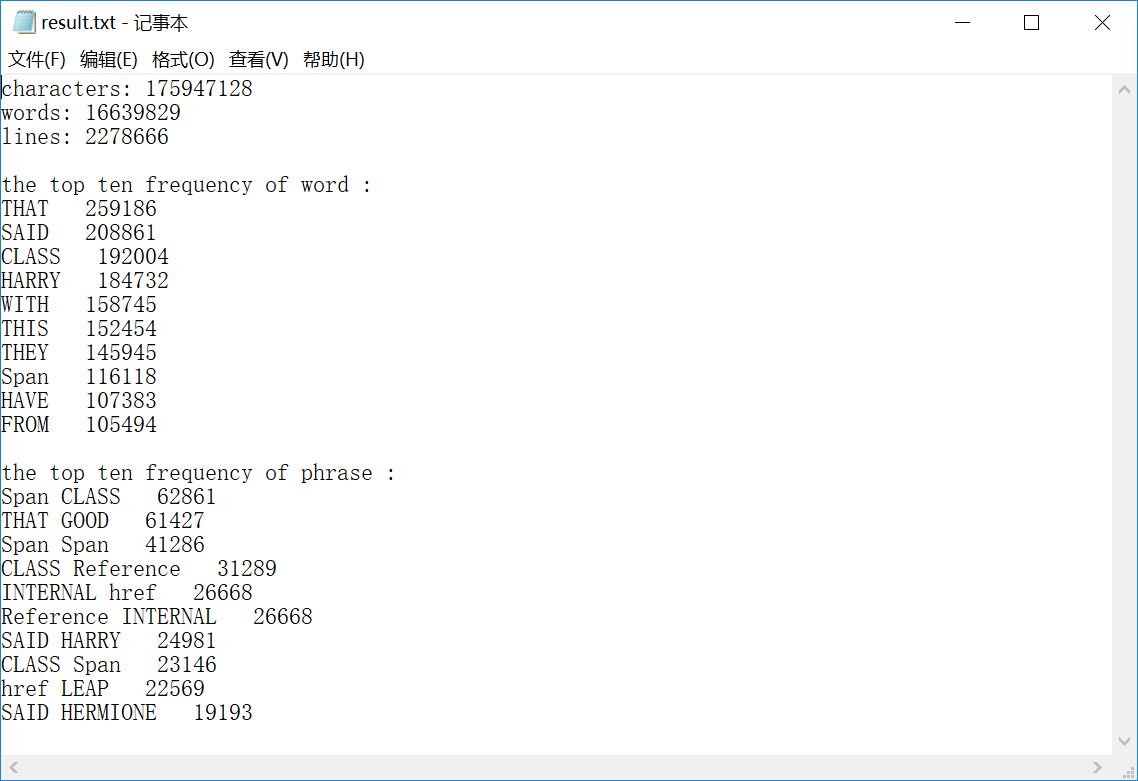
sample 10:助教的测试文件
总结&收获
这次作业从题目本身来讲不是很难,但想写一个健壮的程序确实不易。
同时,这是我第一次尝试用C++来写程序,虽然有一些不规范的地方,但通过上网查资料解决问题,我还是把程序赶出来了。
之前,我一直都是在编译器上运行,没有使用过命令行,也很少读写文件,这次的作业锻炼了我在多平台调试以及文件操作的能力。
附:PSP表
| Status | Stages | 预估耗时/min | 实际耗时/min |
| Accept | 【计划】 Planning | 60 | 80 |
| Accept | ——估计时间 Estimate | 60 | 90 |
| Accept | 【开发】 Development | 800 | 1200 |
| Accept | ——需求分析 Analysis | 10 | 0 |
| Accept | ——设计文档 Design Spec | 40 | 20 |
| Accept | ——设计复审 Design Review | 10 | 10 |
| Accept | ——代码规范 Coding Standard | 10 | 10 |
| Accept | ——具体设计 Design | 60 | 30 |
| Accept | ——具体编码 Coding | 480 | 600 |
| Accept | ——代码复审 Code Review | 60 | 120 |
| Accept | ——测试 Test | 120 | 120 |
| Accept | 【记录用时】 Record Time Spent | 20 | 10 |
| Accept | 【测试报告】 Test Report | 60 | 40 |
| Accept | 【算工作量】 Size Measurement | 20 | 20 |
| Accept | 【总结改进】 Postmortem | 40 | 30 |
| Accept | 【合计】 Summary | 1850 | 2380 |