beautifulsoup4 库是一个解析和处理HTML 和XML 的第三方库。
①使用requests 库获取HTML 页面并将其转换成字符串后,需要进一步解析HTML页面格式,提取有用信息,这需要处理HTML 和XML 的函数库。 beautifulsoup4 库,也称为Beautiful Soup 库或bs4 库,用于解析和处理HTML和XML。需要注意,它不是BeautifulSoup 库。它的最大优点是能根据HTML 和XML 语法建立解析树,进而高效解析其中的内容。
HTML 建立的Web 页面一般非常复杂,除了有用的内容信息外,还包括大量用于页面格式的元素,直接解析一个Web 网页需要深入了解HTML 语法,而且比较复杂。beautifulsoup4 库将专业的Web 页面格式解析部分封装成函数,提供了若干有用且便捷的处理函数。
②beautifulsoup4 库采用面向对象思想实现,简单说,它把每个页面当做一个对象,通过<a>.<b>的方式调用对象的属性(即包含的内容),或者通过<a>.<b>()的方式调用方法(即处理函数)。
③在使用beautifulsoup4 库之前,需要进行引用,由于这个库的名字非常特殊且采用面向对象方式组织,可以用from…import 方式从库中直接引用BeautifulSoup 类,方法如下。 >>>from bs4 import BeautifulSoup
④创建的BeautifulSoup 对象是一个树形结构,它包含HTML 页面里的每一个Tag(标签)元素,如<head>、<body>等。具体来说,HTML 中的主要结构都变成了BeautifulSoup 对象的一个属性,可以直接用<a>.<b>形式获得,其中<b>的名字采用HTML 中标签的名字。
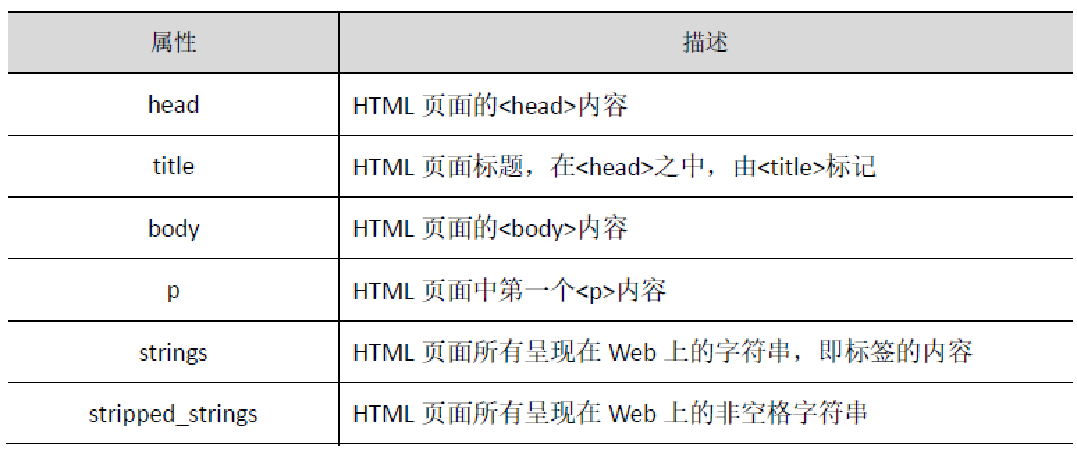
⑤每一个Tag 标签在beautifulsoup4 库中也是一个对象,称为Tag 对象。上例中,title 是一个标签对象。其中,尖括号(<>)中的标签的名字是name,尖括号内其他项是attrs,尖括号之间的内容是string。因此,可以通过Tag 对象的name、attrs 和string 属性获得相应内容,采用<a>.<b>的语法形式。 标签Tag 有4 个常用属性


⑥ 由于HTML 语法可以在标签中嵌套其他标签,所以,string 属性的返回值遵循如下原则: 如果标签内部没有其他标签,string 属性返回其中的内容; 如果标签内部有其他标签,但只有一个标签,string 属性返回最里面标签的内容; 如果标签内部有超过1 层嵌套的标签,string 属性返回None(空字符串)。HTML 语法中同一个标签会有很多内容,例如<a>标签,百度首页一共有13 处,直接调用soup.a 只能返回第一个。当需要列出标签对应的所有内容或者需要找到非第一个标签时,需要用到BeautifulSoup 的find()和find_all()方法。这两个方法会遍历整个HTML 文档,按照条件返回标签内容。
代码:
1 from bs4 import BeautifulSoup 2 r='''<!DOCTYPE html> 3 <html> 4 <head> 5 <meta charset="utf-8"> 6 <title>菜鸟教程(runoob.com)</title> 7 </head> 8 <body> 9 <hl>我的第一个标题</hl> 10 <p id="first">我的第一个段落。</p> 11 </body> 12 <table border="1"> 13 <tr> 14 <td>row 1, cell 1</td> 15 <td>row 1, cell 2</td> 16 </tr> 17 <tr> 18 <td>row 2, cell 1</td> 19 <td>row 2, cell 2</td> 20 <tr> 21 </table> 22 </html>''' 23 soup= BeautifulSoup(r) 24 print("head标签内容:") 25 print(soup.head) 26 print("学号后两位:31") 27 print("body标签内容:") 28 print(soup.body) 29 print("id为first的标签:") 30 print(soup.find_all(id="first")) 31 print("html页面中的中文字符:") 32 print(soup.title.string) 33 print(soup.hl.string) 34 print(soup.p.string)
结果:
