一、分布式词表示(直接使用低维、稠密、连续的向量表示词)(静态的表示)
1、Word2Vec
- 训练方法:用中心词预测周围词。
- 局限性:Word2Vec产生的词向量只有每个单词独立的信息,而没有上下文的信息。
2、Glove
- Global Vector for Word Representation 利用全局统计信息,即共现频次。
- 构建共现矩阵:共现强度按照距离进行衰减。
二、词向量(动态的表示)
1、Cove(Contextualized WordVectors)
- 首次提出使用上下文相关的文本表示
- 主要思想:将神经机器翻译(NMT)的表示迁移到通用NLP任务上
- 训练阶段:训练一个神经机器翻译模型(NMT)
- 局限性:训练依赖于双语平行语料、单独使用效果一般,性价比不高,需要搭配传统静态词向量才能获得较为显著的性能提升
2、语言模型(BiLM、GPT、ELMo、BERT、XLNet、RoBERTa、ALBERT、Google T5、ELECTRA)
2.1、BiLM(双向语言模型)
- 从前向后两个方向同时建立语言模型
2.2、ELMo
- 三层双向LSTM语言模型(与当时使用越来越复杂的模型来得到好一点效果的模型相比是非常简单的模型)
- 预训练任务:双向语言模型
2.3、GPT(Generative Pre-Training)
- Transformer的decoder
- 自回归预训练模型的代表
- “生成式预训练”+“判别式近精调”框架
- “生成式预训练”:在大规模文本数据上训练一个高容量的语言模型;“判别式近精调”:将训练好的模型适配到下游任务中,并使用由标注数据学习判别式任务。
2.4、BERT
- Transformer的encoder(Encoded是可以并行计算的,LSTM是从左往右一步步计算的)
- 自编码预训练模型代表
- 模型层数更深:24层Transformer(每一层都有不同的参数)
- 训练数据量很大,TPU大算力加持
- 预训练任务:Masked Language Model(MLM,掩码语言模型)、Next Sentence Prediction(NSP,下一个句子预测)
- GPT:单向的从左至右的Transformer语言模型。
- ELMo:将独立的前向和后向的LSTM语言模型拼接所得。
- BERT:双向Transformer语言模型。
2.5、XLNet(Transformer-XL Net)
- 双流自注意力机制,可以捕获双向上下文的基于自回归的语言模型建模方法。
- 解决了BERT中存在的“预训练-精调”不一致的问题
2.6、RoBERTa(加强版EBERT)
- 加大训练数据16GB->160GB,更大的batch size,更长的训练时间
- 不需要NSP Loss
- 更长的训练Sequence
- Static -> Dynamic Masking (动态掩码,每次是不同的单词mask)
2.7、ALBERT
- 一个轻量级的BERT模型(A Lite BERT)
- 主要技术:词向量因式分解、跨层参数共享(24层用相同的参数,把参数量减小)
- 词向量因式分解:O(V * H)-> O(V*E+E*H)在BERT中,embedding_size==hidden_size;在ALBERT中,embedding_size<hidden_size.
- 训练时虽然参数共享,但每层的梯度是不同的,仍然需要额外的存储空间存储;推断时,前向计算仍然一层层展开,并不能节省推断时间。
2.8、Google T5
- 非常大规模且干净的预训练数据集 C4(745GB)
- BERT的训练目标
- 随机采样15%的span作为mask
- 更大的模型T5-11B
2.9、ELECTRA
- 一个新的思路:使用GAN的训练思路(一个生成器、一个判别器),把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。
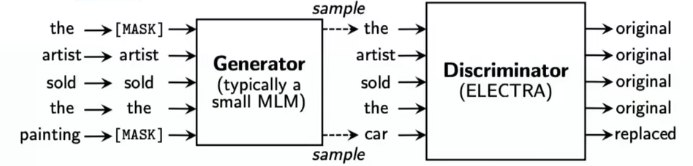
- 对于一段文本,我们随机Mask一些单词。Generator会预测这些被Mask的位置。
- Discrimnator的任务是预测测每个位置的单词是来自于原文还是来自于Generator生成的文本。
3、长文本处理
3.1、Transformer-XL
- Transformer中处理长文本的传统策略是将文本切分成固定长度的块,并单独编码每个块,块与块之间没有信息交互。
- Transformer-XL提出两种该进策略:状态复用的块级别循环、相对位置编码。
3.2、Reformer
- 引入了局部敏感哈希注意力(LSH)和可逆Transformer技术,有助于减少模型的内存占用,进一步提升了模型对长文本的处理能力。
- LSH:高效计算与每个词关联度最高的n个词。
3.3、Longformer
- 基于稀疏注意力机制。最大可处理长度扩展至4096
- 三种稀疏注意力模式:滑动窗口注意力、扩张滑动窗口注意力、全局+滑动窗口
3.4、BigBird
- 同样借鉴了稀疏注意力的方法:结合了三种不同注意力模式:随机注意力、滑动窗口注意力、全局注意力。
三、模型蒸馏与压缩
1、为什么需要蒸馏?
预训练模型通常需要占用很大的空间,并且训练和推断时间也很慢;直接在实际产品或应用中使用预训练模型难以满足时间和空间需求;知识蒸馏技术可以在不损失或少量损失性能的基础上,将大模型的知识迁移到小模型,从而提升推断速度。
2、DistilBERT
- 通用、任务无关的BERT(6层),相比BERT-base,小40%,快60%,在NLU任务上可达到原模型的97%。
- 使用MLM预训练任务进行知识蒸馏(无NSP)。
- 训练目标:由数据集自带的硬标签计算的有监督MLM损失、由教师模型提供的软标签计算的蒸馏MLM损失、教师模型和学生模型隐层输出之间的余弦相似度损失。
- 总损失:有监督的MLM损失+蒸馏MLM损失+词向量余弦损失。
3、TinyBERT
- 对BERT不同层进行匹配的蒸馏策略。
- 提出了两阶段蒸馏策略,在预训练和精调阶段均进行知识蒸馏。
- TinyBERT能达到教师模型BERT-base的96%的效果(GLUE),大小只有教师的13.3%
- 蒸馏的损失由三部分组成:词向量损失、中间层损失、预测层损失。
4、MobileBERT
- 在自注意力和前馈神经网络的设计上也有一定的改进,与BERT-large深度相同但更“苗条”。
- 蒸馏损失:MLM损失+隐含层匹配损失+注意力匹配损失。
- 渐近式知识迁移:
- 词向量层和最终分类输出层的权重是直接从教师模型拷贝至学生模型的,始终不参与参数更新;
- 对于中间的Transformer层,采用了渐近式逐步训练;
- 当学生模型学习教师模型的第X层时,学生模型中是所有小于X层的权重均不参与更新。
5、TextBrewer(An Open-Source Knowledge Distillation Toolkit)
- 推出首个面向自然语言处理领域的基于Pythorch的知识蒸馏工具包。
- 准备工作:训练教师模型,定义并初始化学生模型。构造蒸馏用数据集的DataLoader.
- 知识蒸馏:初始化Distiller,构造训练配置和蒸馏配置。定义adaptors和callback,分别用于适配模型输入输出和训练过程中的回调。调用Distiller的train方法开始蒸馏。
四、生成模型
1、BART
- 采用了经过细微调整的基于Transformer的序列到序列结构。
- 结合双向的Transformer编码器与单向的自回归Transformer解码器,通过对含有噪声的输入文本去噪重构进行预训练,是一种典型的去噪自编码器。
- 训练过程:双向编码器编码带噪音的文本,用单向自回归编码器重构文本。
- 预训练任务:单词掩码、单词删除、句子排列变换、文档旋转变换、文本填充
- 模型精调:序列分类、序列标注、文本生成、机器翻译
2、UniLM
- 只用一个Transformer就可以同时完成语言表示和文本生成的预训练。
- 可同时应用于语言理解任务和文本生成任务。
- 核心思想:使用不同的注意力掩码矩阵,控制每个词的注意力范围,从而实现不同的语言模型对于信息流的控制。
- 可以利用双向语言模型,单向语言模型、序列到序列语言模型进行预训练。
3、T5(Text-to-Text Transfer Transformer)
- 提出了一种适用于各种类型的NLP任务的Encoder-Decoder框架。
- 提供了非常细致的模型设计决策过程。
- 提出了C4数据集,包含750G高质量英文数据。
- 提出了一种基于span-corruption的无监督训练任务。
- input:对句子的若干文本片段进行mask;output:预测被mask的文本片段
4、GPT-3(Language Models are Few-Shot Learners)
- 展示了超大规模语言模型在小样本学习few-shot learning上的能力。
- 模型参数量进一步扩展至175B,预示着预训练进入到超大规模时代。
- 传统预训练模型:直接在下游任务数据上精调。
- GPT-3类超大规模模型:zero-shot、one-shot、few-shot
5、可控文本生成:CTRL
- 可以根据指定的领域、风格、主题、实体和实体关系等属性生成相应文本。结构上仍然是一个基于Transformer的自回归语言模型。
- 核心思想:从海量无标注数据中定位文章所在的领域或其他属性,并作为控制代码,放在输入文本的头部,以指导后续文本的生成。
6、可控文本生成:PPLM
- 提供一种无需重新训练,且即插即用的方法实现可控的文本生成。
- 核心思想:对于预训练语言模型(GPT-2)以及目标属性a,利用当前的生成结果是否满足属性a,对生成进行修正,使其朝着满足该属性的方向变化。