分词器需求场景
在线动态更新词库,查询 把悲伤留给自己 ,不能查出 悲伤、自己 之类关联的文档
官网地址
https://github.com/medcl/elasticsearch-analysis-ik
实现案例
分词器设置
采用 ik 分词器,使用 nginx 代理一个简单的在线词库,
IK分词器安装很简单,直接下载丢到 ES 的 plugin 文件夹下重启 ES 即可;网络允许的话也可以使用在线安装指令./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip,需要注意的是版本对应。
- ik 分词器配置 plugins/ik_analyzer/config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<!-- <entry key="ext_dict">extra_main.dic;extra_single_word.dic;extra_single_word_full.dic;extra_single_word_low_freq.dic</entry> -->
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://172.31.1.204:1180/dic/extra_main.dic,http://172.31.1.204:1180/dic/extra_single_word.dic,http://172.31.1.204:1180/dic/extra_single_word_full.dic,http://172.31.1.204:1180/dic/extra_single_word_low_freq.dic,http://172.31.1.204:1180/dic/ik.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
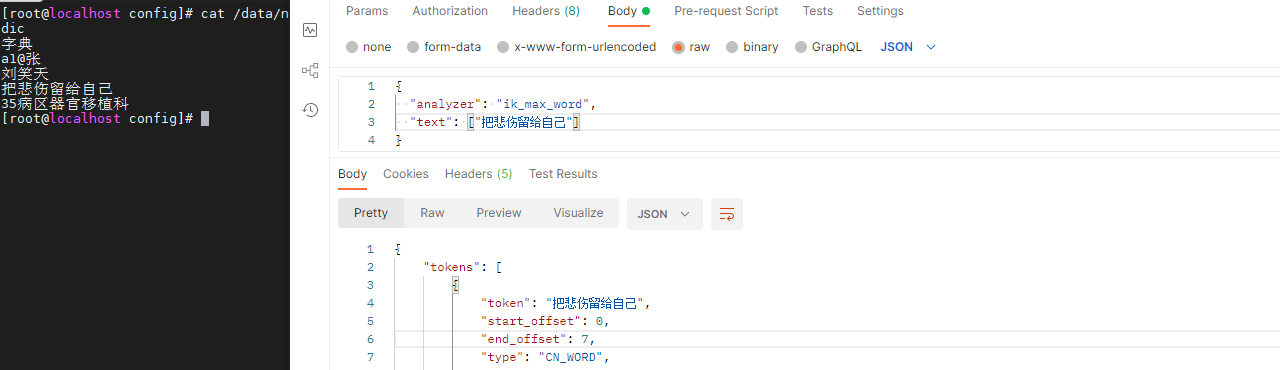
- nginx 代理词库
- 需要先随便启动个 nginx 容器,把需要的文件复制到外挂目录。
- 在外挂目录下配置 nginx 代理词库
- 启动容器
docker run --name nginx \ -p 1080:80 \ -p 1180:180 \ -v /data/nginx/html:/usr/share/nginx/html \ -v /data/nginx/modules:/usr/lib/nginx/modules \ -v /data/nginx:/etc/nginx \ nginx:1.21.6
同义词需求场景
查询 土豆 要能得到 马铃薯
官网地址
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/indices-reload-analyzers.html
实现案例
本文使用了 ik 分词器,不知道怎么安装 ik 分词器的去这里:https://github.com/medcl/elasticsearch-analysis-ik
# 第一步,配置索引
PUT /my-index-000001
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_synonyms": {
"tokenizer": "ik_smart",
"filter": [ "synonym" ]
}
},
"filter": {
"synonym": {
"type": "synonym_graph",
"synonyms_path": "analysis/synonym.txt",
"updateable": true
}
}
}
}
},
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "my_synonyms"
}
}
}
}
# 第二步,初始化数据
POST _bulk
{"index":{"_index":"my-index-000001","_id":1}}
{"key1":"1","key2":"11","key3":"111","text":"blue"}
{"index":{"_index":"my-index-000001","_id":2}}
{"key1":"2","key2":"22","key3":"2222","text":"2222"}
{"index":{"_index":"my-index-000001","_id":3}}
{"key1":"3","key2":"33","key3":"333","text":"3333"}
{"index":{"_index":"my-index-000001","_id":4}}
{"key1":"4","key2":"44","key3":"444","text":"4444"}
# 第三步,添加同义词,如果是集群,请修改所有节点上的同义词配置文件
vim /data/elasticsearch1/config/analysis/synonym.txt
# 第四步,刷新分词器,这回重新加载分词器下的同义词
POST /my-index-000001/_reload_search_analyzers
# 清理缓存,重新加载搜索分析器后,您应该清除请求缓存以确保它不包含从以前版本的分析器派生的响应
POST /my-index-000001/_cache/clear?request=true