一、UA池和代理池
1、UA池
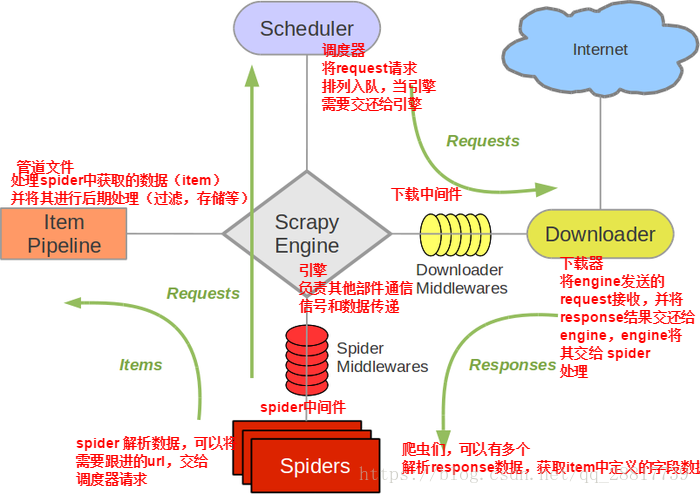
scrapy的下载中间件:
下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件。
作用:
(1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系列处理。比如设置请求的 User-Agent,设置代理等
(2)在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列处理。比如进行gzip解压等。
我们主要使用下载中间件处理请求,一般会对请求设置随机的User-Agent ,设置随机的代理。目的在于防止爬取网站的反爬虫策略。
UA池作用:尽可能多的将scrapy框架中的请求伪装成不同类型的浏览器以及不同电脑的身份。
- 操作流程:
1.下载中间件中拦截请求
2.将拦截到的请求的请求头信息中的UA进行伪装
3.在配置文件中开启下载中间件
代码展示:(只需要看proccess_request方法)
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://docs.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals from scrapy.http import HtmlResponse import random from time import sleep class WangyixinwenDownloaderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] # 代理池 PROXY_http = [ '153.180.102.104:80', '195.208.131.189:56055', ] PROXY_https = [ '120.83.49.90:9000', '95.189.112.214:35508', ] def process_request(self, request, spider): """ 在这里可以设置UA,如果要设置IP就需要等自己IP出现问题再前去process_exception中设置代理IP 但最后一定要返回request对象 :param request: :param spider: :return: """ # ua = random.choice(self.user_agent_list)#随机选择一个元素(反爬策略(即不同浏览器和机型))出来 # request.headers["User-Agent"] = ua #return request#将修正的request对象重新进行发送 return None def process_response(self, request, response, spider): #刚才响应体缺失,因此从这里我们应该重新返回新的响应体 #这里要用到爬虫程序中的urls,判断url是否在里面,在urls里面的就会出现响应缺失, # 、因此需要返回新的响应体 if request.url in spider.urls: #响应缺失是因为是动态加载数据,因此我们配合selenium使用 #在这里实例化selenium的话会被实例化多次,然而selenium只需要实例化一次, #这个时候我们可以将selenium放在实例化一次的爬虫程序开始的时候,实例化完成引入 sleep(2) bro = spider.bro.get(url=request.url)#浏览器中发送请求 sleep(1) spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)") sleep(1.5) spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)") sleep(0.7) spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)") sleep(1) spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)") #发送到请求我们需要获取浏览器当前页面的源码数据 获取数据之前需要翻滚页面 page_text = spider.bro.page_source #改动返回响应对象 scrapy提供了一个库url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request new_response = HtmlResponse(url=request.url,body=page_text,encoding="utf-8",request=request) return new_response else: return response #提交完新的响应体之后,去设置将下载中间件打开 def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain #如果抛出异常,那么就换代理IP # 代理ip的设定 # if request.url.split(':')[0] == 'http': # request.meta['proxy'] = random.choice(self.PROXY_http) # else: # request.meta['proxy'] = random.choice(self.PROXY_https) # # 将修正后的请求对象重新进行请求发送 # return request pass
然后去配置文件开启中间件settings.py:
# Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'Wangyixinwen.middlewares.WangyixinwenDownloaderMiddleware': 543, }
2、代理池
作用:尽可能多的将scrapy框架中的请求的IP设置成不同的,当服务器禁止自己电脑的ip的时候将自动调用process_exception中的ip代理设置
操作流程:
1.在下载中间件中拦截请求
2.将拦截到的请求的IP修改成某一代理IP
3.在配置文件中开启下载中间件
def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain #如果抛出异常,那么就换代理IP # 代理ip的设定 if request.url.split(':')[0] == 'http': request.meta['proxy'] = random.choice(self.PROXY_http) else: request.meta['proxy'] = random.choice(self.PROXY_https) # 将修正后的请求对象重新进行请求发送 return request
# Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'Wangyixinwen.middlewares.WangyixinwenDownloaderMiddleware': 543, }
拦截请求直接在上面中间件代码的process_exception中,配置文件也在上面。