前段时间在看css反爬的时候,发现很多网站都做了css反爬,比如,设置字体反爬的(58同城租房版块,实习僧招聘https://www.shixiseng.com/等)设置雪碧图反爬的(自如租房http://gz.ziroom.com/)。
还有一个网站本身是没有其他反爬措施的,只是设置了字体反爬,但是这个网站的反爬就有些扯淡,http://www.qiwen007.com/,我们随便点开一个文章,并打开开发者工具
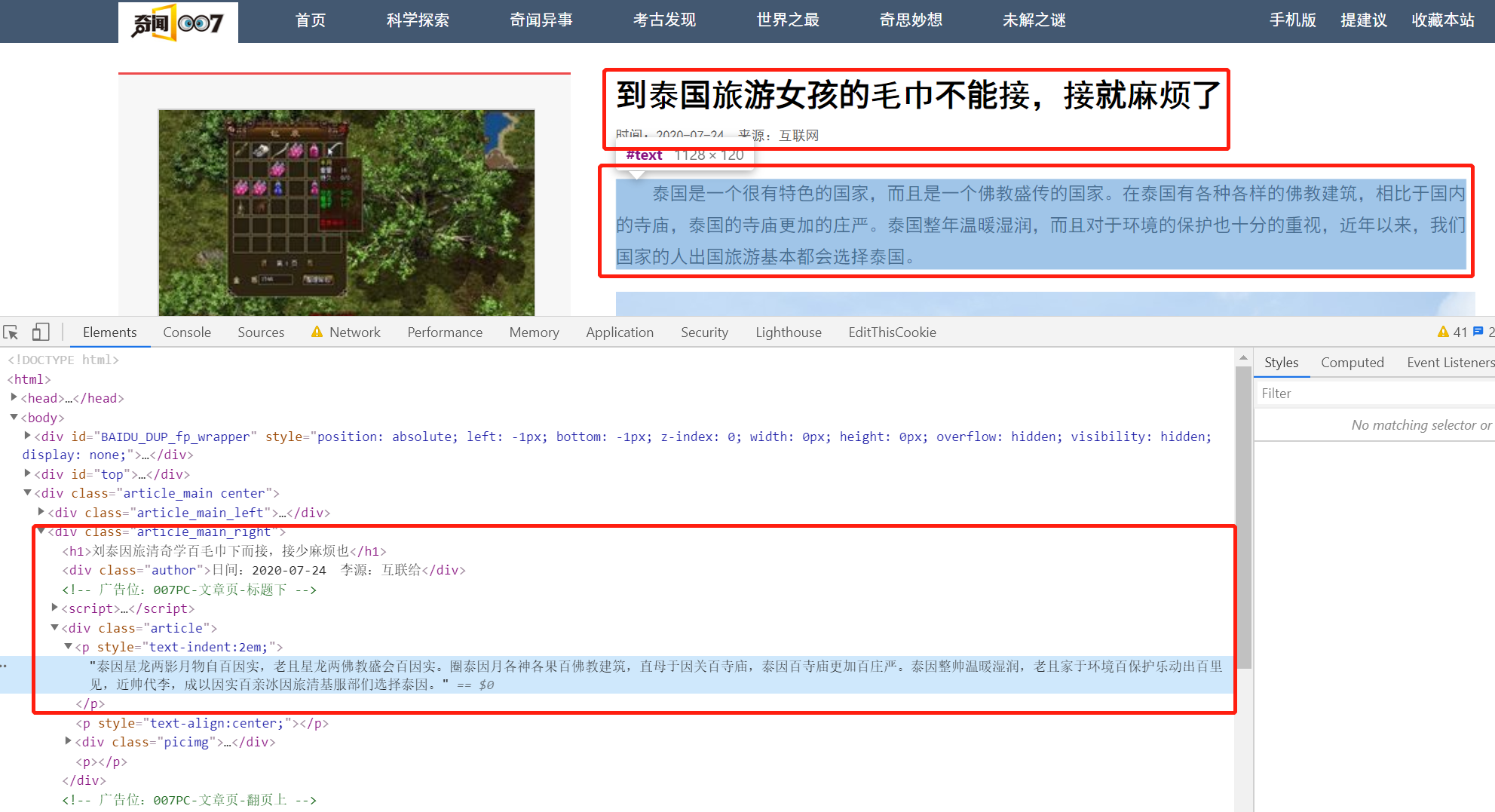
其中的文字并不是像其他字体反爬一样,是将某些文字转为了Unicode显示在源码中的
首先来看一下破解流程及思路:
"""
流程及思路:
1. 通过requests请求获取响应数据,得到的就是源码中加密数据(杂乱的文章)
2. 将加密数据的每一个字符转成Unicode编码,得到字符的Unicode列表
3. 通过搜索源码中font-face关键字,找到字体库文件(ttf/woff文件)将当前域名拼接上/hansansjm.ttf,即 http://www.qiwen007.com/hansansjm.ttf,打开后即下载
4. 使用FontCreator或者百度字体编辑器打开ttf文件,会看到里面每个字符
5. 将ttf转为xml文件
6. 同时使用pycharm打开xml文件,找到 glyf 标签下面的 TTGlyph 标签,里面的name 即是xml文件中的Unicode编码,
里面contour下面的pt的x,y即是每个字符的坐标,计算坐标差(计算坐标差的时候,可以直接取第一个contour的前两组pt即可)
(但是 TTGlyph name的顺序 有可能和ttf文件里面的字符的Unicode顺序对应不上,此时就要从GlyphOrder里面看是否对应,
如果对应,就从GlyphOrder中获取每个xml文件中的每个字符的Unicode列表,然后遍历列表,从 glyf 中找到对应的坐标)
7. 手动去组成汉字字符的列表,然后使用映射(dict(zip()))得到汉字和坐标差的映射
8. 在第6步中我们可以获取Unicode和坐标差的映射
9. 然后回到第2步,拿到加密数据的Unicode编码列表后,去Unicode和坐标差的映射中找到对应的坐标差,拿到坐标差后找到对应的汉字
至此,破解过程结束
"""
这里说明一下,为什么加密内容转Unicode之后不能直接用的原因,因为加密内容的Unicode和ttf文件中的Unicode不对应

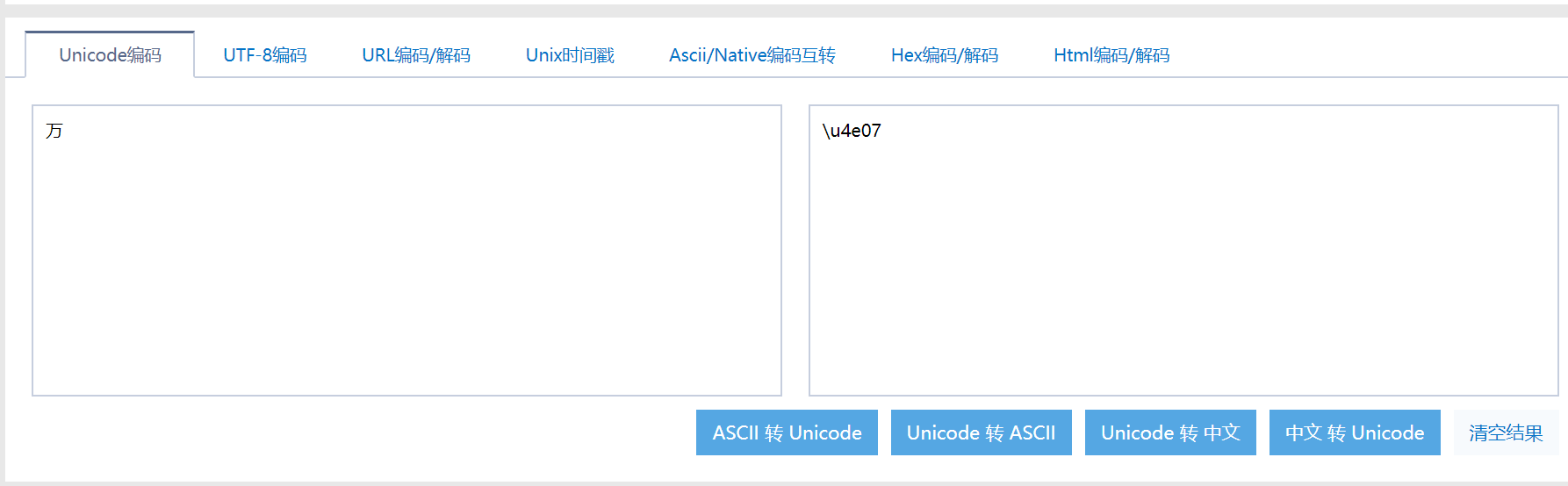
可以看到在ttf文件中万字的编码为uni2F00,而在Unicode在线编码中 为u4e07,uni 和 u 可忽略,直接看后四位,后面代码中有做转换
获取文章加密内容,及将每个字符转为Unicode编码
def get_source_article(): """获取加密文章内容""" url = 'http://www.qiwen007.com/mb-db/pc-sg/zbwz/363609.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36', } resp = requests.get(url=url, headers=headers) html = etree.HTML(resp.text) p_list = html.xpath('//div[@class="article"]/p') for p in p_list: temp_article = p.xpath('./text()') if len(temp_article) > 0: print('temp_article', temp_article) result = to_unicode(temp_article[0]) print('result', result) break def to_unicode(temp_article): """将汉字全部转为Unicode编码""" bytes_article = temp_article.encode(encoding='unicode-escape') str_article_li = str(bytes_article)[2:-1].split('\') uni_article_li = ['uni' + uni[1:].upper() for uni in str_article_li if uni != '']
print(uni_article_li)
将ttf文件或者woff文件转为xml文件
# 将ttf/woff文件转换为xml文件(ttf/woff文件pycharm打开是乱码,xml可以打开) from fontTools.ttLib import TTFont font = TTFont('hansansjm.ttf') # 此时就将ttf/woff文件转换为了xml文件 font.saveXML('hansansjm.xml')
坑:TTGlyph name的顺序 有可能和ttf文件里面的字符的Unicode顺序对应不上
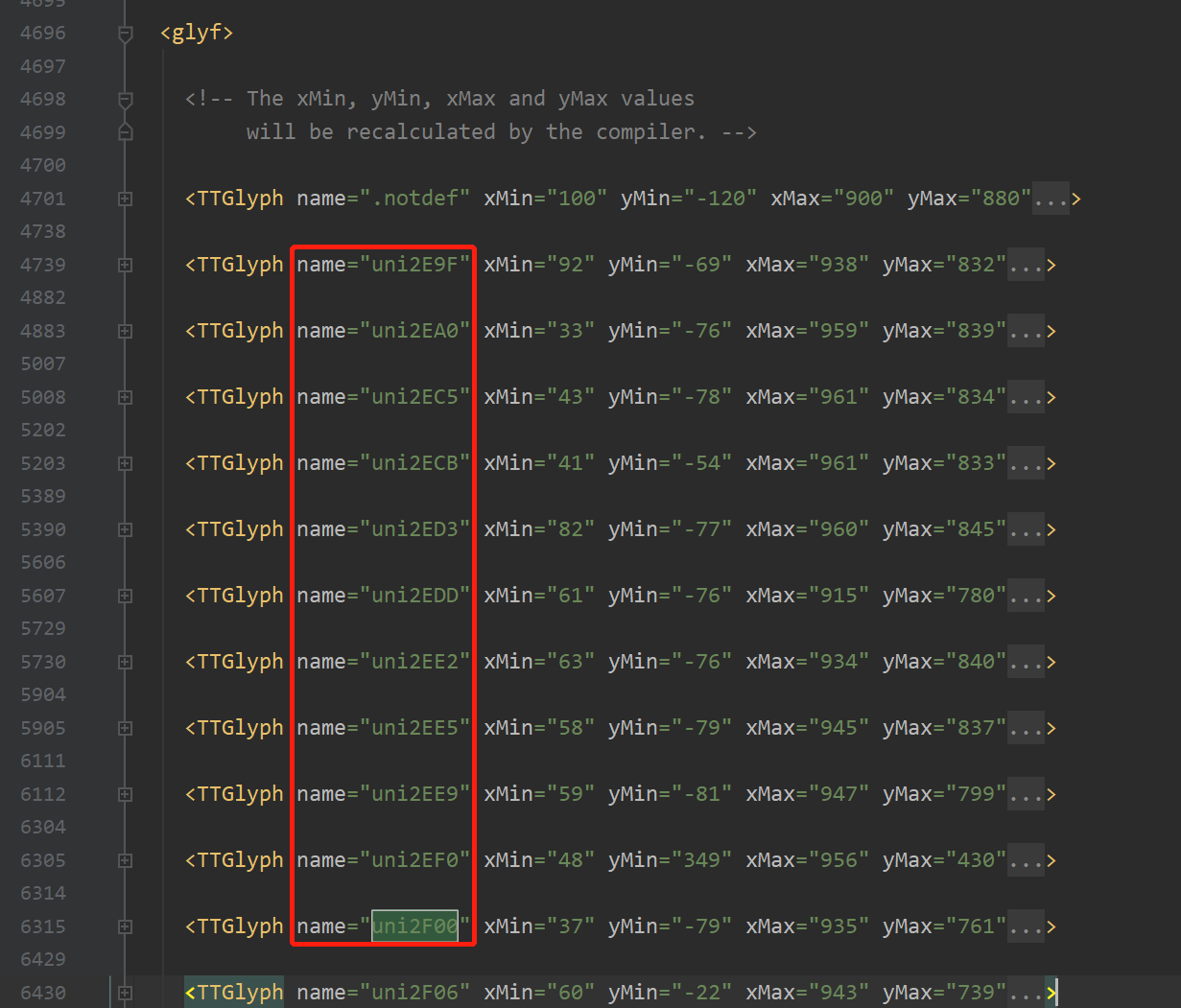

此时就要找 GlyphOrder 中的name
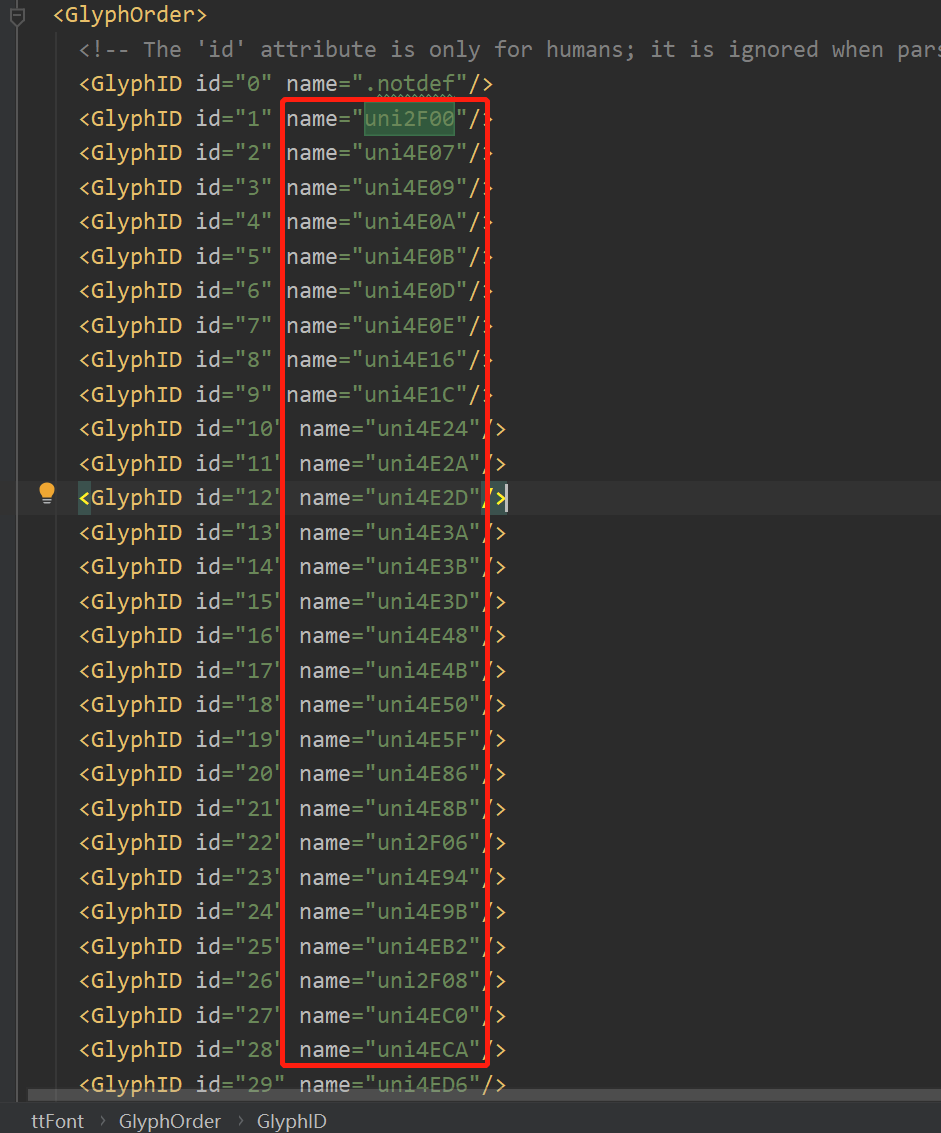
组成 所有汉字和坐标差的映射,和 Unicode和坐标差的映射
# 此汉字列表,需要通过百度字体编辑器(在线)打开ttf/woff文件,或者FontCreator,将全部汉字按照顺序写到列表中 hans_list = ['万', '三', '上', '下', '不', '与', '世', '东', '两', '个', '中', '为', '主', '丽', '么', '之', '乐', '也', '了', '事', '二', '五', '些', '亲', '人', '什', '今', '他', '代', '以', '们', '会', '传', '位', '体', '何', '作', '你', '值', '做', '像', '儿', '元', '光', '入', '全', '公', '关', '内', '写', '冰', '出', '分', '刘', '到', '前', '剧', '力', '动', '十', '千', '却', '原', '去', '友', '发', '变', '古', '只', '可', '吃', '合', '同', '名', '后', '吗', '吴', '员', '和', '四', '回', '因', '国', '图', '圈', '在', '地', '场', '型', '外', '多', '大', '天', '太', '夫', '头', '奇', '女', '她', '好', '如', '妈', '妻', '娱', '婚', '子', '学', '孩', '宝', '实', '家', '对', '将', '小', '少', '就', '山', '岁', '已', '巴', '帅', '年', '底', '度', '开', '张', '当', '影', '很', '得', '心', '性', '怪', '情', '惊', '想', '意', '感', '戏', '成', '我', '房', '手', '打', '拍', '排', '新', '方', '无', '日', '时', '明', '星', '是', '曝', '曾', '最', '月', '有', '服', '本', '机', '李', '来', '杨', '林', '果', '样', '榜', '次', '死', '母', '比', '民', '气', '水', '没', '法', '活', '海', '清', '游', '演', '火', '点', '热', '然', '照', '爱', '片', '物', '特', '狗', '王', '现', '球', '生', '用', '电', '男', '界', '白', '百', '的', '直', '相', '看', '真', '眼', '着', '知', '神', '种', '秘', '称', '穿', '竟', '笑', '第', '粉', '红', '经', '结', '给', '网', '美', '老', '而', '能', '脸', '自', '色', '艺', '花', '英', '行', '衣', '被', '装', '西', '要', '见', '视', '认', '让', '说', '谁', '走', '赵', '起', '超', '路', '身', '车', '过', '还', '这', '造', '道', '遭', '部', '都', '里', '重', '金', '长', '陈', '面', '颖', '颜', '食', '马', '高', '鱼', '黄', '黑', '龙', '一', ] def get_coordinate_hans_and__unicode_coordinate_map(): """ 获取所有汉字和坐标差的映射,和 Unicode和坐标差的映射, 接下来便可以通过映射找到Unicode所对应的坐标差, 拿到坐标差之后,就可以再通过coordinate_hans_map,找到具体的汉字 """ # 存储该hansansjm.xml文件中所有的字符坐标差 coordinate_diff_list = [] # Unicode和坐标差的映射 _unicode_coordinate_map = {} print('>>> 开始计算xml文件中所有字符的坐标差') content = parse('hansansjm.xml') # 此处有个坑,应当先获取GlyphOrder中的GlyphID对应的name即Unicode,这里的Unicode是和ttf文件中一一对应的 # 而glyf中的TTGlyph对应的name(Unicode)不是和ttf文件中一一对应的 # 应该拿到GlyphOrder 下面所有的Unicode编码后,再去 glyf中根据Unicode找对应的坐标 GlyphID_list = content.getElementsByTagName('GlyphID') TTGlyph_list = content.getElementsByTagName('TTGlyph') # 由于xml文件中glyf下面的第一个TTGlyph 所对应的Unicode为.notdef ,要剔除掉,因此TTGlyph_list不能包含第一个元素 # 注意:如果最后一个元素也不是Unicode编码的,应当也要剔除掉 # 获取GlyphID下面所有的Unicode编码 GlyphID_uni_list = [] for GlyphID in GlyphID_list[1:]: # 获取Unicode _unicode = GlyphID.getAttribute('name') GlyphID_uni_list.append(_unicode) for uni in GlyphID_uni_list: for TTGlyph in TTGlyph_list[1:]: if uni == TTGlyph.getAttribute('name'): # 获取第一个contour # print(TTGlyph.getElementsByTagName('contour')[0]) first_contour = TTGlyph.getElementsByTagName('contour')[0] # 获取第一个contour中的前两个pt元素,进一步获取这两个元素的x,y属性,便于计算坐标差 first_pt = first_contour.getElementsByTagName('pt')[0] first_pt_x = int(first_pt.getAttribute('x')) first_pt_y = int(first_pt.getAttribute('y')) # print(first_pt_x, first_pt_y) second_pt = first_contour.getElementsByTagName('pt')[1] second_pt_x = int(second_pt.getAttribute('x')) second_pt_y = int(second_pt.getAttribute('y')) # print(second_pt_x, second_pt_y) # 计算坐标差 coordinate_diff = (second_pt_x - first_pt_x, second_pt_y - first_pt_y) # print(coordinate_diff) coordinate_diff_list.append(coordinate_diff) # break _unicode_coordinate_map[uni] = coordinate_diff # print(coordinate_diff_list) # 将坐标差和汉字组成字典,完成映射 coordinate_hans_map = dict(zip(coordinate_diff_list, hans_list)) print(coordinate_hans_map) print(_unicode_coordinate_map) return coordinate_hans_map, _unicode_coordinate_map
完整代码如下:
import requests from lxml import etree from fontTools.ttLib import TTFont from xml.dom.minidom import parse """ 此案例是破解css反爬 网站:http://www.qiwen007.com 经过查看网站页面源码后发现,tff文字库是 '/hansansjm.ttf',因此判定该网站的文字库不会自动变换 woff/ttf文件样式查看(在线) http://fontstore.baidu.com/static/editor/index.html 也可以使用FontCreator(下载地址) https://www.onlinedown.net/soft/88758.htm """ """ 流程及思路: 1. 通过requests请求获取响应数据,得到的就是源码中加密数据(杂乱的文章) 2. 将加密数据的每一个字符转成Unicode编码,得到字符的Unicode列表 3. 通过搜索源码中font-face关键字,找到字体库文件(ttf/woff文件)将当前域名拼接上/hansansjm.ttf,即 http://www.qiwen007.com/hansansjm.ttf,打开后即下载 4. 使用FontCreator或者百度字体编辑器打开ttf文件,会看到里面每个字符 5. 将ttf转为xml文件 6. 同时使用pycharm打开xml文件,找到 glyf 标签下面的 TTGlyph 标签,里面的name 即是xml文件中的Unicode编码, 里面contour下面的pt的x,y即是每个字符的坐标,计算坐标差(计算坐标差的时候,可以直接取第一个contour的前两组pt即可) (但是 TTGlyph name的顺序 有可能和ttf文件里面的字符的Unicode顺序对应不上,此时就要从GlyphOrder里面看是否对应, 如果对应,就从GlyphOrder中获取每个xml文件中的每个字符的Unicode列表,然后遍历列表,从 glyf 中找到对应的坐标) 7. 手动去组成汉字字符的列表,然后使用映射(dict(zip()))得到汉字和坐标差的映射 8. 在第6步中我们可以获取Unicode和坐标差的映射 9. 然后回到第2步,拿到加密数据的Unicode编码列表后,去Unicode和坐标差的映射中找到对应的坐标差,拿到坐标差后找到对应的汉字 至此,破解过程结束 """ # 此汉字列表,需要通过百度字体编辑器(在线)打开ttf/woff文件,或者FontCreator,将全部汉字按照顺序写到列表中 hans_list = ['万', '三', '上', '下', '不', '与', '世', '东', '两', '个', '中', '为', '主', '丽', '么', '之', '乐', '也', '了', '事', '二', '五', '些', '亲', '人', '什', '今', '他', '代', '以', '们', '会', '传', '位', '体', '何', '作', '你', '值', '做', '像', '儿', '元', '光', '入', '全', '公', '关', '内', '写', '冰', '出', '分', '刘', '到', '前', '剧', '力', '动', '十', '千', '却', '原', '去', '友', '发', '变', '古', '只', '可', '吃', '合', '同', '名', '后', '吗', '吴', '员', '和', '四', '回', '因', '国', '图', '圈', '在', '地', '场', '型', '外', '多', '大', '天', '太', '夫', '头', '奇', '女', '她', '好', '如', '妈', '妻', '娱', '婚', '子', '学', '孩', '宝', '实', '家', '对', '将', '小', '少', '就', '山', '岁', '已', '巴', '帅', '年', '底', '度', '开', '张', '当', '影', '很', '得', '心', '性', '怪', '情', '惊', '想', '意', '感', '戏', '成', '我', '房', '手', '打', '拍', '排', '新', '方', '无', '日', '时', '明', '星', '是', '曝', '曾', '最', '月', '有', '服', '本', '机', '李', '来', '杨', '林', '果', '样', '榜', '次', '死', '母', '比', '民', '气', '水', '没', '法', '活', '海', '清', '游', '演', '火', '点', '热', '然', '照', '爱', '片', '物', '特', '狗', '王', '现', '球', '生', '用', '电', '男', '界', '白', '百', '的', '直', '相', '看', '真', '眼', '着', '知', '神', '种', '秘', '称', '穿', '竟', '笑', '第', '粉', '红', '经', '结', '给', '网', '美', '老', '而', '能', '脸', '自', '色', '艺', '花', '英', '行', '衣', '被', '装', '西', '要', '见', '视', '认', '让', '说', '谁', '走', '赵', '起', '超', '路', '身', '车', '过', '还', '这', '造', '道', '遭', '部', '都', '里', '重', '金', '长', '陈', '面', '颖', '颜', '食', '马', '高', '鱼', '黄', '黑', '龙', '一', ] def get_result_article(): """获取加密文章内容""" url = 'http://www.qiwen007.com/mb-db/pc-sg/zbwz/363609.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36', } resp = requests.get(url=url, headers=headers) html = etree.HTML(resp.text) p_list = html.xpath('//div[@class="article"]/p') for p in p_list: temp_article = p.xpath('./text()') if len(temp_article) > 0: print('temp_article', temp_article) result = to_unicode(temp_article[0]) print('result', result) break def to_unicode(temp_article): """将汉字全部转为Unicode编码""" bytes_article = temp_article.encode(encoding='unicode-escape') str_article_li = str(bytes_article)[2:-1].split('\') uni_article_li = ['uni' + uni[1:].upper() for uni in str_article_li if uni != ''] # print(uni_article_li) return parse_uni(uni_article_li) def parse_uni(uni_article_li): # 获取坐标差汉字映射,和 Unicode 坐标差的映射 get_map = get_coordinate_hans_and__unicode_coordinate_map coordinate_hans_map, _unicode_coordinate_map = get_map() result_article_content = '' for uni in uni_article_li: if uni in list(_unicode_coordinate_map.keys()): coordinate = _unicode_coordinate_map.get(uni) hans = coordinate_hans_map.get(coordinate) # print('1', hans) result_article_content += hans else: hans = chr(int(uni[3:], 16)) # print('2', hans) result_article_content += hans return result_article_content # 将ttf/woff文件转换为xml文件(ttf/woff文件pycharm打开是乱码,xml可以打开) def ttf_to_xml(): font = TTFont('hansansjm.ttf') # 此时就将ttf/woff文件转换为了xml文件 font.saveXML('hansansjm.xml') def get_coordinate_hans_and__unicode_coordinate_map(): """ 获取所有汉字和坐标差的映射,和 Unicode和坐标差的映射, 接下来便可以通过映射找到Unicode所对应的坐标差, 拿到坐标差之后,就可以再通过coordinate_hans_map,找到具体的汉字 """ # 存储该hansansjm.xml文件中所有的字符坐标差 coordinate_diff_list = [] # Unicode和坐标差的映射 _unicode_coordinate_map = {} print('>>> 开始计算xml文件中所有字符的坐标差') content = parse('hansansjm.xml') # 此处有个坑,应当先获取GlyphOrder中的GlyphID对应的name即Unicode,这里的Unicode是和ttf文件中一一对应的 # 而glyf中的TTGlyph对应的name(Unicode)不是和ttf文件中一一对应的 # 应该拿到GlyphOrder 下面所有的Unicode编码后,再去 glyf中根据Unicode找对应的坐标 GlyphID_list = content.getElementsByTagName('GlyphID') TTGlyph_list = content.getElementsByTagName('TTGlyph') # 由于xml文件中glyf下面的第一个TTGlyph 所对应的Unicode为.notdef ,要剔除掉,因此TTGlyph_list不能包含第一个元素 # 注意:如果最后一个元素也不是Unicode编码的,应当也要剔除掉 # 获取GlyphID下面所有的Unicode编码 GlyphID_uni_list = [] for GlyphID in GlyphID_list[1:]: # 获取Unicode _unicode = GlyphID.getAttribute('name') GlyphID_uni_list.append(_unicode) for uni in GlyphID_uni_list: for TTGlyph in TTGlyph_list[1:]: if uni == TTGlyph.getAttribute('name'): # 获取第一个contour # print(TTGlyph.getElementsByTagName('contour')[0]) first_contour = TTGlyph.getElementsByTagName('contour')[0] # 获取第一个contour中的前两个pt元素,进一步获取这两个元素的x,y属性,便于计算坐标差 first_pt = first_contour.getElementsByTagName('pt')[0] first_pt_x = int(first_pt.getAttribute('x')) first_pt_y = int(first_pt.getAttribute('y')) # print(first_pt_x, first_pt_y) second_pt = first_contour.getElementsByTagName('pt')[1] second_pt_x = int(second_pt.getAttribute('x')) second_pt_y = int(second_pt.getAttribute('y')) # print(second_pt_x, second_pt_y) # 计算坐标差 coordinate_diff = (second_pt_x - first_pt_x, second_pt_y - first_pt_y) # print(coordinate_diff) coordinate_diff_list.append(coordinate_diff) # break _unicode_coordinate_map[uni] = coordinate_diff # print(coordinate_diff_list) # 将坐标差和汉字组成字典,完成映射 coordinate_hans_map = dict(zip(coordinate_diff_list, hans_list)) print(coordinate_hans_map) print(_unicode_coordinate_map) return coordinate_hans_map, _unicode_coordinate_map # ttf_to_xml() get_result_article()
最后说明:在我测试的时候,发现最终结果还是有一些问题,通过解密,数据还是和页面上显示的不太一样,个别字符还是不对,搞不懂问题出在哪里,欢迎大佬们指正